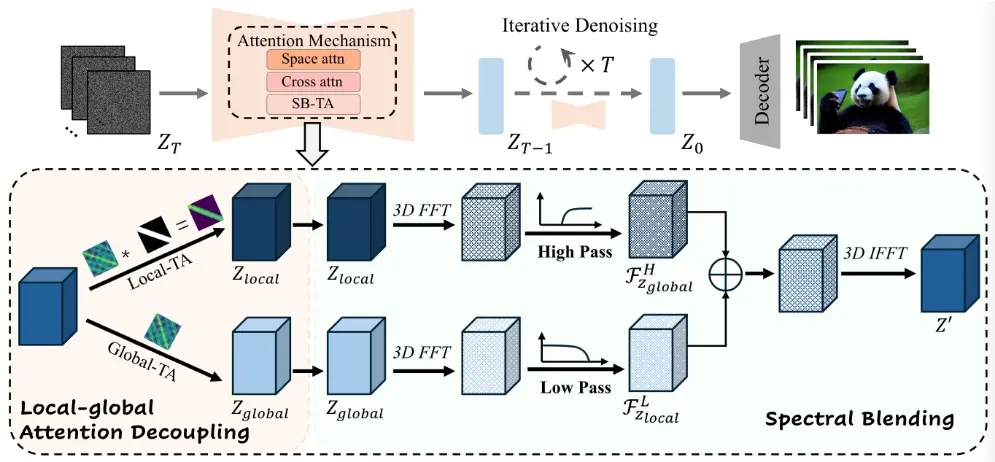
悉尼科技大学和浙江大学的研究人员推出一种用于生成长视频的模型FreeLong,它可以在不增加额外训练成本的情况下,让现有的短视频生成模型处理更长的视频内容,同时保持或提升视频的质量。FreeLong是基于局部全局频谱融合时间注意力机制 (SB-TA),该方法通过将全局视频特征的低频部分与局部视频特征的高频部分融合,在去噪过程中均衡长时间视频特征的频率分布。这种融合增强了长时间视频生成的一致性和清晰度。
例如,你手里有一个能够将文字描述转换成视频的魔法盒子。原本,这个盒子只能处理一些短小的视频片段,比如16帧。但你想用它来制作更长、更有趣的视频,比如128帧的长视频。FreeLong就是让这个魔法盒子升级,让它能够处理长视频的方法。

主要功能
- 将短视频扩散模型扩展到长视频生成。
- 无需重新训练,直接应用现有模型。
主要特点
- 无需训练:FreeLong不需要额外的训练数据或计算资源,可以直接使用预训练的短视频模型。
- 高频补偿:它通过一种新颖的方法来平衡长视频中的高频成分,解决了直接使用短视频模型生成长视频时可能出现的质量问题。
- 全局与局部特征融合:FreeLong能够融合全局视频特征和局部视频特征,以保持视频的全局一致性和局部细节的清晰度。
工作原理
- 频率分析:首先,FreeLong对短视频模型直接生成的长视频进行了频率分析,发现高频成分会随着视频长度的增加而显著下降,导致视频质量下降。
- SpectralBlend Temporal Attention (SpectralBlend-TA):FreeLong引入了一种新的机制,通过两个并行的流(全局流和局部流)来处理视频特征。全局流处理整个视频序列,捕捉广泛的依赖关系和主题,以保持叙述的连贯性;局部流则关注较短的帧子序列,以保留细节和平滑过渡。
- 频域融合:在频域中,FreeLong将全局视频特征的低频成分与局部视频特征的高频成分相结合,通过快速傅里叶变换(FFT)和逆快速傅里叶变换(IFFT)来实现这一过程。
具体应用场景
- 文本到视频的生成:用户可以提供一个文本描述,FreeLong能够根据这个描述生成长视频,比如一个讲述故事的视频或者一个产品演示视频。
- 视频编辑和后期制作:在视频编辑中,FreeLong可以用来增强或延长现有视频片段,增加视频内容的丰富性。
- 虚拟现实和游戏:在虚拟现实或游戏中,FreeLong可以用来生成连贯且高质量的长视频场景,提升用户体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











