
在图像、视频生成领域,“让模型输出与人类偏好对齐”是关键目标——无论是生成符合审美标准的图像,还是帧间连贯的视频,都需要通过算法优化缩小模型输出与人类期望的差距。群体相对策略优化(GRPO)是近年常用的对齐方法,但它始终面临两大瓶颈:高计算成本(依赖顺序展开与大量SDE采样步骤,迭代耗时久)与训练不稳定性(稀疏终端奖励难以有效指导每一步训练)。
- 项目主页:https://fredreic1849.github.io/BranchGRPO-Webpage
- GitHub:https://github.com/Fredreic1849/BranchGRPO
为突破这一困境,北京大学、北京师范大学与字节跳动的研究团队提出了BranchGRPO技术——通过将GRPO的顺序展开过程重构为“分支树结构”,用“共享前缀分摊计算”“修剪低价值路径”的思路,在提升对齐质量的同时大幅降低计算成本。该方法在图像对齐、视频生成任务中均表现优异,为扩散模型的高效对齐提供了全新路径。
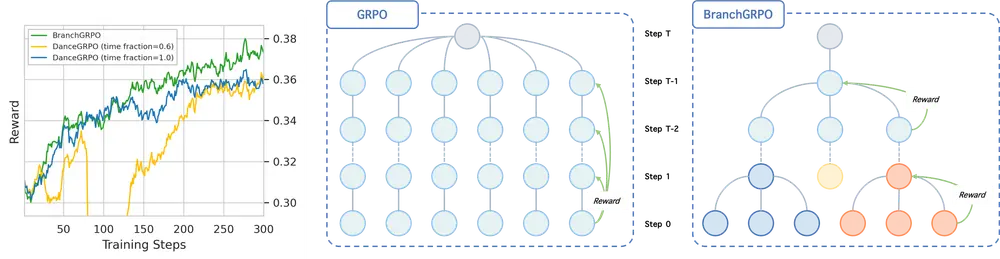
BranchGRPO的核心创新:用“树结构”解决两大核心痛点
BranchGRPO的本质是对传统GRPO的“流程重构”与“信号优化”,通过三项关键设计,同时攻克“效率低”与“不稳定”问题。
1. 分支采样方案:共享前缀,砍掉计算冗余
传统GRPO采用“顺序展开”模式:每一条生成轨迹都需要从初始步骤到最终步骤完整计算,不同轨迹间无复用,导致大量重复计算。
BranchGRPO则将采样过程设计为树状分支结构:
- 在扩散模型的关键去噪步骤(而非所有步骤),让当前轨迹“分裂”为多个子节点,形成分支;
- 所有子节点共享轨迹的“早期前缀”(即分裂前的计算结果),无需重复计算相同步骤;
- 例如生成一段视频时,前10帧的计算结果可作为共享前缀,后续分支仅需计算不同的帧序列,直接减少50%以上的重复采样成本。
这种设计从根本上改变了“顺序计算”的低效模式,通过“共享+分支”的组合,在保留探索多样性的同时,将每次迭代的训练时间显著缩短。
2. 基于树的优势估计器:把“稀疏奖励”变成“密集信号”
传统GRPO的另一大问题是“奖励稀疏”——只有当生成任务完成(如生成完整图像/视频)后,才能给出“符合偏好”或“不符合偏好”的终端奖励,中间步骤缺乏有效反馈,导致训练方向易偏移。
BranchGRPO引入基于树的优势估计器,解决奖励分配难题:
- 先将所有叶节点(即完整生成轨迹的终端奖励)按“路径概率”加权,反向传递到上层分支节点;
- 再对不同深度的节点奖励进行“深度归一化”——避免深层节点因路径长而被过度惩罚或奖励,确保每个步骤(无论处于树的哪一层)都能获得与自身贡献匹配的密集奖励信号;
- 比如生成图像时,“轮廓绘制”“色彩填充”等中间步骤不再无反馈,而是能通过上层节点传递的奖励,调整生成策略,让每一步都向“符合人类审美”的方向优化。
3. 修剪策略:保留高价值路径,加速收敛
分支树结构虽能减少冗余,但分支过多仍会增加计算负担。BranchGRPO通过轻量级修剪策略平衡“探索性”与“效率”:
- 宽度修剪:在每个分支层,仅保留奖励分数排名靠前的子节点(如保留前30%),移除低价值路径,避免无效计算;
- 深度修剪:对超过预设深度的分支进行截断,防止部分路径因过深导致计算量失控;
- 关键在于,修剪仅作用于“反向传播阶段”(计算梯度时),前向采样阶段仍保留足够分支以保证探索多样性,既不影响模型对优质轨迹的探索,又能将梯度计算成本降低40%以上。
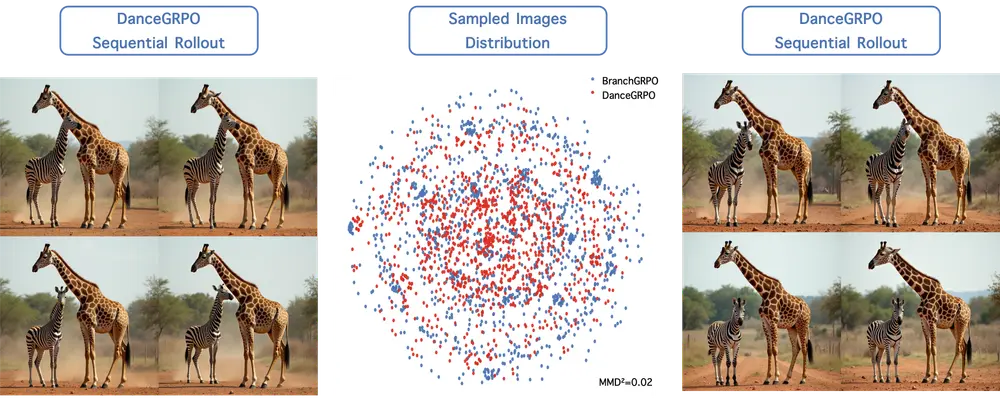
实测性能:对齐质量与效率双提升,覆盖图像、视频场景
为验证BranchGRPO的有效性,研究团队在两大核心任务(图像对齐、视频生成)中进行了对比实验,结果显示其在“对齐分数”与“训练效率”上均全面超越传统GRPO(如DanceGRPO)。
1. HPDv2.1图像对齐任务:对齐分数升16%,时间砍半
HPDv2.1是常用的图像对齐数据集,核心评估“模型生成图像与人类偏好的匹配度”。实验结果显示:
- 对齐质量:BranchGRPO的对齐分数比强基线(DanceGRPO)最高提升16%,生成的图像在构图、色彩、细节上更符合人类审美;
- 训练效率:每次迭代的训练时间比DanceGRPO减少近55%,若使用其变体BranchGRPO-Mix(进一步优化共享策略),训练速度可达到DanceGRPO的4.7倍,且对齐质量无任何下降。
2. WanX-1.3B视频生成任务:帧更清晰,时间连贯性更强
视频生成不仅要求单帧质量高,更需要帧间时间连贯(无跳帧、无模糊)。在WanX-1.3B视频数据集上:
- Video-Align分数:BranchGRPO生成的视频在“人类偏好对齐分数”上显著高于传统方法,说明视频内容更符合人类对“连贯、清晰”的需求;
- 视觉效果:生成的视频帧边缘更清晰,动态场景(如人物动作、物体移动)的帧间过渡更自然,无明显卡顿或形变,解决了传统GRPO视频生成中“帧间漂移”的问题。
核心功能与应用场景:不止于图像视频,可扩展至多领域
BranchGRPO的设计思路具有通用性,除了图像、视频生成,还可适配多类生成任务,其核心功能与应用场景可概括为以下四类:
1. 核心功能:三大能力支撑高效对齐
| 核心功能 | 作用与价值 |
|---|---|
| 高效分支采样 | 共享前缀减少计算冗余,降低训练耗时 |
| 密集奖励生成 | 将稀疏终端奖励转化为逐步骤信号,稳定训练方向 |
| 智能修剪 | 移除低价值路径,平衡探索性与计算效率 |
2. 典型应用场景:覆盖多模态生成与机器人领域
- 图像生成:用于头像设计、广告素材生成等场景,让模型快速生成符合用户审美的图像,减少人工筛选成本;
- 视频生成与编辑:适配短视频创作、动画制作,生成帧间连贯的视频,同时降低长视频生成的训练门槛;
- 机器人动作生成:机器人动作规划需“每一步动作都符合任务目标”(如抓取物体的连贯动作),BranchGRPO的密集奖励可指导每一步动作优化,提升动作生成的准确性与效率;
- 多模态生成:可扩展至基于扩散模型的大语言模型(LLMs)、图文跨模态生成任务,让多模态输出更贴合人类意图。
当前局限与未来方向:持续拓展技术边界
尽管BranchGRPO表现出色,但仍有需要完善的方向,研究团队也明确了未来的优化路径:
- 数据集覆盖不足:目前实验主要基于HPDv2.1(图像)与WanX-1.3B(视频)数据集,需在更多样化的数据集(如医学图像、工业设计图)中验证泛化性;
- 分支策略固定:当前分支的“分裂时机”“分支数量”依赖预设参数,未考虑样本难度(如复杂图像需更多分支探索),未来可设计“自适应分支策略”,根据样本实时调整;
- 长期视频生成待优化:虽在WanX-1.3B上验证了有效性,但面对更高分辨率(如4K)、更长时长(如1分钟以上)的视频,仍需进一步优化帧间连贯性与计算效率;
- 机器人领域落地:BranchGRPO的树状采样天然适配机器人动作生成,未来可结合具身智能场景,探索在真实机器人运动规划中的应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











