Inception Labs 发布 Mercury 2:扩散式 LLM 打破自回归瓶颈,推理速度提升 10 倍在大型语言模型(LLM)领域,自回归(Autoregressive)架构长期占据主导地位,但其“逐字生成”的特性已成为高延迟场景的痛点。今日,Inception Labs 正式推出 Mercury 2...大语言模型# Inception Labs# Mercury 2# 扩散式 LLM3周前0360
西班牙“准独角兽”Multiverse 发布免费压缩模型Hypernova-60B-2602:60B 参数仅占 32GB,性能比肩 Mistral Large 3大型语言模型(LLM)虽强,但“大”往往意味着高昂的部署成本和难以逾越的硬件门槛。西班牙巴斯克地区的初创公司 Multiverse Computing 正试图打破这一僵局。 今日,该公司正式发布了 H...大语言模型# Hypernova-60B-2602# Multiverse3周前0660
LoRWeB:AI 图像编辑新范式,只需“看一眼”就能学会任何修图技巧想象这样一个场景:你看到朋友的照片戴着一副酷炫的墨镜,效果极佳。你也想给自己的照片加上同款墨镜,但你既不会使用复杂的 Photoshop,也难以用文字精确描述“想要什么样的墨镜、戴在什么位置、光影如何...图像模型# LoRWeB# 图像编辑3周前0560
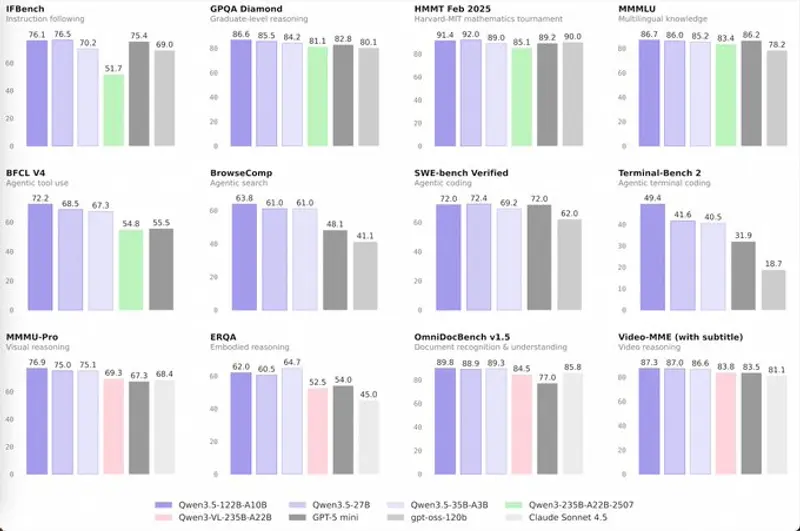
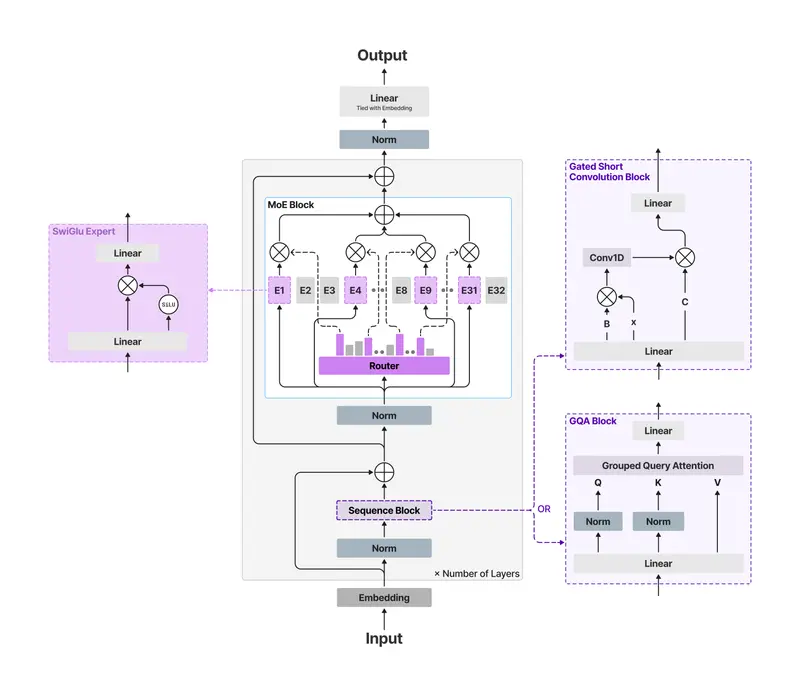
Qwen3.5 中型模型系列重磅开源:35B 越级挑战 235B,架构效率重塑 AI 新标杆在基础大模型的竞赛中,参数规模曾是衡量智能的唯一标尺。但今天,阿里 Qwen 项目组用最新发布的 Qwen3.5 中型模型系列 证明:推动智能进步的,不再仅仅是更大的参数,而是更优的架构、更精的数据和...大语言模型# Qwen3.5-122B-A10B# Qwen3.5-27B# Qwen3.5-35B-A3B3周前0710
LiquidAI 发布 LFM2-24B-A2B:240 亿参数 MoE 模型,仅需 20 亿激活即可在 32GB 内存笔记本上流畅运行大模型是否只能存在于云端集群?LiquidAI 给出了否定的答案。 LiquidAI 正式发布了 LFM2-24B-A2B,这是其 LFM2 家族中规模最大的早期模型。这款稀疏混合专家(MoE)模型拥...大语言模型# LFM2-24B-A2B# LiquidAI3周前06030
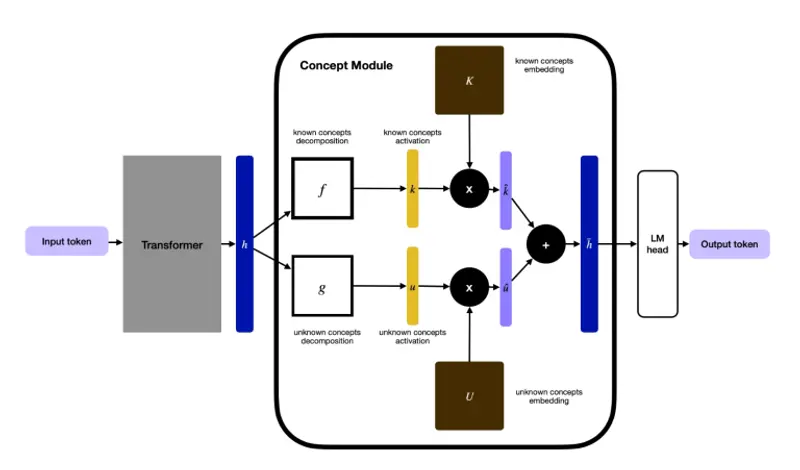
Guide Labs发布Steerling-8B:首个“内在可解释”大模型,让 AI 决策彻底透明化在大模型领域,“黑盒”一直是悬在开发者头顶的达摩克利斯之剑。我们深知模型强大,却往往不知其为何强大,更难以精准控制其行为。 今天,Guide Labs 正式发布了 Steerling-8B——全球首个...大语言模型# Guide Labs# Steerling-8B3周前0200
ZUNA:开源 3.8 亿参数脑电图基础模型,支持去噪、重建与上采样脑电图(EEG)研究长期面临着一个棘手难题:信号噪声大、电极脱落导致数据缺失、以及高密度采集成本高昂。传统处理方法往往依赖复杂的数学插值或手工设计的滤波器,不仅效果有限,还难以适应多变的实际场景。 Z...多模态模型# ZUNA3周前0360
MioCodec v2 发布:仅需 341 bps 即可重建 44.1kHz 高保真音频,TTS 模型无缝升级神器在口语语言建模(Speech Language Modeling)领域,我们长期面临着一个两难选择:是要高压缩率以降低计算成本,还是要高保真度以确保音质清晰?传统的神经音频编解码器往往难以兼得,且常常...语音模型# MioCodec3周前0120
谷歌发布 Gemini 3.1 Pro:专为处理最复杂任务打造的更强智能模型当简单的答案已不足以应对挑战时,我们需要更深层的智能。 上周,谷歌针对科学、研究和工程领域的现代难题,对 Gemini 3 Deep Think 进行了重大更新。今天,谷歌正式发布了支撑这些突破的升级...大语言模型早报# Gemini 3 Deep Think# Gemini 3.1 Pro# 谷歌4周前0270
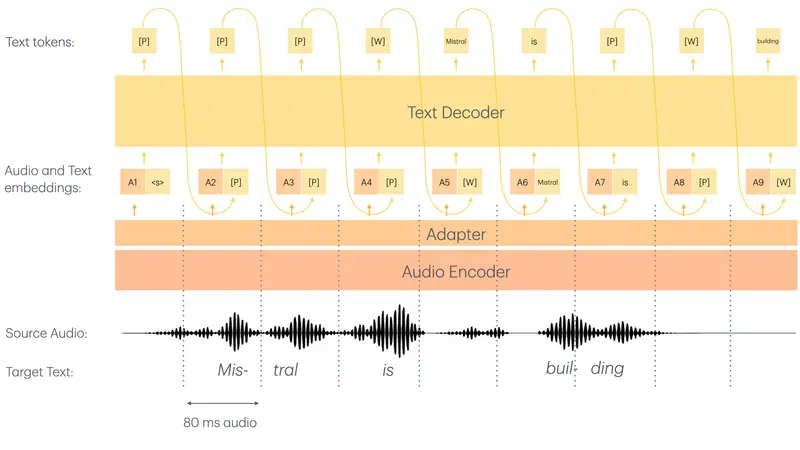
Mistral AI 发布 Voxtral Mini 4B Realtime 2602:40 亿参数开源实时语音模型,延迟低至 500ms 且支持中文在实时语音处理领域,准确性与低延迟往往难以兼得。传统的开源模型(如 Whisper)虽然精度高,但通常需要收集完整音频片段后才能开始转写,导致显著的延迟,无法满足实时字幕或即时语音助手的需求。 模型...语音模型# Mistral AI# Voxtral Mini 4B Realtime 26024周前0230
中国多所高校联合推出 DeepGen 1.0:50 亿参数小模型逆袭,图像生成与编辑能力媲美 800 亿巨无霸在AI领域,“大力出奇迹”似乎已成为一种默认法则:模型参数越大,效果越好。然而,由上海创智学院、复旦大学、中国科学技术大学、上海交通大学、浙江大学、西湖大学、南京大学以及南加州大学的研究人员共同推出的...图像模型# DeepGen 1.0# 多模态模型4周前0550
谷歌发布全新音乐模型 Lyria 3:已集成到Gemini,输入文字或图片,30 秒生成原创音乐谷歌周三正式宣布,其旗舰 AI 助手 Gemini 迎来重大功能升级——集成音乐生成能力。这一新功能由谷歌旗下 DeepMind 团队最新研发的 Lyria 3 模型驱动,目前正处于测试阶段,面向全球...早报语音模型# Lyria 3# 谷歌# 音乐模型4周前0250