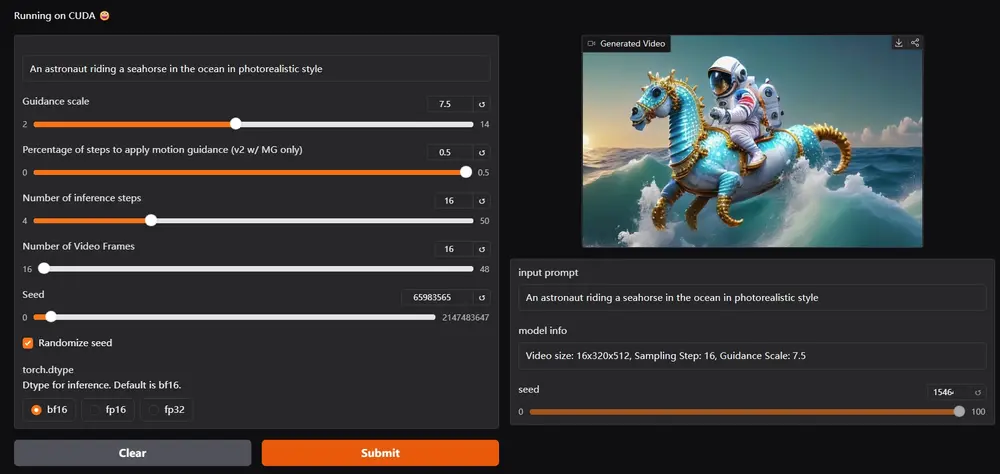
新型视频生成模型T2V-Turbo-v2:基于VideoCrafter2模型提炼,提升视频生成的质量和效率加州大学圣巴巴拉分校、加州大学洛杉矶分校、亚马逊 AGI和滑铁卢大学的研究人员推出新型视频生成模型T2V-Turbo-v2,它旨在提升基于扩散的文本到视频(T2V)生成的质量和效率。简单来说,这项技术...视频模型# T2V-Turbo-v2# 视频生成模型11个月前07600
Rev推出开源自动语音识别模型Reverb和话者分离模型Rev 最近宣布开源其尖端的 Reverb 自动语音识别 (ASR) 和话者分离模型。经过 200,000 小时高质量人工转录的英语语音训练,Reverb 在长篇语音识别领域中表现出色,超越了所有现有...语音模型# Reverb# 话者分离模型# 语音识别模型11个月前07500
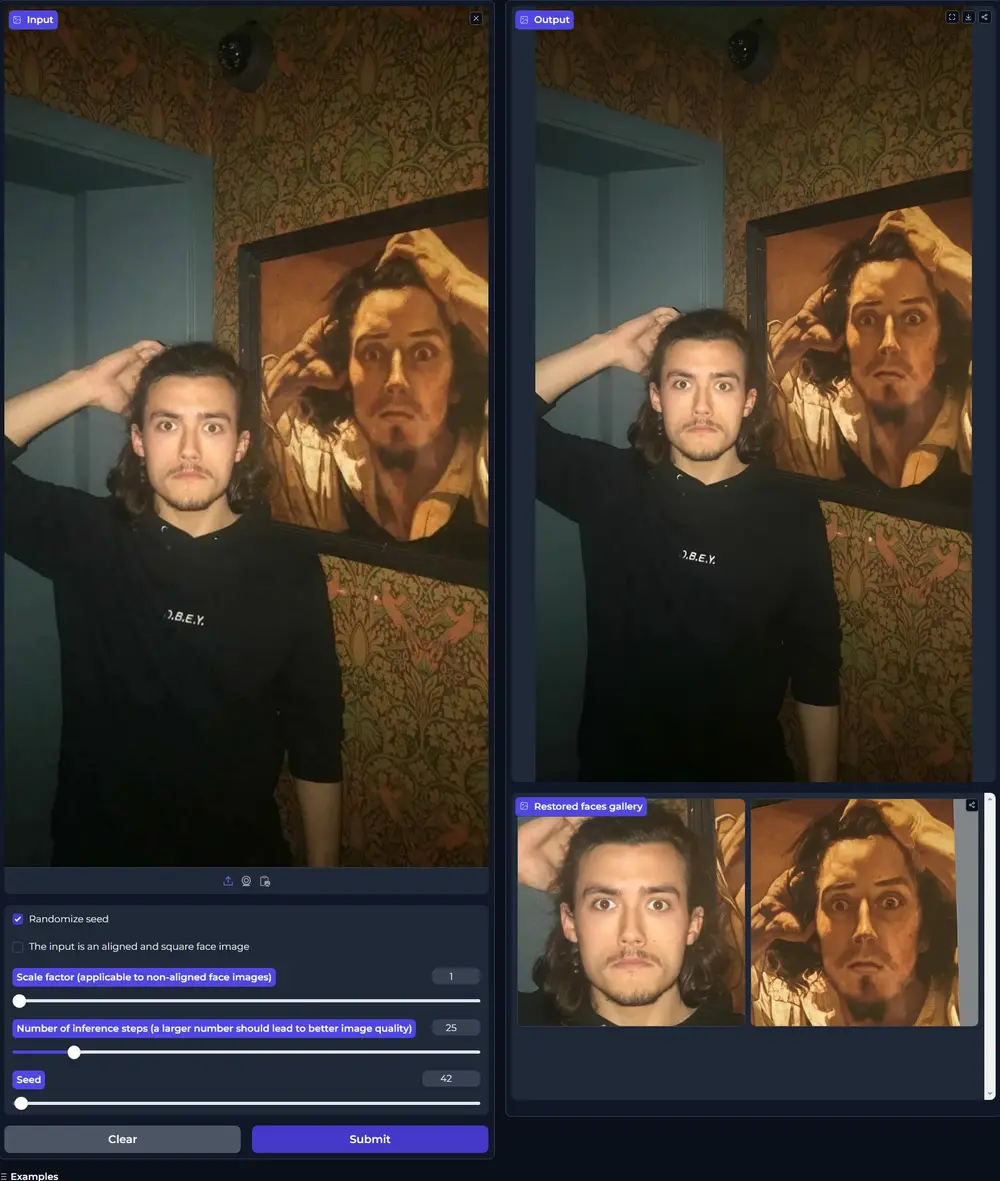
图像恢复算法PMRF:改善从损坏的图像中恢复出高质量、逼真图像以色列理工学院的研究人员推出图像恢复算法PMRF(Posterior-Mean Rectified Flow,后验均值校正流),这个算法的目标是改善从损坏的图像中恢复出高质量、逼真图像的方法。具体来说...图像模型# PMRF# 图像恢复算法11个月前06440
Momo XL:基于SDXL的动漫风格模型Momo XL 是一个基于 Stable Diffusion XL (SDXL) 的动漫风格模型,经过微调后,能够生成具有详细和生动美学的优质动漫风格图像。这款模型专为艺术家和动漫爱好者设计,提供了多...图像模型# Momo XL# SDXL# 动漫风格11个月前04980
高级插图模型Illustrious:专门针对插画和动画任务进行了优化,主要用于生成动漫风格的图像OnomaAI 研究小组推出一个高级插图模型Illustrious,它主要用于生成动漫风格的图像。Illustrious XL是一个基于SDXL的模型,专门针对插画和动画任务进行了优化。它是基于 Ko...图像模型# Illustrious# Illustrious XL# 插图模型11个月前01,2140
大型多模态模型LLaVA-Video:专门设计来处理视频指令并进行视频内容理解字节跳动、南洋理工大学S-Lab和北京邮电大学的研究人员推出大型多模态模型LLaVA-Video,专门设计来处理视频指令并进行视频内容理解。这个模型特别擅长于解析和生成与视频内容相关的语言描述,比如详...多模态模型# LLaVA-Video# 多模态模型11个月前05590
新型开源大型多模态模型LLaVA-Critic:用于评估各种多模态任务的性能字节跳动和马里兰大学帕克分校的研究人员推出新型开源大型多模态模型LLaVA-Critic,它被设计成一个全能的评估者,用于评估各种多模态任务的性能。多模态任务通常涉及理解和生成与图像、视频和文本相关的...多模态模型# LLaVA-Critic# 多模态模型11个月前04420
新型CLIP专家混合模型CLIP-MoE:可以无缝替换CLIP,以即插即用的方式,而无需在下游框架中进一步适应香港中文大学、上海人工智能实验室和舒尔茨大学的研究人员推出新型CLIP模型CLIP-MoE,它是为了增强现有的多模态智能模型CLIP而设计的。CLIP-MoE可以无缝替换CLIP,以即插即用的方式,而...多模态模型# CLIP-MoE# 多模态智能模型11个月前05860
蓝莓真身!Black Forest Labs推出FLUX1.1 [pro]和BFL API,生成质量更高速度更快由Stable Diffusion 原班人马组成的新公司Black Forest Labs于8月份推出全新文生图模型Flux.1系列后,就迅速取代Stability AI成为AI绘画领域最出色的开源公...Flux衍生# Black Forest Labs# FLUX1.1 [pro]11个月前06260
OpenAI 推出更快的语音转录模型Whisper large-v3-turbo,不牺牲质量、速度提升8 倍在10月1日的DevDay活动中,OpenAI宣布了一项重大更新:推出了Whisper large-v3-turbo语音转录模型。这款新模型在保持质量几乎不变的前提下,处理速度比之前的large-v3...语音模型# OpenAI# Whisper large-v3-turbo# 语音转录模型11个月前06790
Golden Haggadah:基于FLUX.1-dev的金色哈加达风格LoRAGolden Haggadah是一款基于FLUX.1-dev,以 14 世纪加西班牙泰罗尼亚金色哈加达风格为基础训练的LoRA模型,适用于生成圣经故事图片。 模型:https://civitai.co...Flux衍生# FLUX.1-dev# Golden Haggadah# Lora11个月前04730
Photorealistic Portrait Prompt Dataset:专为FLUX.1设计的写实肖像提示数据集Photorealistic Portrait Prompt Dataset是专为FLUX.1设计的写实肖像提示数据集,包含精心策划的提示集合。FLUX.1作为先进的文本到图像合成模型,利用复杂提示技...Flux衍生# 写实肖像提示数据集11个月前04450






![蓝莓真身!Black Forest Labs推出FLUX1.1 [pro]和BFL API,生成质量更高速度更快](https://pic.sd114.wiki/wp-content/uploads/2024/10/1727983937-FLUX1-1.webp~tplv-o4t1hxlaqv-image.image)








