阿里通义实验室推出基于浏览器的自主信息检索智能体WebDancer,它能够像人类一样在复杂的网络环境中进行多步骤的信息搜索和推理。WebDancer通过模仿人类浏览网页的行为,利用搜索和点击等工具,逐步收集信息并完成复杂的任务。
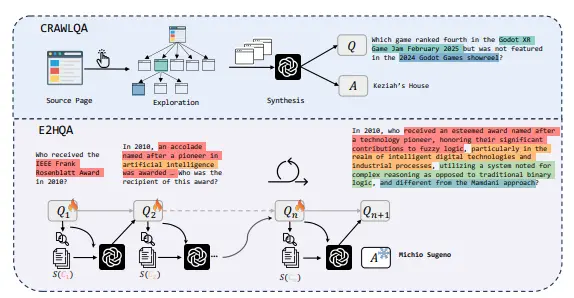
例如,如果用户询问“在2025年2月的Godot XR 1游戏竞赛中排名第四的游戏是什么?”,WebDancer能够通过搜索和浏览相关网页,找到答案并返回给用户。
主要功能
- 多步骤信息搜索:能够进行多步骤的搜索和推理,逐步解决复杂问题。
- 自主决策:根据收集到的信息自主决定下一步行动,如搜索、点击或回答问题。
- 环境感知:能够感知网络环境的变化,并根据实时信息做出适应性决策。
主要特点
- 数据驱动的训练:通过构建高质量的问答(QA)数据集,如CRAWLQA和E2HQA,来训练代理,使其能够处理复杂的多步骤问题。
- 强化学习优化:采用强化学习(RL)算法优化代理的行为,使其在复杂环境中具有更好的泛化能力。
- 灵活的工具使用:支持多种工具调用,如搜索和网页访问,以实现更高效的信息收集。
工作原理
- 数据构建:通过爬取网页和合成QA对来构建数据集,这些数据集能够反映多样化的用户意图和丰富的交互上下文。
- 轨迹采样:利用大型语言模型(LLM)和大型推理模型(LRM)生成高质量的交互轨迹,这些轨迹包含代理的思考、行动和观察。
- 监督微调(SFT):通过SFT对代理进行初始化训练,使其能够理解和执行多步骤的指令。
- 强化学习(RL):在SFT的基础上,使用RL进一步优化代理的行为,使其能够在复杂环境中做出更好的决策。
测试结果
WebDancer在两个具有挑战性的信息寻求基准测试(GAIA和WebWalkerQA)上表现出色。例如,在GAIA的Level 1、Level 2和Level 3任务中,WebDancer分别达到了41.0%、30.7%和0.0%的通过率,平均通过率为31.0%。在WebWalkerQA上,WebDancer的平均通过率为36.0%。这些结果表明WebDancer在处理复杂信息寻求任务方面具有显著的优势。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...