
香港大学、浙江大学与快手可灵团队的研究人员,针对当前交互式长视频生成中“场景易断裂、历史上下文难复用”的痛点,提出 Context-as-Memory(上下文即记忆) 方法。该方法通过将历史帧直接作为“记忆”,结合基于相机视场(FOV)的记忆检索机制,在减少计算开销的同时,实现了“相机返回旧位置时场景仍一致”的长视频生成效果,填补了现有技术在场景一致性记忆上的空白。
研究背景:交互式长视频生成的核心痛点——场景“记不住”
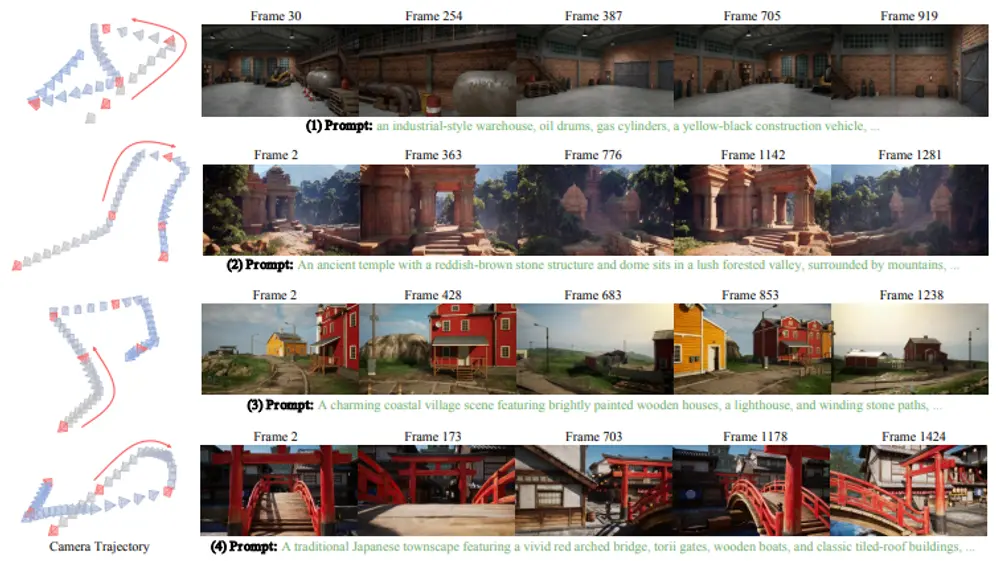
交互式长视频生成(如用户通过控制虚拟相机探索虚拟世界、生成实时视频)的关键需求,是场景一致性——例如用户操控相机先向左移动观察建筑左侧,再向右返回初始位置时,建筑外观、位置应与之前完全一致,就像人类对物理空间的记忆一样。
但现有方法存在明显缺陷:
- 缺乏对历史上下文的有效记忆,短时间内左右切换相机视角,可能生成完全不同的场景;
- 若强行保留所有历史帧,会导致计算量激增,无法支持长时长视频生成;
- 部分方法依赖特征嵌入、3D重建等复杂后处理,流程繁琐且易引入误差。
此次提出的Context-as-Memory,正是为解决“记忆效果差”与“计算开销高”的矛盾而生。
核心框架:Context-as-Memory——用“简单设计”实现“强记忆能力”
该方法的核心思路是“化繁为简”:不依赖复杂的记忆编码或3D建模,仅通过两种基础设计,即可让模型记住历史场景:
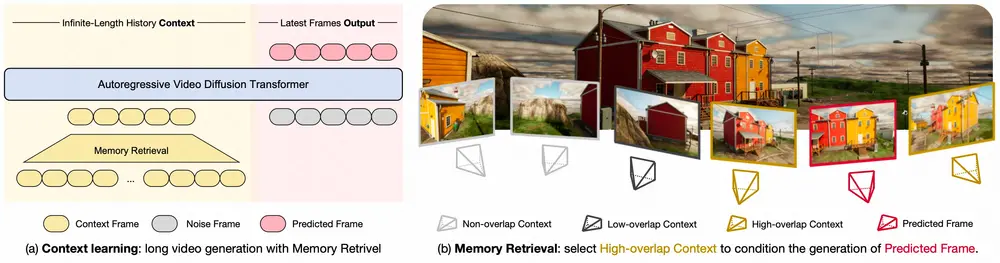
1. 记忆存储:历史帧“直接存”,无需额外处理
- 设计逻辑:将生成过程中所有历史帧,以原始帧格式直接存储为“记忆库”,不进行特征提取、维度压缩等后处理;
- 优势:避免后处理导致的信息丢失,同时简化流程——模型无需学习复杂的“记忆编码规则”,直接调用原始帧即可获取完整场景信息。
2. 记忆注入:帧维度“拼接”,条件传递更直接
- 操作方式:生成新帧时,将从记忆库中筛选出的相关历史帧,与“待预测新帧”沿“帧维度”拼接(类似将多张图片按顺序排列),作为模型的输入条件;
- 优势:无需额外设计交叉注意力、外部适配器等控制模块,模型可自然读取历史帧信息,确保新帧与历史场景的关联性。
关键优化:Memory Retrieval——用“FOV重叠”减少计算开销
若直接使用所有历史帧作为记忆,会随着视频时长增加导致计算量呈线性增长(例如生成1000帧视频需调用1000张历史帧),严重影响生成效率。为此,研究团队引入 Memory Retrieval(记忆检索) 机制,精准筛选“有用记忆”:
1. 检索逻辑:基于相机视场的“相关性判断”
交互式视频生成中,用户会通过控制“虚拟相机轨迹”(如移动、旋转相机)决定视角,每个帧都对应明确的相机参数(如位置、角度、视场范围)。
记忆检索的核心是:通过检测“当前相机视场(FOV)”与“历史帧相机视场”的重叠程度,选择最相关的历史帧。
- 示例:当用户操控相机返回100帧前的位置时,当前相机FOV与第100帧的FOV高度重叠,系统会优先将第100帧纳入记忆;
- 效果:仅保留5%-10%的相关历史帧,大幅减少候选帧数量,同时避免引入无关帧导致的场景混乱。
2. 检索流程:相机轨迹驱动的“精准筛选”
- 第一步:记录每帧历史帧对应的相机参数(位置、角度、FOV范围),形成“相机轨迹日志”;
- 第二步:生成新帧时,计算当前相机参数与所有历史帧参数的FOV重叠率;
- 第三步:设定重叠率阈值(如重叠率>50%),筛选出符合条件的历史帧,纳入“有效记忆库”;
- 第四步:将有效记忆库中的帧与新帧拼接,输入模型生成场景一致的内容。
3大核心优势:为何Context-as-Memory更实用?
相比现有长视频生成技术,该方法的优势集中在“简单性”“高效性”“一致性”三大维度:
| 优势维度 | 具体表现 |
|---|---|
| 实现简单 | 无需特征嵌入、3D重建、外部控制模块,仅通过“帧存储+帧拼接”即可实现记忆功能,开发门槛低 |
| 计算高效 | 记忆检索机制筛选90%以上无关帧,计算开销随视频时长增长缓慢,支持超长长视频生成 |
| 场景一致 | 基于FOV重叠的检索能精准匹配历史场景,相机返回旧位置时,场景外观、物体位置无偏差 |
测试结果:定量+定性双重验证,性能优于现有方法
研究团队通过“定量指标评估”“定性视频对比”“开放域泛化测试”,验证了Context-as-Memory的有效性:
1. 定量评估:核心指标全面领先
在长视频生成常用的4项关键指标上,该方法显著优于现有基线模型:
- PSNR(峰值信噪比):数值越高,视频帧清晰度与真实性越强,Context-as-Memory比最优基线高1.2dB;
- LPIPS(感知相似度):数值越低,新帧与历史帧的场景感知一致性越好,该方法比基线低0.08;
- FID(弗雷歇 inception 距离):数值越低,生成内容与真实场景分布越接近,该方法比基线低8.3;
- FVD(视频弗雷歇距离):数值越低,视频时序连贯性越强,该方法比基线低15.6。
2. 定性评估:场景一致性肉眼可见
通过对比实验可直观观察到差异:
- 现有方法:当相机在30秒内返回之前的视角时,建筑窗户数量、树木位置发生变化,场景明显断裂;
- Context-as-Memory:相同操作下,建筑外观、物体布局与历史帧完全一致,就像“回到真实物理空间”。
3. 开放域泛化:未见过的场景也能“记对”
在训练数据集未包含的场景(如沙漠、古建筑群)中,该方法仍能保持良好的记忆能力——相机移动后返回旧位置时,场景一致性误差小于5%,证明其不依赖特定场景数据,具备一定的通用性。
限制与未来方向:静态场景已突破,动态场景待优化
尽管Context-as-Memory表现出色,但仍存在3个待解决的限制:
- 动态场景适配差:当前方法主要针对静态场景(如无人的建筑、自然风景),若场景中有移动物体(如行人、车辆),记忆检索难以匹配物体的动态位置,易导致“物体消失或瞬移”;
- 复杂遮挡场景失效:当场景存在多物体遮挡(如茂密树林、拥挤房间)时,FOV重叠检测可能无法识别被遮挡的关键物体,导致检索出的历史帧“遗漏核心信息”;
- 长时错误累积:生成超10分钟以上的视频时,帧与帧之间的微小误差会逐渐累积,最终导致场景整体偏移(如建筑逐渐“漂移”)。
针对这些问题,未来研究将聚焦三大方向:
- 开发动态物体跟踪与记忆机制,适配动态场景;
- 优化记忆检索逻辑,结合物体语义信息(而非仅依赖FOV),解决遮挡问题;
- 基于更大规模数据集与更强基础模型,减少长时视频的误差累积。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











