阿里重磅发布Qwen-Image-2.0 :支持 1K token 指令生成专业信息图,生图编辑一体化阿里全新推出新一代图像生成基础模型Qwen-Image-2.0,凭借专业文字渲染、细腻真实质感、超强语义遵循、轻量模型架构四大核心特色,实现生图与编辑功能的一体化融合,在文生图和图生图双赛道均展现出优...图像模型# Qwen-Image-2.02个月前0450
Cursor 发布 Composer 1.5:强化学习提升 20 倍,支持复杂代码推理Cursor 团队近日正式推出其智能编程模型 Composer 1.5,作为对前代 Composer 1 的重大升级。新版本聚焦于复杂、多步骤编程任务的处理能力,在推理深度、上下文管理和响应效率上均实...大语言模型# Composer 1.5# Cursor2个月前0610
Linacodec:12.5 令牌/秒的高压缩音频分词器,支持 48kHz 高清语音在 AI 语音模型(TTS/ASR)领域,音频分词器(Audio Tokenizer)的效率直接决定训练速度、推理延迟与生成质量。传统方案如 EnCodec、DAC 虽能压缩音频,但令牌率高、采样率低...语音模型# Linacodec# 音频分词器2个月前0220
Helcyon-Mercury-12B-v3.0:基于 Mistral Nemo 的高情感智能对话模型在本地大模型(Local LLM)生态中,大多数模型追求的是“能回答问题”或“会写代码”。但 Helcyon-Mercury-12B-v3.0 的目标截然不同——它不满足于做一台“聊天机器”,而是试图...大语言模型# Helcyon-Mercury-12B-v3.02个月前0330
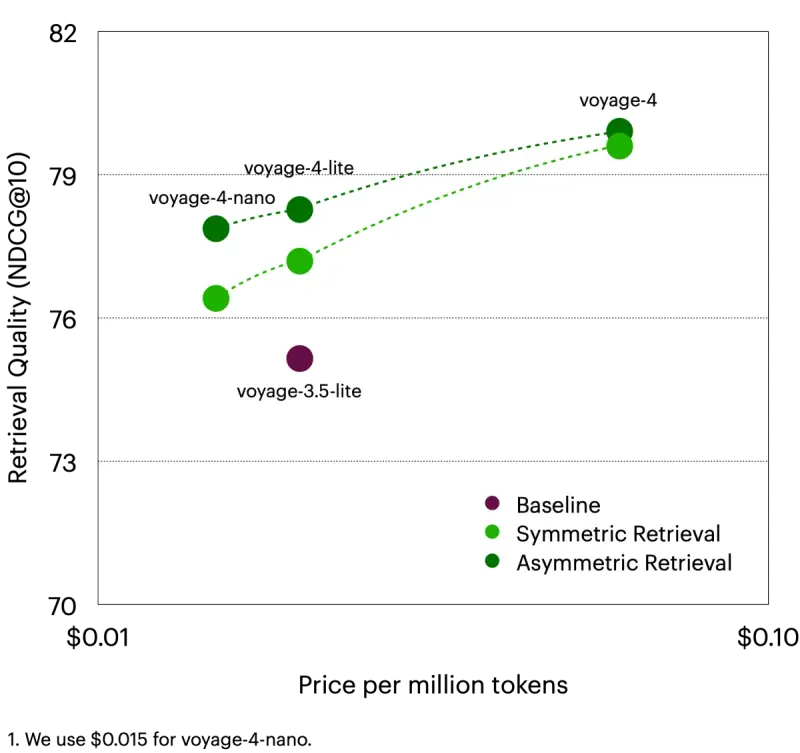
Voyage AI 推出Voyage 4 系列模型:共享嵌入空间 + 专家混合架构,重新定义文本嵌入效率Voyage AI 正式推出 Voyage 4 系列文本嵌入模型,带来两项行业首创技术:统一的共享嵌入空间 与 首个生产级 MoE(专家混合)嵌入模型。这一系列不仅在检索精度上树立新标杆,更通过灵活的...大语言模型# Voyage 4# Voyage AI# voyage-4-nano2个月前0440
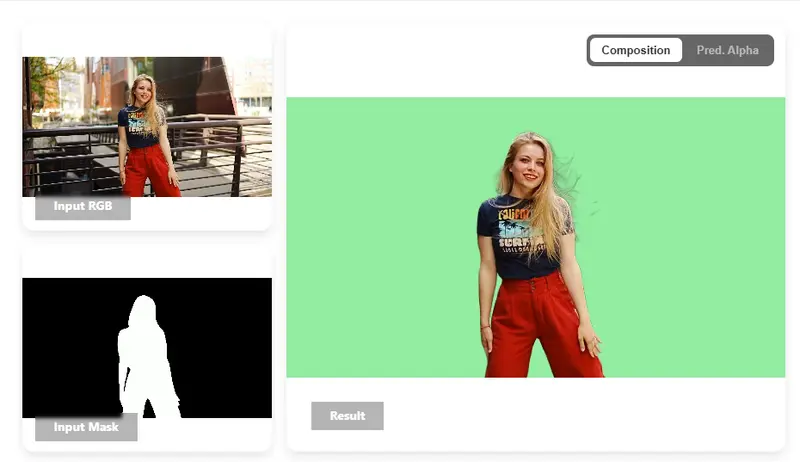
VideoMaMa:基于扩散模型的视频抠图新SOTA,粗糙掩码一键生成高精度Alpha遮罩高丽大学、Adobe Research 与 KAIST AI 联合提出 VideoMaMa(Video Mask-to-Matte Model),一种基于 Stable Video Diffusion...视频模型# VideoMaMa# 视频抠图2个月前0210
速度提升 25%,支持全栈开发!OpenAI发布GPT-5.3-Codex :从代码生成到全场景工程智能体,性能与安全双突破OpenAI 正式推出全新旗舰级编程智能体模型 GPT-5.3-Codex,作为迄今为止最强大的编码智能体,该模型融合 GPT-5.2-Codex 的前沿编码能力与 GPT-5.2 的通用推理、专业领...大语言模型# GPT-5.3-Codex# OpenAI2个月前01380
Claude Opus 4.6正式发布:编程能力跃升,支持百万令牌上下文,办公协同全面升级Anthropic正式推出全新的Claude Opus 4.6大模型,作为其旗舰级智能模型的重磅升级版本,该模型在编程能力、长上下文处理、多任务推理等核心维度实现全面突破,同时首次在Opus系列中开放...大语言模型# Anthropic# Claude Opus 4.62个月前0180
Mistral AI 发布 Voxtral Transcribe 2:开源实时模型 + 高性价比批量转录,全面支持多语言语音应用Mistral AI 推出全新 Voxtral Transcribe 2 系列语音转文本(ASR)模型,包含面向批量离线处理的 Voxtral Mini Transcribe V2 和专为低延迟实时场...语音模型# Mistral AI# Voxtral Mini Transcribe V2# Voxtral Realtime2个月前0480
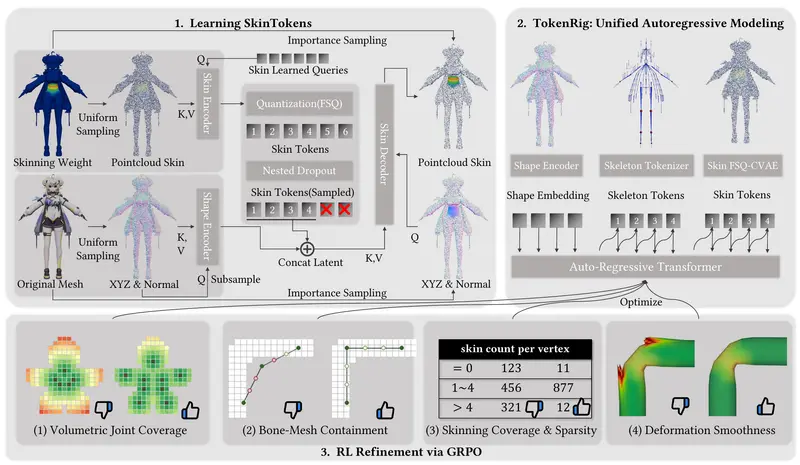
清华大学与 VAST 联合推出 SkinTokens:用离散令牌统一建模 3D 绑定(Rigging)在生成式 3D 模型快速发展的背景下,绑定(Rigging)——即为静态 3D 模型添加骨骼与蒙皮权重以支持动画——已成为自动化流程中的关键瓶颈。现有方法通常将蒙皮(Skinning)视为一个高维、不...3D模型# SkinTokens# VAST# 清华大学2个月前0690
Anima:20亿参数动漫专属文生图模型,ComfyUI原生支持,专注插画艺术创作CircleStone Labs 与 Comfy Org 联合打造的Anima文生图模型正式推出预览版,这款拥有20亿参数(2B)的模型专为动漫艺术打造,聚焦动漫概念、角色与风格创作,同时可生成各类非...图像模型# Anima# ComfyUI# 动漫4周前02870
上海AI实验室发布 Intern-S1-Pro:万亿参数 MoE 多模态科学推理模型上海AI实验室推出 Intern-S1-Pro —— 一款面向科学发现的万亿级混合专家(MoE)多模态大模型。该模型在保持强大通用能力的同时,专为 AI for Science(AI4Science...多模态模型# Intern-S1-Pro# 上海AI实验室# 书生科学多模态大模型2个月前0350