在机器学习领域,生成模型(如 DALL・E 生成图像、ChatGPT 生成文本)、表示学习(如 CLIP 实现图文表示匹配)、分类模型(如 ResNet 进行图像分类)是三大核心方向,且各自都已取得成熟进展。但长期以来,这三类任务始终依赖独立的技术方案与训练目标—— 生成模型专注于 “如何输出逼真内容”,表示学习聚焦 “如何提取数据特征”,分类模型则致力于 “如何判断数据类别”,三者间缺乏有效协同,难以实现 “一份模型同时胜任多任务” 的高效应用。
这种 “任务割裂” 不仅违背了 “奥卡姆剃刀原理”(更简单的框架往往更优),还浪费了任务间的潜在协同价值 —— 毕竟三类任务的本质都是 “从数据中提取模式”,若能通过统一框架整合,或许能让任务间相互赋能。
- 项目主页:https://zinanlin.me/blogs/latent_zoning_networks.html
- GitHub:https://github.com/microsoft/latent-zoning-networks
- 模型:https://huggingface.co/microsoft/latent-zoning-networks
针对这一痛点,微软、清华大学与三星的研究团队在 NeurIPS 2025 论文中提出了潜在分区网络(Latent Zoning Network,简称 LZN)。它通过构建 “共享高斯潜在空间”,将生成、表示学习、分类三类任务自然融入同一框架,且在早期实验中表现亮眼:图像生成质量超越主流扩散模型,无监督表示学习效果优于 MoCo、SimCLR,分类准确率在 CIFAR-10 上达到竞争力水平 —— 所有成果均由单一模型实现,为机器学习任务的 “大一统” 提供了全新思路。
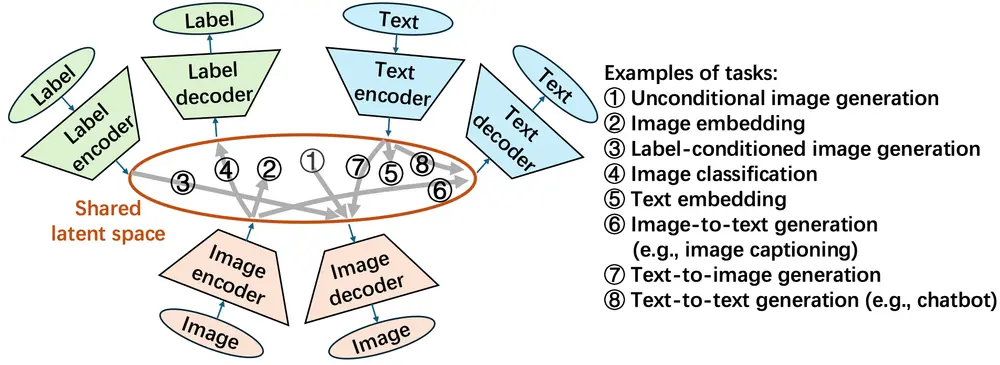
LZN 的核心思想:用 “共享潜在空间” 连接所有任务
LZN 的本质是搭建一个 “通用数据转换平台”,让不同类型数据(图像、标签、文本)、不同任务需求,都能通过这个平台实现高效衔接。其核心设计可概括为 “一个空间 + 两类组件”。
1. 一个共享高斯潜在空间:任务协同的 “中间枢纽”
LZN 构建了一个遵循标准高斯分布的潜在空间,这个空间是所有任务的 “通用语言”:
- 无论是图像、标签还是文本,都需先通过 “编码器” 映射到这个潜在空间,转化为统一格式的 “潜在向量”;
- 后续的生成、分类等任务,本质是对 “潜在向量” 的处理与反向转换;
- 例如,生成图像时,从高斯分布中直接采样潜在向量,再通过 “图像解码器” 转换为图像;分类时,先将图像通过 “图像编码器” 转为潜在向量,再通过 “标签解码器” 输出类别结果。
高斯分布的选择并非随意:一方面,高斯分布易于采样,能直接满足生成任务 “随机生成潜在向量” 的需求;另一方面,其连续平滑的特性,便于不同类型数据的潜在向量实现 “对齐”—— 比如 “狗的图像” 与 “狗的标签文本” 的潜在向量,能在空间中处于相近区域,为跨任务协同奠定基础。
2. 多组编码器 - 解码器:数据与任务的 “转换接口”
为让不同类型数据能接入共享潜在空间,LZN 为每种数据类型(图像、标签、文本)配备了专属的 “编码器” 与 “解码器”:
- 编码器:负责 “数据→潜在向量” 的转换,比如图像编码器将像素信息转为潜在向量,标签编码器将类别标签(如 “猫”“狗”)转为潜在向量;
- 解码器:负责 “潜在向量→数据” 的反向转换,比如图像解码器将潜在向量还原为图像,标签解码器将潜在向量输出为类别结果。
通过不同 “编码器 - 解码器” 的组合,就能实现不同任务:
| 任务类型 | 实现逻辑 | 示例 |
|---|---|---|
| 无条件图像生成 | 高斯分布采样→图像解码器 | 随机生成一张猫的图像 |
| 条件图像生成 | 标签→标签编码器→图像解码器 | 输入 “狗” 标签,生成指定品种的狗图像 |
| 图像分类 | 图像→图像编码器→标签解码器 | 输入一张汽车图像,输出 “轿车” 类别 |
| 图像表示学习 | 图像→图像编码器(输出潜在向量作为特征) | 提取图像特征用于后续检索任务 |
LZN 的技术突破:解决传统方法的 “协同难题”
传统方法之所以无法统一三类任务,核心在于难以同时满足 “生成性”(支持生成任务的采样需求)与 “统一性”(不同数据类型的潜在向量对齐)。LZN 通过创新设计,突破了这一局限。
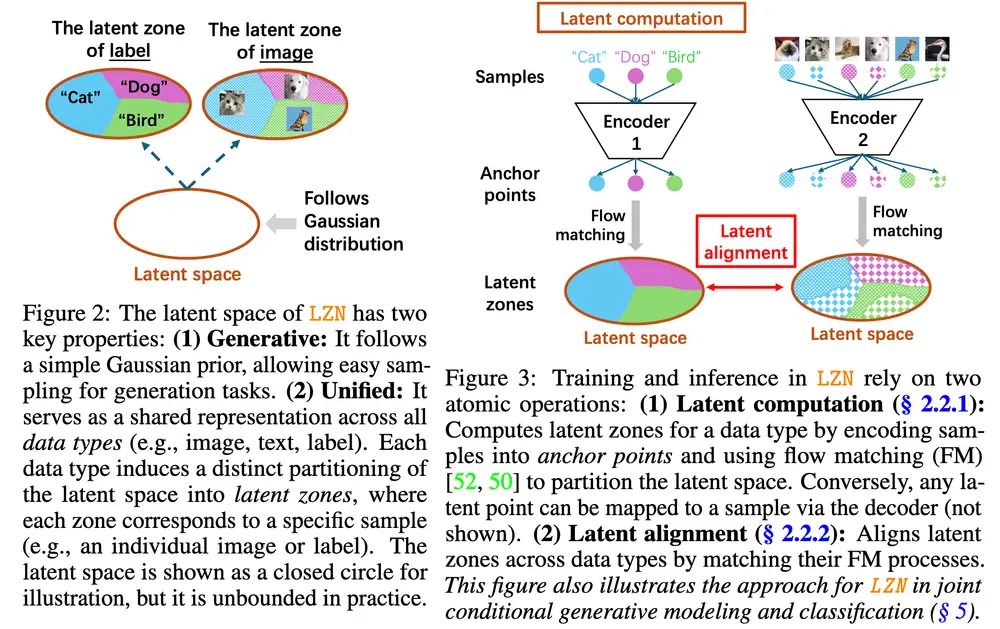
1. 传统方法的两大短板
- 生成模型(VAE、扩散模型):虽有 “编码器 + 高斯潜在空间 + 解码器” 的结构,但缺乏统一对齐机制 —— 若要加入文本、标签等条件,通常是将条件直接输入解码器(而非融入潜在空间),导致不同数据类型的潜在向量无法对齐,难以支持分类、表示学习任务;
- 表示学习方法(MoCo、SimCLR):仅关注 “图像→潜在向量” 的特征提取,对潜在空间无 “高斯分布” 约束,无法直接用于生成任务(生成需要可采样的分布特性)。
2. LZN 的创新解决方案
LZN 通过 “潜在分区 + 分区对齐” 的设计,同时满足 “生成性” 与 “统一性”:
- 潜在分区:让每个数据样本通过编码器后,在潜在空间中 “划分出专属分区”—— 比如每张猫的图像,其潜在向量会对应一个独特分区,且所有猫图像的分区会形成一个 “猫类别集群”;
- 分区对齐:强制不同类型数据的分区相互匹配 —— 比如 “狗的图像” 的潜在分区,必须完全包含在 “狗的标签” 的潜在分区内,确保 “图像 - 标签” 的潜在向量高度对齐;
- 这种设计既保留了高斯潜在空间的 “生成性”(可直接采样分区内的向量用于生成),又通过 “分区对齐” 实现了 “统一性”(不同数据类型的潜在表示一致),为跨任务协同扫清障碍。
关键实验结果:单框架胜任多任务,性能全面领先
为验证 LZN 的有效性,研究团队聚焦图像领域,开展了 “增强生成”“无监督表示学习”“联合生成与分类” 三类实验,结果均超越传统方法。
1. 增强生成模型:提升图像质量,缩小无条件与条件生成差距
将 LZN 的潜在向量融入主流整流流生成模型(不修改原模型损失函数),在多个数据集上实现质量提升:
- CIFAR-10 数据集:FID(衡量生成图像与真实图像相似度的指标,数值越低越好)从 2.76 降至 2.59,同时将 “无条件生成”(无标签指导)与 “条件生成”(有标签指导)的质量差距缩小 59%;
- 高分辨率数据集(256×256):在 AFHQ-Cat(猫脸)、CelebA-HQ(人脸)、LSUN-Bedroom(卧室场景)中,生成图像的细节丰富度、色彩自然度均优于原始整流流模型。
2. 无监督表示学习:超越经典对比学习方法
在 ImageNet 数据集上,用 LZN 提取的图像特征进行线性分类(无监督表示学习的常用评估方式),结果显著优于 MoCo、SimCLR 等经典方法:
- 基于 ResNet-50 骨干网络,LZN 的分类准确率比 MoCo 高 9.3%,比 SimCLR 高 0.2%;
- 这表明 LZN 的潜在向量能更高效地捕捉图像核心特征,为下游任务提供更强的表示支撑。
3. 联合生成与分类:任务间相互赋能,双向提升性能
同时启用 “图像编码器 / 解码器” 与 “标签编码器 / 解码器”,让 LZN 在同一框架内同时执行 “类条件生成” 与 “图像分类” 任务:
- 生成性能:FID 优于单独训练的条件整流流模型;
- 分类性能:在 CIFAR-10 上达到与主流分类模型相当的准确率;
- 关键发现:两个任务联合训练时,生成质量与分类准确率均比单独训练时更高 —— 证明共享潜在空间确实能实现任务间的正向迁移,让任务相互赋能。
局限性与未来方向:持续拓展统一框架的边界
尽管 LZN 已展现出强大的统一能力,但目前仍有需要完善的方向,研究团队也明确了后续优化路径:
1. 现有局限
- 独立生成能力待验证:目前 LZN 仅用于 “增强现有生成模型”,虽理论上可独立完成生成任务(无需依赖其他模型),但在复杂数据集上的独立生成效果尚未充分验证;
- 多模态与多任务覆盖不足:当前实验主要聚焦 “图像 - 标签” 的双向任务,尚未扩展到文本、语音等多模态数据,也未验证同时处理 3 个以上任务的能力;
- 训练效率有提升空间:在大规模数据集上,LZN 的训练计算成本较高,需进一步优化训练流程以提升效率。
2. 未来探索方向
- 完善独立生成功能:深入探索 LZN 独立完成生成任务的技术细节,优化潜在空间采样策略,确保在复杂场景下的生成质量;
- 扩展多模态与多任务:加入文本编码器 / 解码器、语音编码器 / 解码器,让 LZN 支持 “图文生成”“语音分类” 等多模态任务,同时验证多任务并行处理的稳定性;
- 提升训练效率:借鉴大型语言模型(LLM)的高效训练技术,优化编码器 / 解码器结构,降低大规模数据训练的计算成本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...