
北京大学医学技术研究所、百度视觉、北京大学未来技术学院生物医学工程系、北京大学国家生物医学影像中心和清华大学的研究人员开发了一种自回归生成多视图图像的方法 MVAR 。其目的是确保在生成当前视图的过程中,模型能够从所有先前的视图中提取有效的引导信息,从而增强多视图的一致性。 MVAR 拉近了纯自回归方法与最先进的基于扩散的多视图图像生成方法的生成图像质量,并成为能够处理同时多模态条件的多视图图像生成模型。
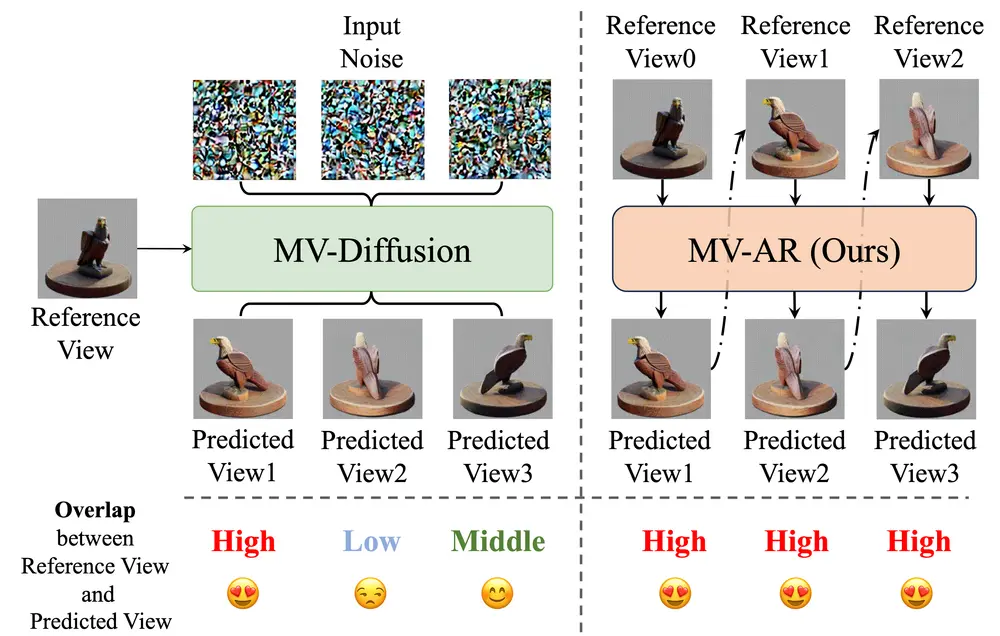
MVAR用于从人类指令(如文本、参考图像和几何形状)生成多视角一致的图像。该方法的核心在于解决多视角图像生成中的两个主要挑战:跨视角的一致性 和 在多样化条件下有效合成形状和纹理。MV-AR 通过自回归模型逐步生成多视角图像,利用前面生成的视角信息作为条件,从而提高多视角一致性。
例如,你需要为一个 3D 模型生成多视角图像,例如一个机器人玩具。你提供了一张机器人的前视图和文本描述:“黄色机器人,手持多种工具,其中包括一个铲子。” MV-AR 能够根据这些输入生成机器人从不同角度(如侧视图和后视图)的图像,同时保持图像之间的一致性。
主要功能
MV-AR 的主要功能包括:
- 多视角图像生成:从文本、图像或几何形状等条件生成多视角一致的图像。
- 内容保真:确保生成的图像与输入条件(如文本描述或参考图像)保持一致。
- 灵活的视角控制:支持生成任意视角的图像,适用于多种应用场景。
- 多模态条件处理:能够同时处理多种条件,如文本、图像、相机姿态和几何形状。
主要特点
MV-AR 的主要特点如下:
- 自回归生成:利用前面生成的视角信息作为条件,逐步生成后续视角的图像,从而提高多视角一致性。
- 多模态条件注入:设计了针对文本、相机姿态、图像和几何形状的条件注入模块,确保模型能够有效利用多种条件。
- 渐进式训练策略:通过逐步引入多模态条件,使模型能够同时处理多种条件。
- 数据增强技术:提出了“Shuffle Views”数据增强技术,通过随机排列视角顺序,显著扩展训练数据,缓解过拟合问题。
工作原理
MV-AR 的工作原理可以分为以下几个步骤:
- 自回归模型:基于 Transformer 架构,利用前面生成的视角信息作为条件,逐步生成后续视角的图像。
- 条件注入模块:
- 文本条件:使用 FLAN-T5 XL 编码器将文本转换为特征向量,并通过 MLP 投影到模型中。
- 相机姿态条件:使用 Plücker-Ray 嵌入将相机姿态信息编码为位置嵌入,指导生成特定视角的图像。
- 图像条件:通过 Image Warp Controller (IWC) 模块提取参考图像与当前视角的重叠特征,并逐个插入到模型中。
- 几何形状条件:使用预训练的形状编码器将 3D 点云映射为固定长度的潜码序列,作为形状条件。
- 渐进式训练:从文本到多视角(t2mv)模型开始,逐步引入其他条件(如图像和形状),通过随机丢弃和组合条件进行训练。
- 数据增强:通过“Shuffle Views”技术随机排列视角顺序,显著扩展训练数据,提高模型的泛化能力。
测试结果
MV-AR 在多个任务中表现出色,具体结果如下:
- 文本到多视角图像生成:
- FID:144.29
- IS:8.00
- CLIP-Score:29.49
- 定性结果:生成的图像在多视角一致性方面优于现有的扩散模型方法(如 MVDream)。
- 图像到多视角图像生成:
- PSNR:22.99
- SSIM:0.907
- LPIPS:0.084
- 定性结果:在生成后视图时,MV-AR 能够有效利用前面生成的视角信息,生成更一致的图像。
- 几何形状到多视角图像生成:给定几何形状,MV-AR 能够生成与输入形状一致的多视角图像,同时保持多视角一致性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











