字节跳动Seed团队和南京大学的研究人员推出DuPO框架,它通过双学习(dual learning)和偏好优化(preference optimization)的方法,使大语言模型(LLMs)能够在没有标注数据的情况下进行自我验证和优化。例如,在数学问题解答中,模型不仅要给出答案,还要通过逆向任务(如从答案反推问题中的未知变量)来验证答案的正确性,从而实现自我监督学习。
主要功能
- 自我验证与优化:DuPO使LLMs能够在没有外部标注数据的情况下,通过构造的逆向任务(dual task)来验证和优化自身的输出。
- 提升模型性能:通过自我监督学习,显著提升LLMs在多种任务上的性能,如多语言翻译和数学推理。
- 泛化能力增强:使模型在训练过程中学习到的技能能够泛化到未见过的测试集上,提高模型的适应性和鲁棒性。
主要特点
- 无需外部标注:不依赖于昂贵且难以获取的人类标注数据或可验证的答案,降低了训练成本。
- 适用范围广:不仅适用于可逆任务(如机器翻译和反向翻译),还扩展到了非可逆任务(如数学推理)。
- 模型无关性:可以应用于多种不同架构和规模的LLMs,具有良好的通用性和可扩展性。
工作原理
- 任务分解与重构:将原始任务的输入分解为已知和未知部分,通过原始任务的输出和已知信息重构未知部分,形成逆向任务。
- 自我监督奖励:利用逆向任务的重构质量作为自我监督的奖励信号,优化原始任务的性能。
- 强化学习:采用强化学习算法(如GRPO)来最大化基于逆向任务的预期奖励,从而提升模型的性能。
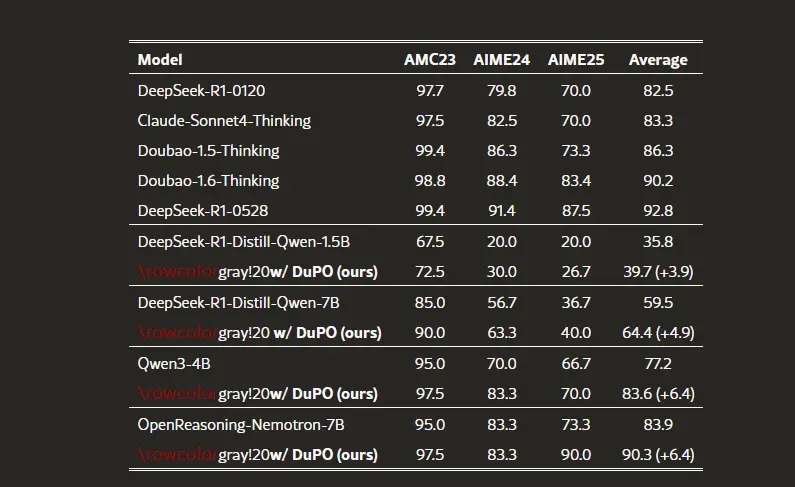
测试结果
- 多语言翻译:在756个翻译方向上,平均翻译质量提升了2.13 COMET点,使7B参数的Seed-X模型达到了与超大型模型相当的性能。
- 数学推理:在三个挑战性基准测试中,平均准确率提升了6.4个百分点,使Qwen3-4B模型的性能超过了DeepSeek-R1等超大型模型。
- 推理时重排:作为推理时的重排机制,无需额外训练,就能使模型性能提升9.3个百分点,使小型模型能够超越大型LLMs。
应用场景
- 多语言翻译:提高机器翻译系统的翻译质量和适应性,使其能够更好地处理多种语言之间的翻译任务。
- 数学推理:提升LLMs在数学问题解答、逻辑谜题等复杂推理任务中的准确性和可靠性。
- 其他领域:如代码生成、对话系统等,通过自我监督学习提升模型在这些领域的性能和泛化能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











