视频帧插值(VFI)是计算机视觉领域的关键任务——它能根据两个连续帧(过去帧(I_0)、未来帧(I_1))生成中间帧(I_n),让视频播放更流畅、压缩更高效。但现有方法始终面临“两难”:基于图像的扩散模型性能不错,却无法捕捉时序信息;基于视频的扩散模型能提取时序信息,却需要庞大的训练数据和计算成本。
- 项目主页:https://zonglinl.github.io/tlbvfi_page
- GitHub:https://github.com/ZonglinL/TLBVFI
- 模型:https://huggingface.co/ucfzl/TLBVFI
为解决这一问题,中央佛罗里达大学计算机视觉研究中心的研究人员提出了时序感知潜在布朗桥扩散模型(TLB-VFI) 。它通过创新的特征提取模块与扩散机制,既保留了时序信息的准确性,又大幅降低了参数量与训练需求,在高难度场景下实现了性能与效率的双重突破。

核心定位:破解VFI领域的“时序-效率”难题
TLB-VFI的全称是“Temporal-Aware Latent Brownian Bridge Diffusion for Video Frame Interpolation”,其核心价值在于填补“时序信息提取”与“计算效率”之间的 gap:
- 对传统基于图像的扩散模型:补充了“3D小波门控”“时序感知自编码器”等模块,让模型能捕捉帧与帧之间的运动、时间关联,避免生成的中间帧“时空错位”(比如人物动作突然跳变);
- 对传统基于视频的扩散模型:引入“光流引导”和“布朗桥扩散”,在减少9000倍训练数据需求的同时,将参数量降低20倍以上,解决了“大模型难落地”的问题。
简单来说,TLB-VFI既像“精准捕捉运动轨迹的观察者”,又像“高效利用资源的执行者”,能在复杂场景(如快速运动、4K高分辨率视频)中生成更自然的中间帧。
三大核心功能:覆盖从提取到插值的全流程
1. 高效视频帧插值:质量与速度双优
无需牺牲视觉质量即可快速生成中间帧——在生成同等质量帧的前提下,推理速度比传统基于图像的扩散模型(如LDMVFI)快4.3倍,能适配视频实时处理的需求。
2. 深度时空信息提取:捕捉帧间关联
通过两大核心模块提取“空间特征+时间特征”:
- 3D小波特征门控:在像素空间中,用3D小波变换捕捉时间维度的高频信息(如物体快速移动的细节),避免运动模糊;
- 时序感知自编码器:在潜在空间中,通过编码器提取多帧的层级特征,再用解码器通过交叉注意力聚合特征,确保帧与帧之间的时序一致性。
3. 灵活输入适配:不止于三帧
突破传统VFI“仅支持两帧输入生成一帧”的限制,既能处理“两帧输入生成中间帧”的基础场景,也能灵活接收三帧及以上输入,进一步提升多帧连续插值的效率(如视频批量增强时减少重复计算)。
三大关键特点:为什么TLB-VFI更适配落地?
1. 全链路时序感知:避免“时空错位”
区别于传统模型仅在单一环节处理时序信息,TLB-VFI在像素空间(3D小波提取时间高频信息)和潜在空间(自编码器聚合时序特征)双链路捕捉时间关联,生成的中间帧不会出现“人物手位跳变”“物体位置偏移”等问题,视觉连贯性更强。
2. 极致效率优化:小参量+快推理
- 参数量:比基于视频的扩散模型减少20倍以上,部署时对硬件资源要求更低;
- 推理速度:在相同采样步数下,比Consec.BB快2.3倍,比LDMVFI快4.3倍,可适配边缘设备(如嵌入式视频处理模块);
- 训练成本:引入光流引导后,训练数据需求减少9000倍,无需大规模数据集即可达到高性能。
3. 强场景适应性:应对高难度挑战
在大运动场景(如奔跑的人物、快速行驶的车辆)、高分辨率场景(4K视频)中表现稳定——传统模型在这类场景下易出现“模糊重影”,而TLB-VFI通过精准的时序信息提取,能生成清晰、自然的中间帧。
工作原理:四步实现“时序提取-扩散生成”
TLB-VFI的能力源于“特征提取+扩散模型”的协同设计,核心分为四个关键步骤:
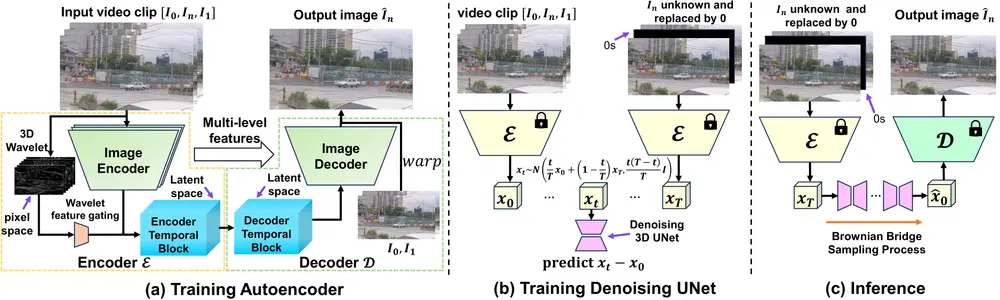
步骤1:自编码器训练——打牢特征基础
- 结构:包含“图像编码器”和“图像解码器”,前者负责将输入帧转化为多层级潜在特征,后者负责将特征重建为图像;
- 关键机制:解码器通过交叉注意力聚合多帧的特征,确保不同帧的空间、时间信息能有效融合,为后续时序一致性打下基础。
步骤2:3D小波特征门控——捕捉像素级时序
在像素空间中,通过3D小波变换分解视频帧的“时间维度高频信息”(如相邻帧间物体的位移、形变),再通过门控机制筛选关键信息——这些信息是判断“运动轨迹是否连贯”的核心,能避免生成的中间帧出现运动模糊。
步骤3:布朗桥扩散模型——潜在空间补全时序
将编码后的潜在特征输入布朗桥扩散模型:
- 核心作用:在潜在空间中“补全”两帧之间丢失的时间信息,通过扩散过程对齐特征分布,确保中间帧的时序逻辑符合真实运动规律;
- 优势:相比传统扩散模型,布朗桥机制能更高效地收敛,减少采样步数,提升推理速度。
步骤4:推理生成——从特征到中间帧
推理时,输入帧先经编码器转化为潜在特征,再通过布朗桥扩散模型补全时序信息,最后由解码器将优化后的特征重建为中间帧——整个过程端到端完成,无需人工干预。
实测表现:高难度场景下性能领先
1. 量化指标:FID/FloLPIPS平均提升20%
在SNU-FILM extreme(大运动场景)、Xiph-4K(4K高分辨率场景)等最具挑战性的数据集上,TLB-VFI与当前SOTA( state-of-the-art,最先进)方法相比:
- FID(帧相似度指标,越低越好)平均下降20%;
- FloLPIPS(感知质量指标,越低越好)平均下降20%,意味着生成帧与真实帧的视觉差距更小。
2. 效率指标:推理速度最高快4.3倍
在相同硬件与采样步数下:
- 比Consec.BB(基于图像的扩散模型)推理速度快2.3倍;
- 比LDMVFI(主流VFI模型)推理速度快4.3倍,且参数量更少,硬件适配性更强。
3. 定性表现:大运动场景更清晰
在人物快速奔跑、车辆急转等大运动场景中,传统模型生成的中间帧易出现“重影”“边缘模糊”,而TLB-VFI生成的帧能清晰还原运动轨迹,视觉上更接近真实拍摄的帧。
应用场景:从技术落地到内容创作
1. 视频压缩:减体积不丢质量
传统视频压缩会通过“减少帧数”降低文件大小,易导致播放卡顿;TLB-VFI可在解压时动态生成中间帧,既能让原始视频帧数减少(压缩后体积变小),又能通过插值恢复流畅度,兼顾“小体积”与“高流畅”。
2. 视频增强:提升旧视频流畅度
对低帧率的旧视频(如早期监控录像、老电影),可通过TLB-VFI插入中间帧,将30帧/秒提升至60帧/秒,播放时更顺滑,视觉体验显著提升。
3. 内容创作:降低视频编辑成本
在短视频剪辑、动画制作中,创作者无需手动调整“帧过渡”——TLB-VFI可自动生成平滑的中间帧,比如让“人物抬手”的动作从“2帧跳变”变为“3帧连贯过渡”,减少后期调整时间,提升创作效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...