基于扩散模型(SDXL)的新型图像恢复方法InstantIR盲图像恢复(Blind Image Restoration, BIR)的主要挑战之一是处理测试时未知的退化,这需要模型具备高泛化能力。北京大学、InstantX团队和香港中文大学的研究人员提出了一种新...图像模型# InstantIR# 即时参考图像恢复# 高清修复1年前08600
SDXL Turbo: 实时文本到图像生成模型Stability AI于北京时间2023年11月28日推出了新的开源文生图模型 SDXL Turbo,SDXL Turbo 是在 SDXL 1.0 的基础上采用新的蒸馏方案,让模型只需要一步就可以生...图像模型# LCM-XL# SDXL Turbo1年前08590
新型超分辨率技术APISR:专门针对动漫图像和视频的高质量增强来自密歇根大学、耶鲁大学和浙江大学推出新型超分辨率技术APISR,专门针对动漫图像和视频的高质量增强。超分辨率技术(Super-Resolution, SR)是一种图像处理技术,旨在从低分辨率的图像中...图像模型# APISR# 动漫图像# 超分辨率技术1年前08520
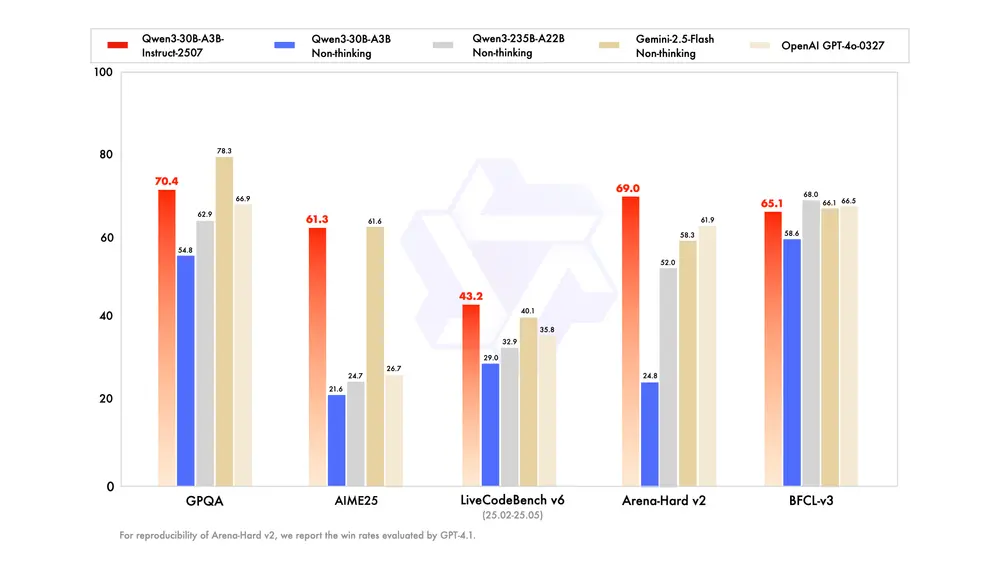
阿里Qwen团队推出 Qwen3-30B-A3B-Instruct-2507:更强、更准、更懂你阿里Qwen团队发布 Qwen3-30B-A3B-Instruct-2507 ——Qwen3 系列中针对非思考模式优化的新一代指令微调模型。 Qwen Chat:https://chat.qwen.a...大语言模型# Qwen3-30B-A3B-Instruct-2507# Qwen团队8个月前08480
高效且多功能的框架Ctrl-Adapter:在各种图像和视频生成模型中加入丰富的控制功能北卡罗来纳大学教堂山分校的研究人员推出高效且多功能的框架CTRL-Adapter,它能够为任何图像或视频扩散模型添加多样的空间控制功能。它支持多种实用的应用,如视频控制、多条件视频控制、稀疏帧条件下的...图像模型# Ctrl-Adapter# 空间控制# 视频生成模型1年前08430
阿里发布Qwen3-LiveTranslate-Flash :全球首个视、听、说全模态实时同传大模型阿里通义实验室今日推出 Qwen3-LiveTranslate-Flash——一款基于 Qwen3-Omni 基座模型打造的多语言实时音视频同声传译大模型。 Demo:https://huggingf...语音模型# Qwen3-LiveTranslate-Flash# 实时同传大模型6个月前08300
Stability AI推出新模型Stable Cascade关键要点摘要: Stable Cascade模型发布: 今天,Stability AI推出了基于Würstchen架构的文生图模型Stable Cascade,并仅允许在非商业许可下使用,限定于非商业...图像模型# Stability AI# Stable Cascade# 模型1年前08270
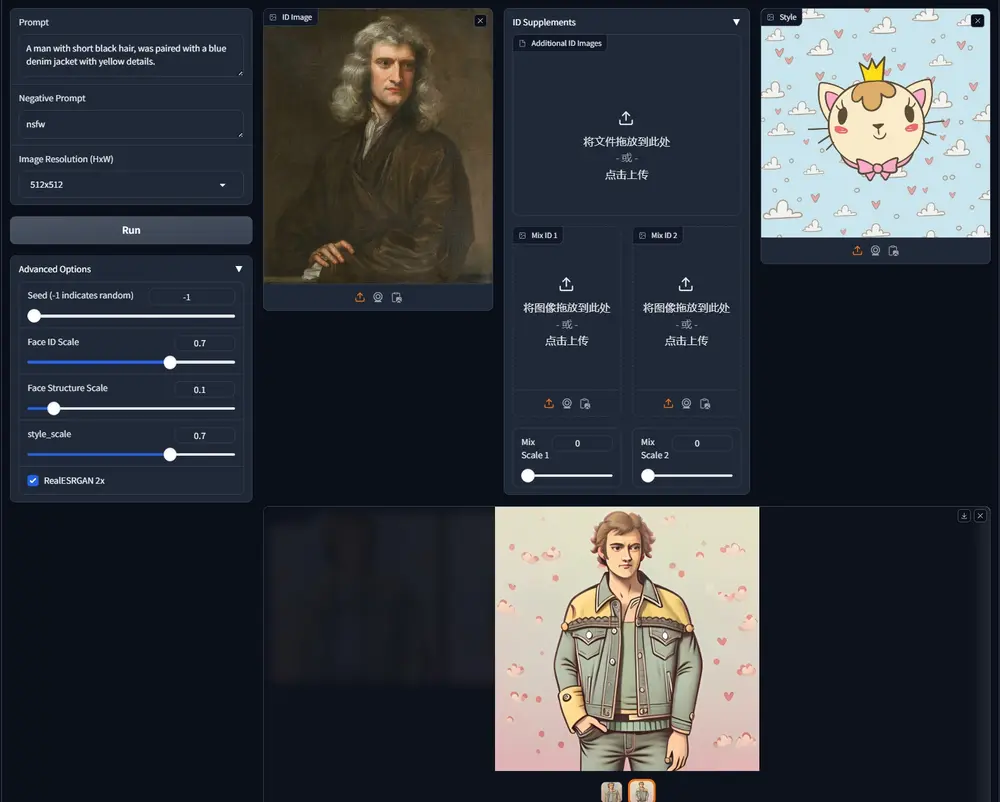
人像个性化框架UniPortrait:支持单人物(Single-ID)和多人物(Multi-ID)图像的定制化生成阿里巴巴集团智能计算研究院推出人像个性化框架UniPortrait,支持单人物(Single-ID)和多人物(Multi-ID)图像的定制化生成。简单来说,UniPortrait能够根据用户提供的文本...图像模型# UniPortrait# 人像个性化1年前08150
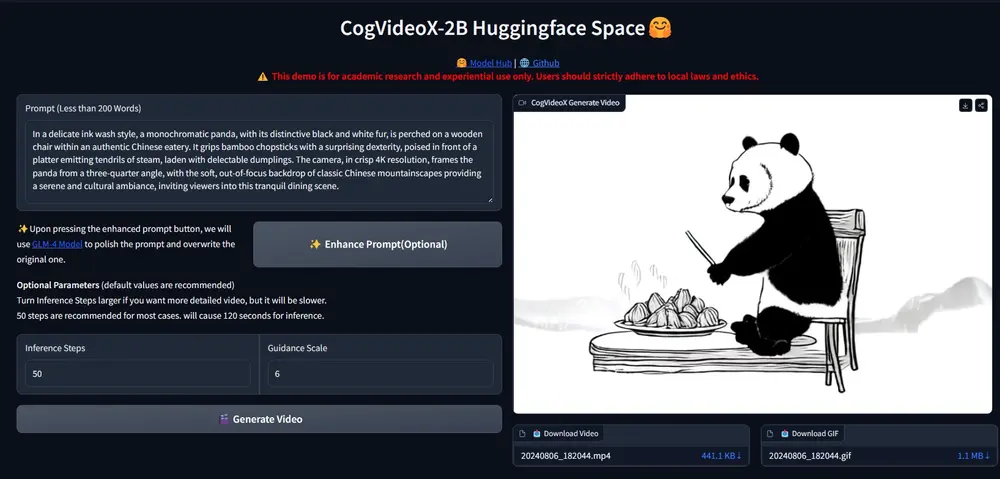
智谱AI推出视频生成模型CogVideoX:与“清影”同源,单张 4090 显卡可推理智谱 AI推出与“清影”同源的视频生成模型 —CogVideoX,CogVideoX模型包含多个不同尺寸大小的模型,目前将开源 CogVideoX-2B,它在 FP-16 精度下的推理需 18GB 显...视频模型# CogVideoX# 智谱AI# 视频生成模型1年前08110
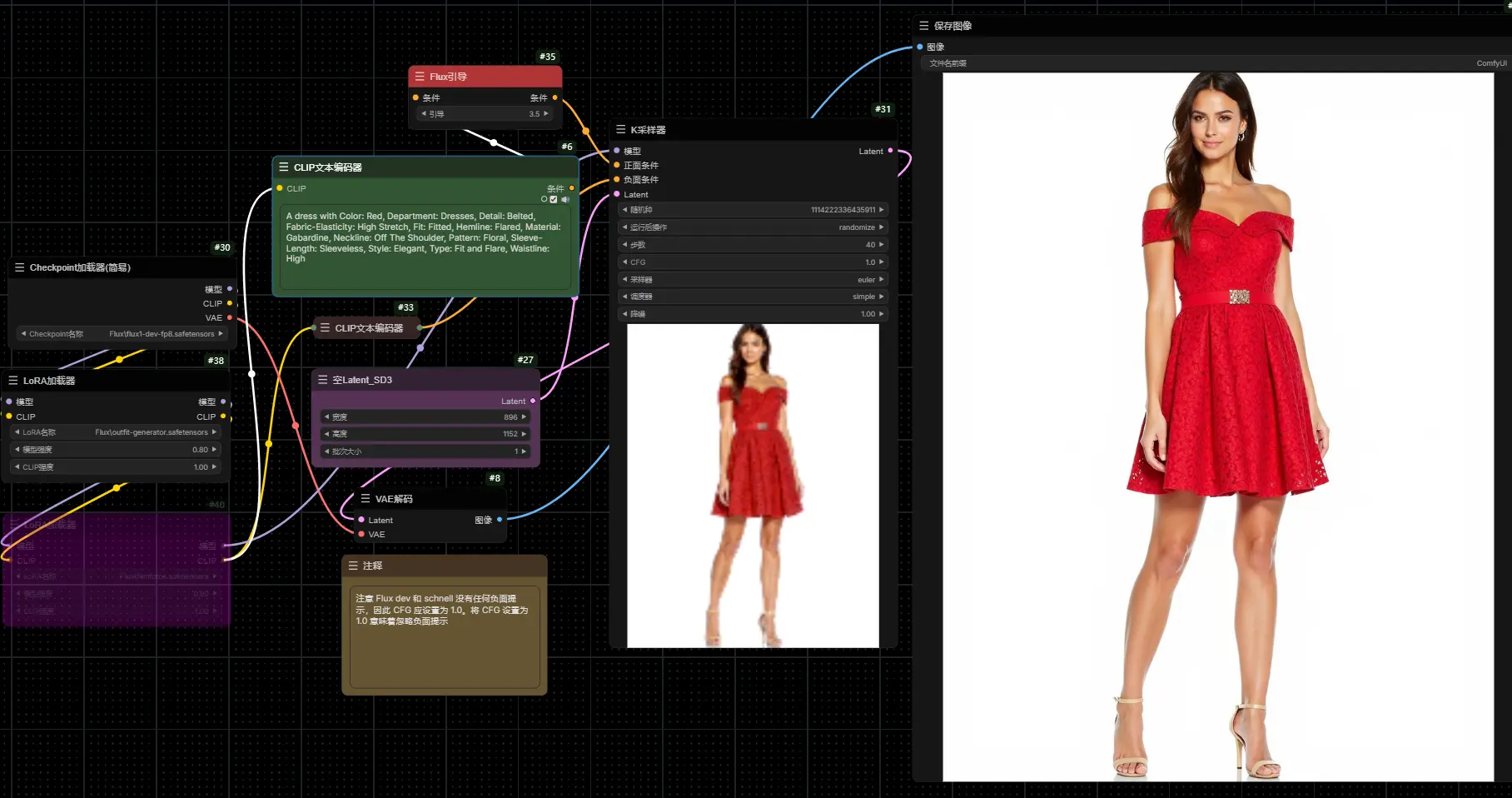
Outfit Generator:基于FLUX.1-dev 的服装LoRAOutfit Generator是一款基于FLUX.1-dev 的服装LoRA,使用H&M服装数据集进行训练,它能够通过提示词生成复杂的服装设计,包括颜色、图案、样式、材料和类型等细节。 模型...Flux衍生# FLUX.1-dev# Outfit Generator# 服装LoRA1年前07980
新型文生图框架SANA:能够高效地生成高达4096×4096分辨率的高清晰度图像英伟达、麻省理工学院和清华大学的研究人员推出新型文本到图像生成框架SANA,它能够高效地生成高达4096×4096分辨率的高清晰度图像。SANA的核心优势在于它不仅生成的图像质量高,而且与文本的匹配度...图像模型# SANA# 文生图框架1年前07940
Rev推出开源自动语音识别模型Reverb和话者分离模型Rev 最近宣布开源其尖端的 Reverb 自动语音识别 (ASR) 和话者分离模型。经过 200,000 小时高质量人工转录的英语语音训练,Reverb 在长篇语音识别领域中表现出色,超越了所有现有...语音模型# Reverb# 话者分离模型# 语音识别模型1年前07910