
弗吉尼亚大学和Adobe Research的研究人员推出新型图像到视频生成技术 Frame In-N-Out,突破传统视频生成中帧边界限制,实现更自由、更具创意的视频生成效果。具体来说,Frame In-N-Out 允许用户控制图像中的对象,使其自然地离开画面(Frame Out)或引入新的对象进入画面(Frame In),并通过用户指定的运动轨迹实现这一过程。
- 项目主页:https://uva-computer-vision-lab.github.io/Frame-In-N-Out
- GitHub:https://github.com/UVA-Computer-Vision-Lab/FrameINO
例如,在电影制作中,导演可能会让一个角色从画面外进入场景,或者让一个角色离开画面,以增强剧情的紧张感或推动情节发展。Frame In-N-Out 技术可以实现这种效果,用户只需提供一张初始图像、一个运动轨迹和一个身份参考图像(如果需要引入新对象),模型就能生成相应的视频。

主要功能
- Frame In(对象进入):允许新的身份(ID)对象(如人物、车辆、动物等)从画面外进入场景。
- Frame Out(对象离开):控制画面中已有的对象完全离开画面,并在需要时重新进入画面。
- 运动轨迹控制:用户可以通过指定的运动轨迹来精确控制对象的运动。
- 身份保持:在生成视频时,保持对象的身份特征,确保对象在运动过程中的视觉一致性。
主要特点
- 无边界画布(Unbounded Canvas):扩展了传统的第一帧区域,允许对象在更大的画布区域内运动,突破了画面边界的限制。
- 多条件融合:整合了多种条件,包括第一帧图像、文本提示、运动轨迹、身份参考图像等,以实现更精确的视频生成。
- 高效的视频扩散变换器(Video Diffusion Transformer):提出了一种新的视频扩散变换器架构,能够高效地处理多种条件,生成高质量的视频。
- 两阶段训练:通过两阶段训练方法,先学习基本的运动控制,再细化 Frame In 和 Frame Out 的效果,提高了模型的稳定性和生成质量。
工作原理
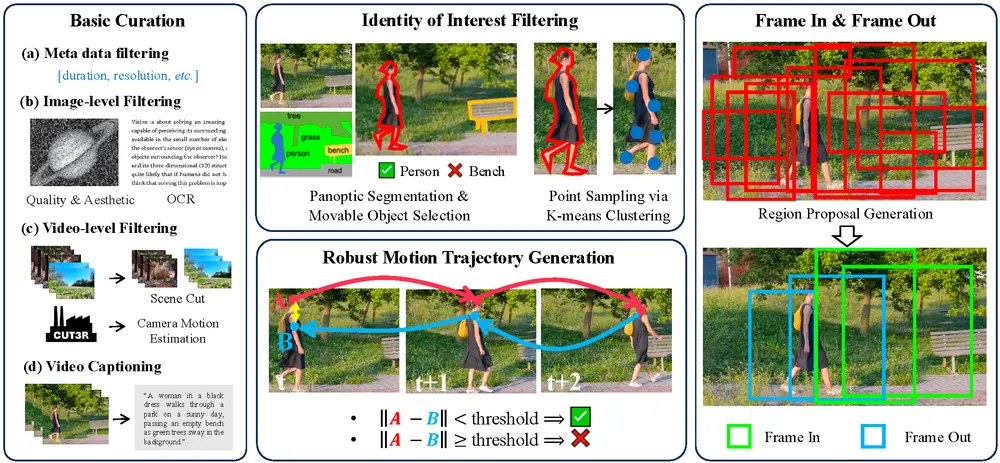
- 数据准备:
- 从原始视频中提取高质量的帧,并进行身份(ID)对象的识别和分割。
- 使用全景分割(Panoptic Segmentation)技术识别和分割视频中的所有对象,并选择可运动的对象作为跟踪目标。
- 通过 CoTracker3 模型生成准确的运动轨迹,并进行后向跟踪以确保轨迹的准确性。
- 定义合适的边界框,将第一帧区域与扩展的画布区域分开,识别 Frame In 和 Frame Out 模式。
- 模型架构:
- 基于 CogVideoX-I2V 的视频扩散变换器架构,支持灵活的分辨率训练。
- 将第一帧图像扩展到更大的画布区域,并调整位置编码系统以适应新的画布区域。
- 将运动轨迹转换为像素标记形式,并通过通道拼接的方式将其与第一帧图像和噪声潜变量结合。
- 将身份参考图像编码并帧对帧地与视频帧结合,实现身份保持。
- 训练过程:
- 第一阶段:学习基本的运动控制和文本提示条件。
- 第二阶段:联合训练 Frame In 和 Frame Out,考虑无边界画布区域,优化生成效果。
测试结果
- 定量评估:
- 使用 Fréchet Inception Distance (FID)、Fréchet Video Distance (FVD) 和 Learned Perceptual Image Patch Similarity (LPIPS) 等指标评估生成视频的质量。
- 在 Frame Out 任务中,Frame In-N-Out 的 FID 为 32.02,FVD 为 318.38,LPIPS 为 0.268,显著优于现有方法。
- 在 Frame In 任务中,Frame In-N-Out 的 FID 为 30.84,FVD 为 227.30,LPIPS 为 0.218,同样优于现有方法。
- 定性评估:
- 通过视觉比较,Frame In-N-Out 能够更准确地实现 Frame In 和 Frame Out 的效果,生成的视频在运动轨迹、身份保持和视觉质量上都优于现有方法。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











