
在AI领域,“推理”始终是衡量智能水平的核心指标。真正的推理,不只是回答问题,而是设计并执行通向目标的复杂行动序列——就像人在解一道数独时,会先观察整体格局,再逐步填入数字;在走迷宫时,会先判断大致方向,再调整每一步路径。
然而,当前主流的大语言模型(LLM)依赖“思维链”(Chain-of-Thought, CoT)进行推理,存在三个明显短板:
- 任务分解脆弱:一旦中间步骤出错,后续全盘崩溃;
- 数据需求大:需大量标注样本或人工编写的推理范例;
- 延迟高:多步自回归生成导致响应缓慢。
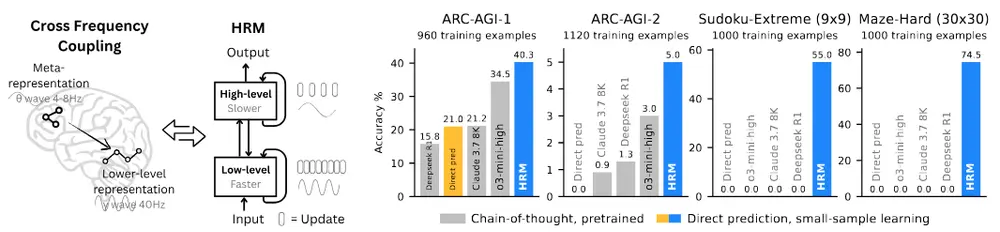
为突破这些限制,Sapient Intelligence 团队提出了一种全新架构——分层推理模型(Hierarchical Reasoning Model, HRM),它不依赖预训练、无需 CoT 数据,在仅 2700 万参数规模下,用 1000 个样本即可解决极端复杂的推理任务。
灵感来源:人脑的分层处理机制
HRM 的设计灵感来自人类大脑的认知方式。
研究表明,人类在完成复杂任务时,并非线性地一步步推导,而是采用多层次、多时间尺度的协同处理:
- 高层认知系统负责抽象规划(慢速、稳定)
- 低层执行系统负责细节计算(快速、灵活)
HRM 模拟了这一机制,构建了两个相互依赖的循环模块:
| 模块 | 功能 | 时间尺度 |
|---|---|---|
| 高层模块 | 抽象策略生成,全局状态更新 | 慢(跨步骤) |
| 低层模块 | 细节填充与局部求解 | 快(每步迭代) |
两者通过“上下文—反馈”机制持续交互:高层提供目标指引,低层返回执行结果,高层据此调整策略,形成闭环。
这种结构使 HRM 能在一次前向传播中完成深度推理,无需显式监督中间过程。
如何工作?三大核心机制
1. 分层收敛(Hierarchical Convergence)
推理过程被组织为多个“收敛阶段”:
- 在每个阶段,低层模块基于高层提供的抽象上下文,快速迭代至局部稳定状态;
- 高层模块感知低层输出后,更新其内部表示,进入下一阶段;
- 如此往复,直到达成最终解。
这类似于人在思考时的“顿悟—细化”循环:先有一个模糊想法,然后不断修正细节,最终形成完整方案。
2. 单步梯度近似(Single-Step Gradient Approximation)
传统循环网络训练依赖 BPTT(反向传播通过时间),内存消耗随序列长度增长而剧增。
HRM 则只使用各模块最终状态的梯度来近似整个推理轨迹的梯度。这种方法大幅降低训练内存开销,支持更深的计算图,同时保持稳定性。
3. 自适应计算时间 + 深度监督
HRM 支持动态调整推理步数:
- 简单任务:快速收敛,减少计算;
- 复杂任务:延长低层迭代,提升精度。
训练中引入阶段性监督信号,即在不同收敛阶段都施加损失函数,引导模型逐步逼近正确答案,增强学习效率。
性能表现:小模型,大能力
HRM 以极轻量级配置,在多项极具挑战性的推理任务上超越大型模型:
✅ 抽象与推理语料库(ARC-AGI)
ARC 是公认的 AGI 基准,要求模型从少量示例中归纳规则并泛化到新任务。
| 模型 | 训练样本数 | 准确率 |
|---|---|---|
| HRM | ~1,000 | 40.3% |
| o3-mini-high | 更多样本 + CoT | 34.5% |
| Claude 3.7 (8K) | - | 21.2% |
👉 HRM 在极小数据下实现 SOTA 表现,证明其强大的归纳能力。
✅ 极端难度数独(Sudoku-Extreme, 9×9)
输入为部分填充的格子,输出完整解。任务高度组合爆炸,需精确逻辑推演。
| 模型 | 准确率 |
|---|---|
| HRM | 74.5% |
| 其他 LLMs | 基本无法求解 |
即使面对最难级别的数独(如“火焰”难度),HRM 也能通过内部状态演化逐步逼近唯一解。
✅ 大型迷宫最优路径搜索(Maze-Hard, 30×30)
在复杂迷宫中找到起点到终点的最短路径,考验空间建模与全局规划能力。
HRM 不仅能成功导航,还能输出接近最优的路径序列,显著优于基于搜索增强或 CoT 的方法。
关键优势总结
| 特性 | 说明 |
|---|---|
| 🚫 无需预训练 | 直接端到端训练,不依赖大规模语言建模 |
| 📉 极低数据需求 | 仅需约 1000 个样本即可掌握复杂任务 |
| ⚡ 高效推理 | 单次前向传播完成多阶段推理,延迟低 |
| 💾 内存友好 | 单步梯度法避免长序列反向传播 |
| 🔁 动态计算 | 根据任务复杂度自适应调整推理步数 |
| 🧠 类人结构 | 分层+多时间尺度,贴近生物认知机制 |
更重要的是,HRM 展示了一条不同于“更大模型+更多数据”的发展路径:通过更好的架构设计,实现更高效率的智能行为。
意义与展望
HRM 的出现,标志着 AI 推理研究正在从“模仿人类输出格式”走向“模拟人类思维过程”。
它不是另一个更大的语言模型,而是一种新型计算范式的尝试:
- 它不再依赖外部提示工程;
- 不需要人工构造推理链条;
- 也不靠海量数据堆叠性能。
相反,它让模型在内部建立起稳定的推理动力学系统,像人一样“边想边做”。
虽然目前 HRM 主要在结构化任务上验证,但其架构原则具有广泛扩展潜力:
- 可迁移至具身智能中的任务规划;
- 支持机器人长期目标分解;
- 或成为通用代理系统的“推理内核”。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











