
微软宣布,其 Windows ML 平台现已正式进入生产可用状态,面向所有运行 Windows 11 24H2 及以上版本的设备开放。这一进展标志着 Windows 在本地 AI 能力上的关键落地——开发者可以更高效地将 AI 模型集成到桌面应用中,并由系统自动调度至 CPU、显卡 或 NPU 上执行,实现性能与能效的最优平衡。
这不是一个实验性功能,而是一个已经准备好用于商业发布的底层推理框架。
什么是 Windows ML?
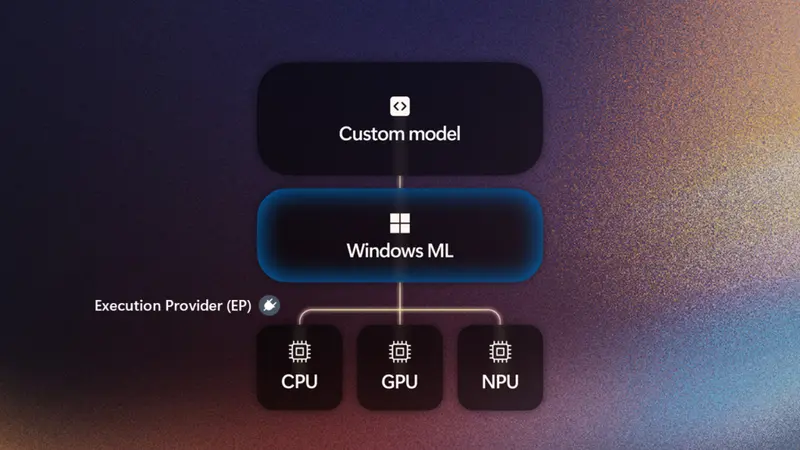
Windows ML 是内置于操作系统的 AI 推理运行时,简化开发者在 Windows 应用中部署机器学习模型的过程。它不负责训练模型,而是专注于“最后一公里”:让训练好的模型在用户设备上快速、安全、低延迟地运行。
核心能力包括:
- 支持 ONNX 格式的模型(主流深度学习通用格式)
- 自动识别硬件并调用最佳计算单元(CPU / GPU / NPU)
- 统一管理底层执行提供程序(Execution Providers, EPs),无需开发者手动打包
- 与 Windows App SDK 深度集成,开箱即用
简单来说,Windows ML 充当了硬件抽象层,让开发者不必关心用户的电脑是搭载英特尔酷睿Ultra、AMD Ryzen AI 还是骁龙X 系列芯片,只需一次开发,即可跨平台运行。
如何工作?系统帮你匹配最合适的核心
AI 工作负载对硬件需求不同:
- 视频语义分析 → 高算力显卡更合适
- 实时语音唤醒 → 低功耗 NPU 更高效
- 多任务调度 → CPU 提供灵活性
Windows ML 的机制是:硅合作伙伴(如 AMD、英特尔、英伟达、高通)为其芯片开发专用的执行提供程序(EP),而微软负责在系统层面分发、注册和管理这些组件。当应用请求运行某个模型时,Windows ML 会自动选择最适合该任务的 EP。
这意味着:
- 开发者无需在应用中捆绑运行时库;
- 用户不会因为多个 AI 应用重复安装相同依赖;
- 应用体积可减少数十甚至上百 MB。
例如,英伟达的 TensorRT for RTX 执行提供程序可在 GeForce RTX 显卡上实现比 DirectML 快 50% 以上的推理速度;高通则通过 QNN EP 充分释放骁龙X 系列 NPU 的能效优势。
实际应用场景已落地
多家软件厂商已在最新版本产品中采用 Windows ML,涵盖创意、安全、图像处理等多个领域:
| 公司 | 应用 | 使用场景 |
|---|---|---|
| Adobe | Premiere Pro / After Effects | 利用 NPU 实现语义搜索、音频标签识别、场景切换检测 |
| Topaz Labs | Topaz Photo | AI 图像增强:去噪、超分、焦点恢复 |
| McAfee | 安全套件 | 本地检测社交网络中的深度伪造内容与诈骗信息 |
| Wondershare | Filmora | 实时预览并应用 AI 驱动的身体特效(如光效环绕) |
| Reincubate | Camo | 借助 NPU 提升直播时的摄像头背景分割质量 |
| Dot Inc. | Dot Vista | 医疗场景下的免手控语音交互与 OCR 识别 |
这些案例表明,Windows ML 正在成为专业级桌面应用构建本地 AI 功能的标准路径之一。
对开发者的实际好处
对于希望在桌面端引入 AI 的团队而言,Windows ML 解决了几个长期痛点:
- 部署复杂度高 → 现在由系统统一管理执行环境
- 应用包体过大 → 不再需要嵌入 ORT 或其他运行时
- 硬件适配困难 → 一套代码覆盖 AMD/英特尔/英伟达/高通平台
- 能耗控制难 → 可指定策略优先使用 NPU 降低功耗
此外,微软提供完整的工具链支持:
- VS Code AI Toolkit:支持从 PyTorch 模型转 ONNX、量化、优化、编译全流程
- AI Dev Gallery:交互式实验空间,可直接测试自定义模型在本地设备上的表现
生态协同:与芯片厂商深度合作
微软强调,Windows ML 的成功离不开与硅伙伴的紧密协作。目前主要支持如下平台:
- AMD:通过 Vitis AI EP 充分利用 Ryzen AI 的 CPU+GPU+NPU 架构
- 英特尔:结合 OpenVINO 技术,在 Core Ultra 处理器上实现跨 XPU 调度
- 英伟达:TensorRT for RTX 提供极致 GPU 推理性能
- 高通:QNN EP 针对 Snapdragon X 系列 NPU 优化能效比
各厂商均表示,这一合作有助于加速生成式 AI 在 PC 端的普及,尤其是在 Copilot+ PC 推出背景下,本地 AI 成为差异化体验的关键。(来源)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











