阿联酋MBZUAI、莫斯科物理技术学院、莫斯科AIRI和伦敦数学科学研究所的研究人员推出Beyond Memorization,通过不同的架构和训练方法来提升大语言模型(LLMs)多步推理能力。作者们通过在细胞自动机(Cellular Automata, CA)框架内进行实验,探索了模型在随机布尔函数生成的状态序列上学习和执行多步推理的能力,以排除记忆化的影响。
主要功能
- 规则抽象与推理:模型能够从给定的初始状态和状态序列中抽象出底层的规则,并利用这些规则进行多步推理。
- 动态计算扩展:通过引入循环(recurrence)、记忆(memory)和测试时计算扩展(test-time compute scaling),模型能够在推理过程中动态调整计算深度,以适应不同复杂度的任务。
主要特点
- 1dCA基准测试:作者们提出了一个基于一维细胞自动机(1dCA)的推理基准测试,该测试通过变化推理深度(k值)来评估模型的多步推理能力。
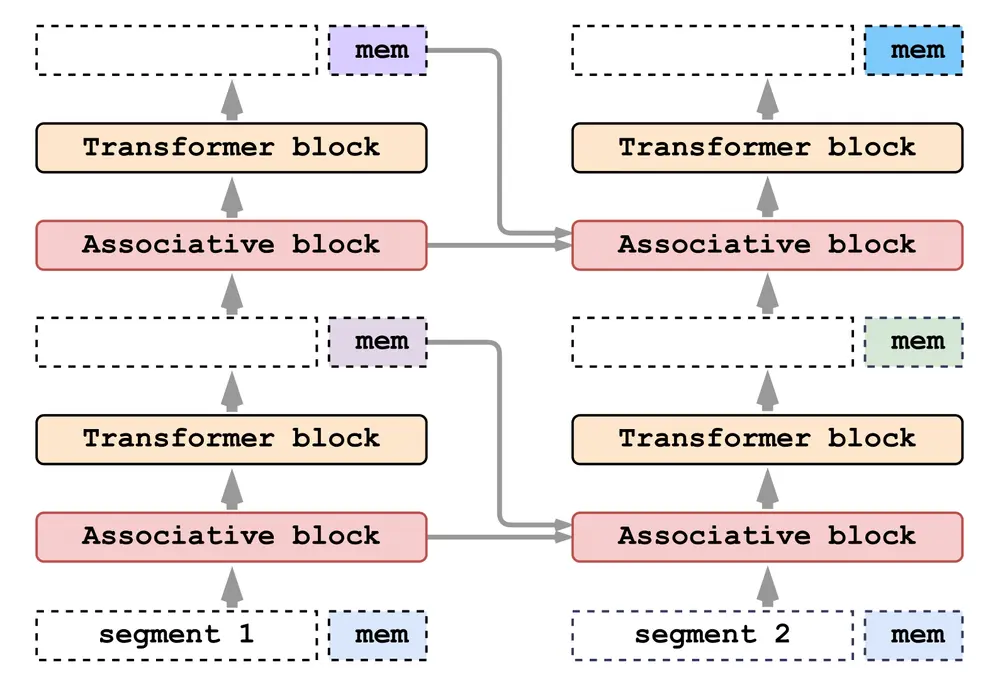
- 架构多样性:研究涵盖了多种神经网络架构,包括Transformer、LSTM、状态空间模型(Mamba)和关联循环记忆Transformer(ARMT)。
- 训练方法多样性:探索了多种训练方法,如监督学习、强化学习(GRPO)和链式思考(Chain-of-Thought, CoT)训练,以提升模型的推理能力。
工作原理
- 细胞自动机(1dCA):1dCA是一个一维的动态系统,其中每个细胞的状态根据局部规则更新。模型需要从给定的状态序列中学习这些局部规则,并用它们来预测未来的状态。
- 推理任务变体:作者设计了四种任务变体(O-S, O-O, O-RS, RO-S),以评估模型在不同条件下的推理能力,包括是否有中间步骤的监督。
- 动态计算时间(ACT):通过允许模型在每个时间步动态决定计算的次数,ACT机制扩展了模型的有效深度,而无需增加模型的参数数量。
测试结果
- 固定深度模型的局限性:4层的Transformer、LSTM和Mamba模型在单步预测(k=1)上表现良好,但在多步推理(k≥2)时性能急剧下降。
- 循环注意力的扩展能力:ARMT通过段级循环注意力扩展了推理能力至k=2,但无法进一步扩展。
- ACT的有效性:在Transformer中加入ACT可以额外获得大约1个有效的推理步骤,而无需增加参数数量。
- 强化学习(GRPO)的效果:通过GRPO训练的模型能够在没有中间监督的情况下达到k=3的推理深度。
- 链式思考(CoT)的优越性:当有中间步骤的监督时,CoT训练方法能够使模型在k=4的推理任务中达到近乎完美的准确率。
应用场景
- 复杂问题解决:在需要多步推理和规则应用的任务中,如数学问题解决、逻辑推理等,该研究的成果可以帮助提升模型的性能。
- 智能系统开发:在开发需要深度推理能力的智能系统时,如自动驾驶、医疗诊断等,这些发现可以指导如何设计和训练更有效的模型。
- 学术研究:为研究大型语言模型的推理机制和能力提供了新的视角和方法,有助于推动人工智能领域的理论研究。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...