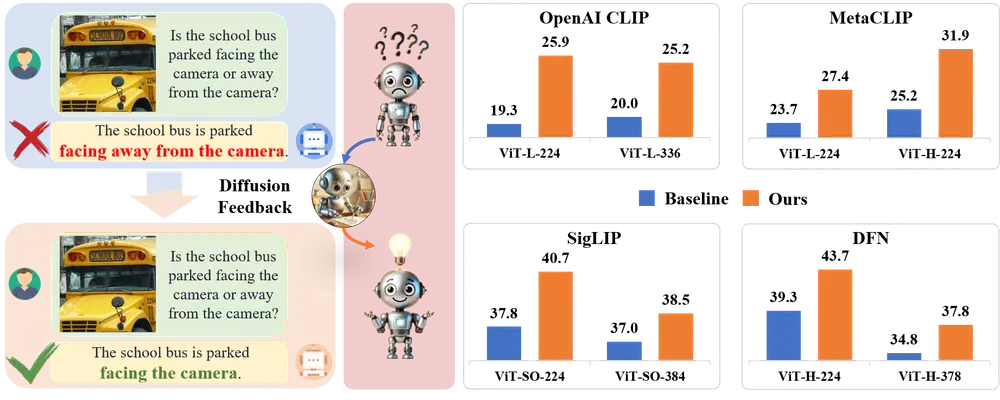
中国科学院自动化研究所、中国科学院大学人工智能学院、北京人工智能研究院 和北京交通大学的研究人员推出新型人工智能方法DIVA,它旨在提升一种流行的图像和语言联合预训练模型CLIP的视觉识别能力。CLIP模型擅长从大量数据中学习,能够理解图像内容并将其与文本描述相匹配,但它在识别一些细微的视觉细节方面存在局限,比如物体的方向、数量、颜色和结构等。
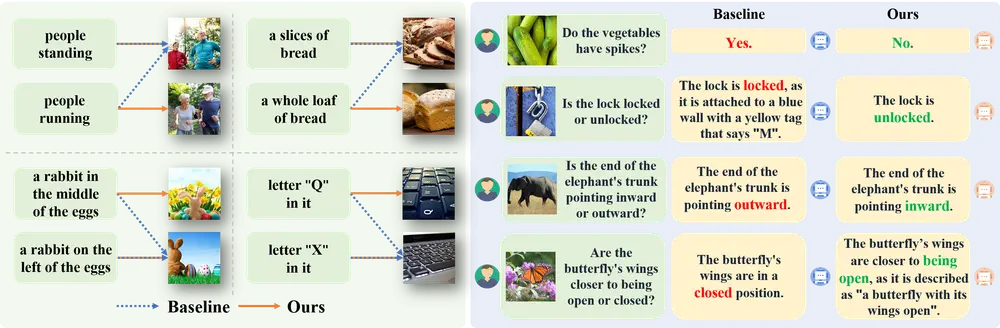
DIVA是一种使用扩散模型作为 CLIP 视觉辅助的方法。具体来说,DIVA 利用文本到图像扩散模型的生成反馈来优化 CLIP 表示,仅使用图像(无需对应的文本)。例如,你有一个包含各种动物的图片库,但它们的描述信息丢失了。使用CLIP模型,可能很难区分不同种类的相似动物,比如不同品种的狗。而应用了DIVA之后的CLIP模型,就能够更准确地识别出这些细微的差别,从而更有效地对这些动物图片进行分类或检索。
主要功能:
DIVA的核心功能是增强CLIP模型对于图像细节的感知能力。它通过一种自监督的学习方式,利用文本到图像的扩散模型来优化CLIP的表示,即使没有对应的文本信息,也能提升模型对图像的理解。
主要特点:
- 自监督学习:DIVA不需要额外的标注数据,它通过自我生成的反馈来指导学习。
- 简单有效:DIVA的方法简单,但能显著提升CLIP的性能。
- 保持零样本能力:在提升细节识别能力的同时,DIVA还能保持CLIP原有的零样本学习能力,即在没有见过的类别上也能进行有效的识别。
工作原理:
DIVA的工作原理可以类比为一个老师(扩散模型)通过给学生(CLIP模型)展示一些模糊的图片(添加噪声的图像),然后引导学生尝试恢复图片的清晰度。在这个过程中,老师会根据学生的表现给予反馈,帮助学生学习如何更好地识别和理解图像的细节。具体来说,DIVA利用扩散模型生成的细节丰富的图像作为条件,通过重建损失来优化CLIP模型,使其学习到更加丰富的视觉特征。
具体应用场景:
- 图像分类:在没有文本描述的情况下,对图像进行分类。
- 图像检索:根据文本查询,找到与之内容匹配的图像。
- 多模态任务:结合图像和文本信息,完成更复杂的任务,比如图像描述生成或者视觉问答。
- 视觉感知:在自动驾驶、机器人导航等领域,提升对周围环境的感知能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











