
清华大学研究团队近日推出 SageAttention3,一项聚焦于提升 Transformer 注意力机制效率的新研究成果。该工作在推理阶段引入基于 FP4 的微缩放量化技术,并首次系统性探索了 8 位注意力机制在训练中的可行性,为大模型高效计算提供了新的技术路径。
SageAttention3 特别适配英伟达Blackwell 架构 GPU 的 FP4 Tensor Cores,在长序列任务中实现显著性能提升,同时保持生成质量基本无损。

核心目标:让注意力更轻、更快、更省
注意力机制是现代大模型的核心组件,但其计算复杂度随序列长度呈平方增长(O(n²)),成为长上下文处理的主要瓶颈。
SageAttention3 的设计目标明确:
- 在推理阶段大幅降低延迟与能耗;
- 在训练阶段探索低比特注意力的实用边界;
- 尤其面向视频生成、生物序列分析等超长序列场景。
为此,团队提出了三项关键技术改进。

关键特性
1. FP4 微缩放量化(Microscaling Quantization)
SageAttention3 将注意力计算中的两个关键矩阵乘法(QK⊤ 和 PV)量化至 FP4 精度,同时引入 FP8 缩放因子进行动态范围补偿。
这一“微缩放”策略在 Blackwell GPU 上充分发挥 FP4 Tensor Core 的算力优势,实现在极低比特下维持高精度输出。
2. 双层量化方法(Two-level Quantization)
为缓解 FP4 动态范围有限的问题,SageAttention3 提出分阶段量化方案:
- 先对每个 token 的激活值进行 per-token 归一化,压缩至 [0, 448×6] 区间;
- 再应用 FP4 + FP8 缩放量化。
该方法有效减少异常值干扰,提升了量化稳定性。
3. 首个可训练的 8 位注意力机制(SageBwd)
这是 SageAttention3 最具突破性的尝试之一——首次将注意力前向传播中的 QK⊤ 和 PV 计算全程量化至 INT8,用于训练任务。
反向传播中,关键梯度计算 dOV⊤ 仍保留 FP16,以控制误差累积。实验表明,该方案在微调任务中几乎无损,在预训练中虽收敛稍慢,但仍具备实用性。
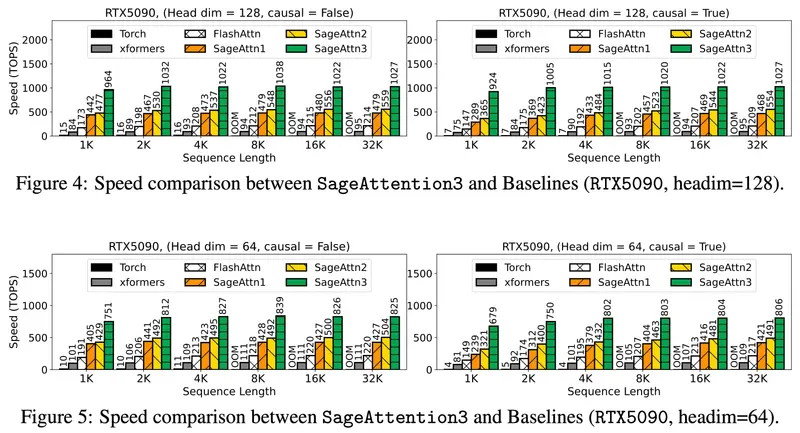
实测表现:推理提速数倍,训练也可加速
推理性能(基于 RTX5090 测试)
| 模型 | 原始时间 | SageAttention3 时间 | 加速比 |
|---|---|---|---|
| CogVideoX | 64 秒 | 27 秒 | ~2.4x |
| HunyuanVideo | 489 秒 | 164 秒 | ~3.0x |
- 在多个 text-to-video 模型(如 Mochi)上,端到端生成质量指标未见明显下降;
- 实现 1038 TOPS 的注意力计算吞吐,相较 FlashAttention 提升约 5 倍。
训练性能(基于 RTX4090 测试)
- SageBwd(8-bit 训练)相比 FlashAttention 加速 1.67 倍;
- 在 Qwen2.5-3B 微调任务中,GSM8K 准确率达 0.607,与 BF16 基线(0.601)相当;
- 在预训练任务中,收敛速度略慢,需进一步优化学习率调度或混合精度策略。
适用场景
SageAttention3 在以下任务中展现显著优势:
- 长文本/长视频生成
如视频字幕、小说续写、多镜头叙事生成,显著缩短响应时间。 - 生物信息学序列建模
处理长达数千氨基酸的蛋白质序列或基因组数据,降低计算门槛。 - 多模态生成模型
支持 Flux、Stable Diffusion 3.5 等图像模型,以及 CogVideoX、HunyuanVideo、Mochi 等视频生成系统。 - 大规模微调任务
利用 8-bit 注意力机制降低显存占用与训练成本,适合资源受限环境部署。
当前局限与使用建议
尽管性能出色,SageAttention3 并非适用于所有模型结构。目前验证效果良好的主要包括:
- 视频生成模型:CogVideoX-2B、HunyuanVideo、Mochi
- 主流图像生成模型:Flux、Stable Diffusion 3.5 等
⚠️ 注意:对于其他视频生成模型,直接全局启用 SageAttention3 可能导致轻微质量损失。
推荐采用混合策略以实现无损加速:
仅在第一个和最后一个时间步使用 SageAttention2++(更高精度),其余中间步骤使用 SageAttention3。
这种组合方式可在保持输出质量的同时,最大化推理效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











