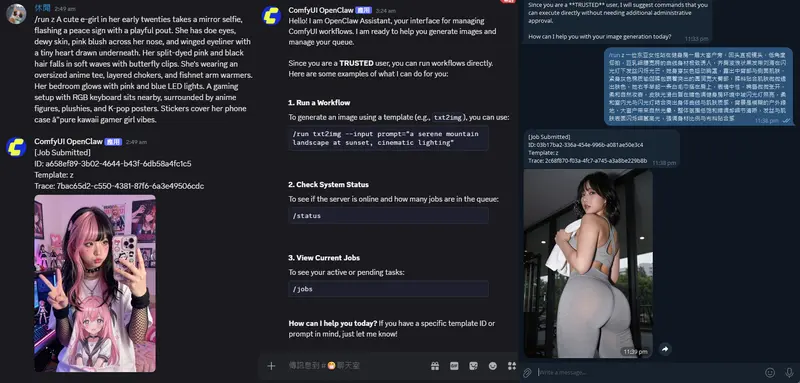
清华大学、智谱AI和中国科学院大学的研究人员推出一个名为 COMPUTERRL 的框架,通过强化学习(Reinforcement Learning, RL)提升计算机桌面智能代理(agents)的操作能力,使其能够熟练地在复杂的数字工作空间中执行任务。
COMPUTERRL 是一个为自动化桌面任务设计的框架,它通过结合程序化的 API 调用和直接的 GUI 交互来解决机器代理与人类中心的桌面环境之间的固有不匹配问题。
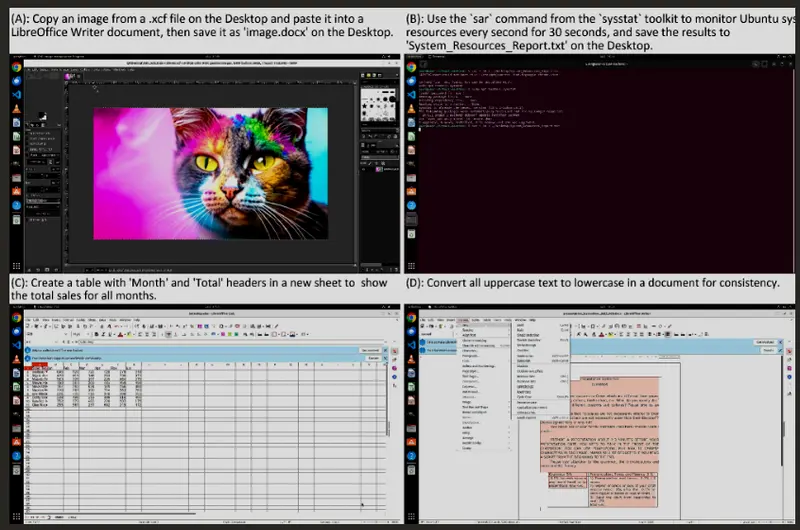
例如,它可以在 LibreOffice Calc 中创建一个带有“月份”和“总计”标题的新表格,以显示所有月份的总销售额,或者在文档中将所有大写文本转换为小写,以保持文本的一致性。
主要功能
- API-GUI 范式:COMPUTERRL 通过结合 API 调用和 GUI 操作,提供了一种更高效的设备交互方式。例如,它可以通过 API 调用来快速完成表格的创建,同时利用 GUI 操作来处理复杂的文档格式化任务。
- 可扩展的 RL 基础设施:该框架支持数千个并行虚拟桌面环境,加速大规模在线 RL 训练。这使得代理能够在不同的桌面任务中进行广泛的训练,从而提高其泛化能力。
- Entropulse 训练策略:通过交替进行强化学习和监督微调,有效缓解了长时间训练中的熵崩溃问题,提高了学习效率和最终性能。
主要特点
- 高效的数据收集和训练:通过自动化 API 构建和大规模并行环境,COMPUTERRL 能够高效地收集训练数据,并在数千个虚拟桌面环境中进行训练。
- 创新的训练方法:Entropulse 方法通过在 RL 训练中引入监督微调阶段,恢复了模型的探索能力,从而实现了持续的性能提升。
- 强大的泛化能力:COMPUTERRL 在 OSWorld 基准测试中表现出色,特别是在多应用程序设置中,展示了其在复杂任务中的长距离规划和推理能力。
工作原理
COMPUTERRL 的工作原理基于以下核心组件:
- API-GUI 范式:通过结合 API 调用和 GUI 操作,代理能够以更高效的方式与桌面环境交互。
- 分布式训练基础设施:利用 Docker 和 gRPC 协议构建的虚拟机集群,支持数千个并行环境,确保训练的高可扩展性。
- Entropulse 训练策略:通过交替进行 RL 和监督微调,该策略在训练过程中维持了模型的探索能力,从而实现了持续的性能提升。
测试结果
在 OSWorld 基准测试中,基于 GLM-4-9B-0414 的 AUTOGLM-OS 实现了 48.1% 的准确率,比其他最先进的模型(如 OpenAI CUA o3 和 UI-TARS-1.5)有显著提升。这表明 COMPUTERRL 在桌面自动化任务中具有显著的优势,尤其是在需要复杂推理和长距离规划的任务中。
应用场景
COMPUTERRL 的应用场景非常广泛,包括但不限于:
- 自动化办公任务:例如,自动创建和编辑文档、表格和演示文稿。
- 系统监控和维护:例如,自动生成系统资源使用报告。
- 多应用程序协调:例如,在多个应用程序之间协调操作,完成复杂的任务。
- 智能助手:为用户提供个性化的桌面自动化解决方案,提高工作效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...