虚拟脱衣TryOffDiff:使用SD模型进行高保真服装重建的虚拟试穿比勒费尔德大学 CITEC 机器学习小组提出了一项新颖的任务——虚拟脱衣(Virtual Try-Off, VTOFF),旨在从穿着衣服的单张照片中生成标准化的服装图像。与传统的虚拟试穿(Virtua...图像模型# TryOffDiff# 虚拟脱衣# 虚拟试穿1年前03620
自动T2I生成系统ChatGen:以自由聊天的形式简单描述需求,从而轻松获得高质量的图像尽管文本到图像(T2I)生成模型在近年来取得了显著进展,用户在实际应用中仍然面临着诸多挑战。制作合适的提示、选择适当的模型和配置特定参数等繁琐步骤的复杂性和不确定性,使得用户不得不通过反复试验来获得满...图像模型# ChatGen1年前03320
Stability AI发布适用于Stable Diffusion 3.5 Large的官方ControlNets模型:Blur、Canny和Depth在Black Forest Labs发布了官方FLUX.1 Tools系列开源模型后,Stability AI也不甘落后,于今天发布了三款官方ControlNets模型:Blur、Canny和Dept...图像模型# ControlNets模型# SD3.5# Stability AI1年前03480
多功能大规模扩散模型OneDiffusion:能够无缝支持双向图像合成和理解,跨越多种不同的任务AI2、加州大学欧文分校和华盛顿大学的研究人员介绍了一种名为OneDiffusion的多功能、大规模扩散模型。OneDiffusion能够无缝支持在多样化任务中进行双向图像合成和理解,涵盖从文本、深度...图像模型# OneDiffusion# 扩散模型1年前03350
跨模态图像生成模型Qwen2vl-Flux:将Qwen2VL的视觉语言理解能力与FLUX框架相结合,实现了更精确和上下文感知的图像生成Qwen2vl-Flux 是一种先进的跨模态图像生成模型,它将Qwen2VL的视觉语言理解能力与FLUX框架相结合,实现了更精确和上下文感知的图像生成。该模型在文本提示和视觉参考的基础上生成高质量图像...图像模型# Qwen2vl-Flux# 视觉语言模型1年前03410
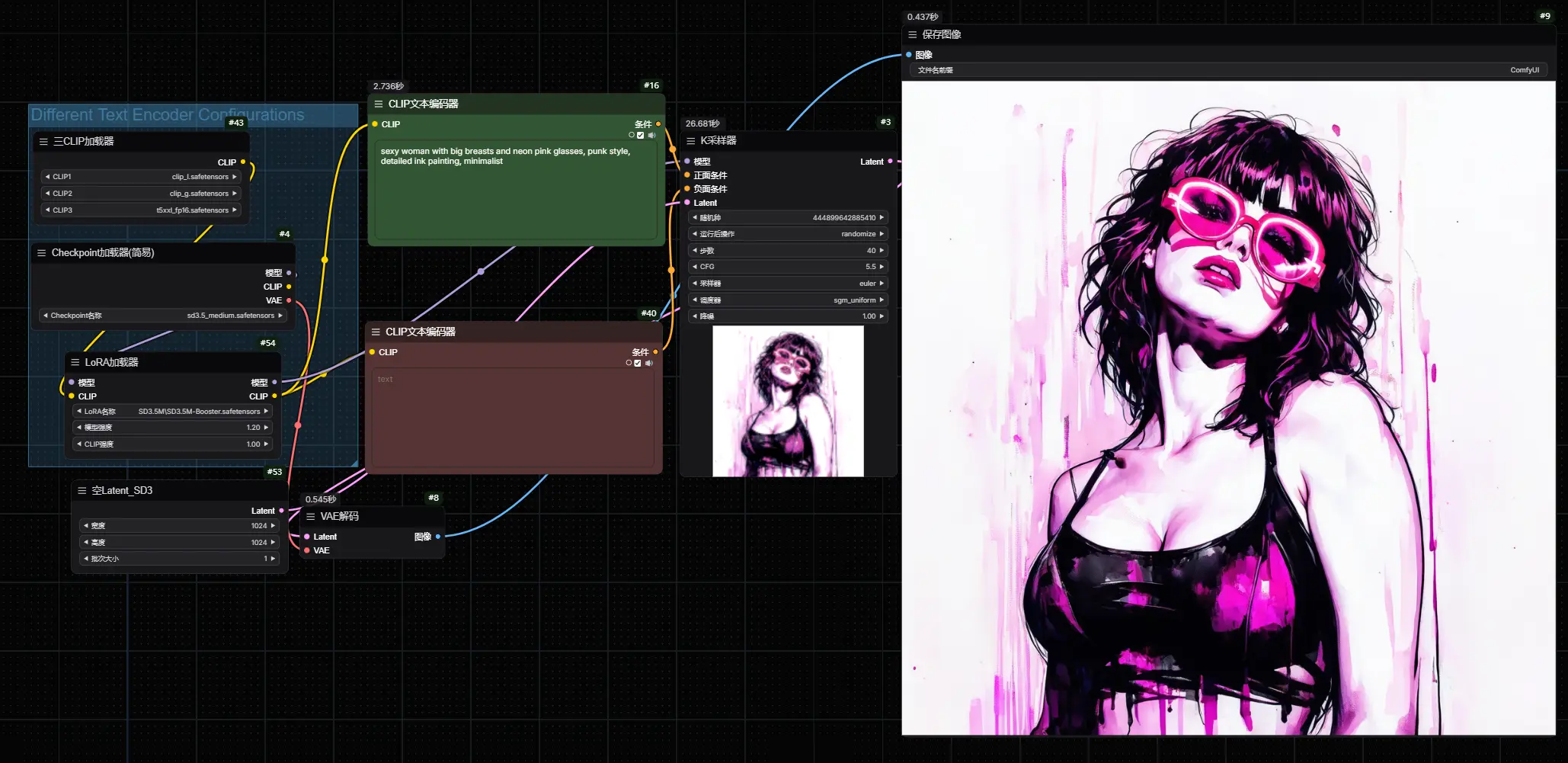
SD3.5M-Booster :专门为 SD3.5 Medium 模型设计的增强 LoRASD3.5M-Booster 是一个专门为 SD3.5 Medium 模型设计的增强 LoRA,旨在将模型的性能提升到最高水平。通过增强细节、颜色和对比度,SD3.5M-Booster 能够显著改善生...图像模型# SD3.5 Medium# SD3.5M-Booster1年前04200
ITF SkinDiffDDS v1:专为处理 DDS 压缩后皮肤漫反射纹理的质量问题而设计的模型ITF SkinDiffDDS v1 是一款专为处理 DDS 压缩后皮肤漫反射纹理的质量问题而设计的模型。这款模型的主要目标是去除压缩过程中产生的条带、块状、抖动、走样、噪点和颜色偏移等瑕疵,从而提升...图像模型# ITF SkinDiffDDS v1# 皮肤1年前03970
基于扩散的肖像动画生成新方法JoyVASA:用于生成音频驱动的面部动画,包括面部动态和头部运动音频驱动的肖像动画在基于扩散模型的推动下取得了显著进展,提高了视频质量和唇同步的准确性。然而,这些模型的复杂性增加导致了训练和推理的低效,以及对视频长度和帧间连续性的限制。为了解决这些问题,京东健康国...图像模型# JoyVASA# 肖像动画1年前06750
背景移除模型BEN:自动从图像中移除背景,生成二值掩码和前景图像BEN(Background Erasure Network)是由Prama LLC推出的一款深度学习模型,旨在自动从图像中移除背景,生成二值掩码和前景图像。 模型:https://huggingfa...图像模型# BEN# 背景移除模型1年前05420
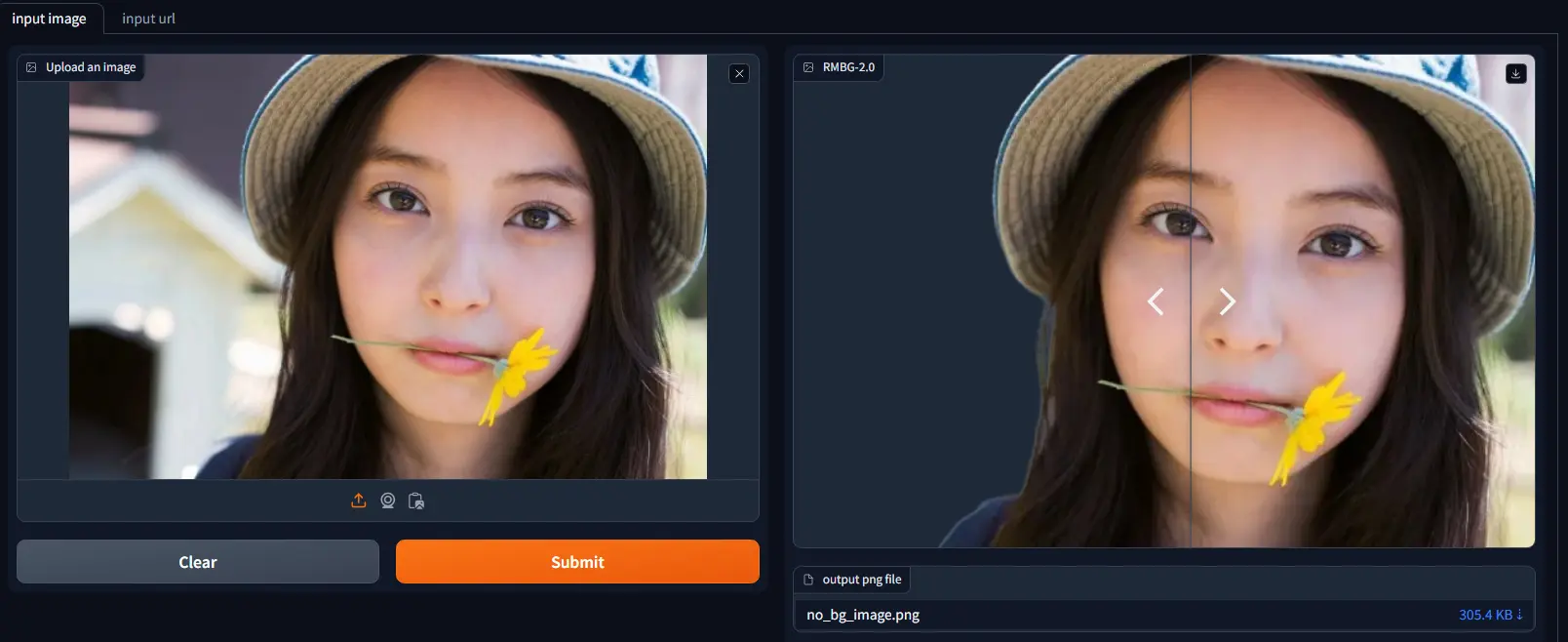
BRIA AI推出最新开源背景移除模型RMBG v2.0RMBG v2.0 是由 BRIA AI 最新研发的先进背景移除模型,能够在各种类别和图像类型中有效地将前景与背景分离。该模型经过精心挑选的数据集训练,包括通用库存图片、电子商务、游戏和广告内容,使其...图像模型# BRIA AI# RMBG v2.0# 背景移除模型1年前04220
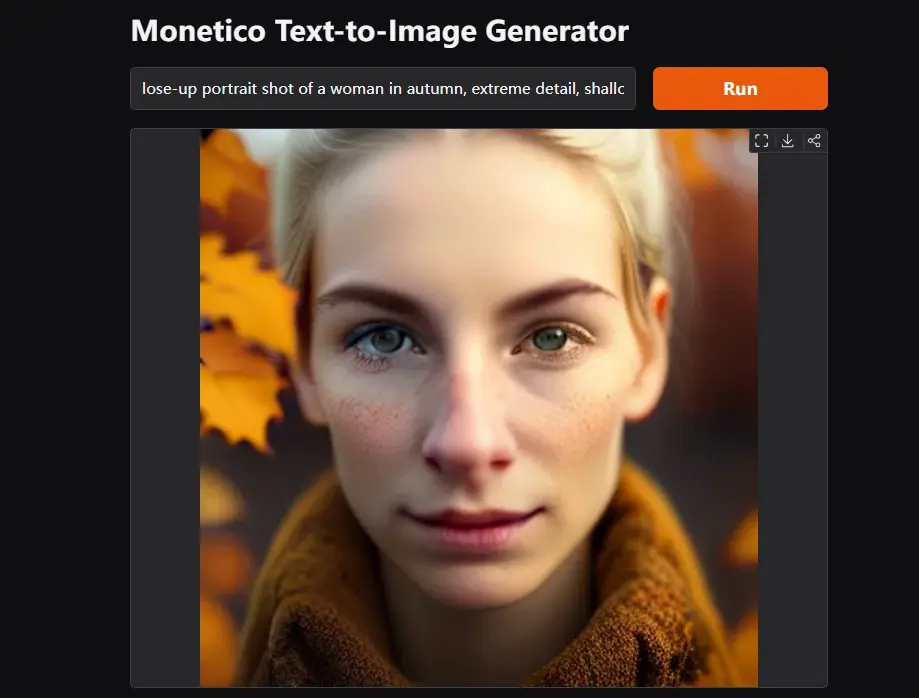
Collov Labs推出非自回归掩码图像建模的文本到图像合成模型MoneticoCollov Labs 最近在8块H100 GPU上训练了一周时间,推出了新的非自回归掩码图像建模的文本到图像合成模型——Monetico。这款模型能够生成高分辨率图像,并且被设计为在消费级显卡上高效...图像模型# Monetico# 文生图模型1年前04850
基于扩散模型(SDXL)的新型图像恢复方法InstantIR盲图像恢复(Blind Image Restoration, BIR)的主要挑战之一是处理测试时未知的退化,这需要模型具备高泛化能力。北京大学、InstantX团队和香港中文大学的研究人员提出了一种新...图像模型# InstantIR# 即时参考图像恢复# 高清修复1年前08990