
加州大学伯克利分校、FuriosaAI、ICSI和劳伦斯伯克利国家实验室的研究人员推出一种名为XQUANT的技术,通过低比特量化和KV缓存重物质化来显著降低大语言模型(LLM)推理过程中的内存消耗。XQUANT通过量化每一层的输入激活值X,而不是传统的KV缓存,从而在推理时动态重构KV缓存,以减少内存占用并提高推理效率。
以一个大语言模型(如LLaMA-2-7B)为例,该模型在进行文本生成时,需要频繁加载和存储KV缓存,这会导致大量的内存操作,从而限制了推理速度。XQUANT通过量化输入激活值X,并在需要时动态重构KV缓存,显著减少了内存操作,从而加速了推理过程。
主要功能
- 内存压缩:通过低比特量化输入激活值X,减少内存占用。
- 动态重构:在推理过程中动态重构KV缓存,减少内存操作。
- 跨层压缩:利用X值在不同层之间的相似性,进一步压缩内存。
- 支持多种模型:适用于使用多头注意力(MHA)和分组查询注意力(GQA)的模型。
主要特点
- 显著的内存节省:相比传统的KV缓存量化方法,XQUANT能够实现高达12.5倍的内存节省。
- 高精度保持:在低比特量化下,XQUANT能够保持接近FP16基线的精度。
- 计算与内存的权衡:通过增加计算量来减少内存操作,适应现代硬件中计算能力增长快于内存带宽的趋势。
- 简单易用:使用标准的均匀量化,无需复杂的校准过程。
工作原理
- 量化输入激活值X:XQUANT对每一层的输入激活值X进行量化,而不是直接量化KV缓存。这减少了内存占用,因为只需要存储一个张量,而不是分开存储Keys和Values。
- 动态重构KV缓存:在推理过程中,XQUANT通过将量化后的X与投影矩阵相乘,动态重构KV缓存。虽然这增加了计算量,但由于LLM推理通常是内存带宽受限的,因此这种权衡是合理的。
- 跨层压缩:XQUANT-CL利用X值在不同层之间的相似性,通过压缩层间差异来进一步减少内存占用。这种方法通过累积每层的微小变化,实现了高效的内存压缩。
- 支持GQA模型:对于使用GQA的模型,XQUANT通过离线奇异值分解(SVD)将输入激活值X投影到一个低维空间,从而减少内存占用,同时保持高精度。
测试结果
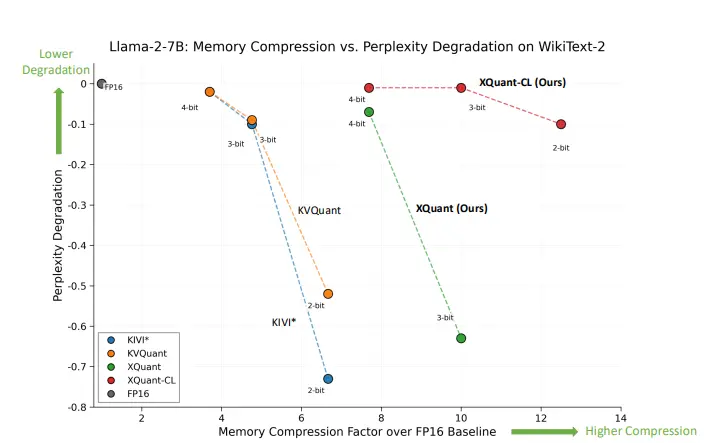
- 内存节省:XQUANT在不同模型上实现了显著的内存节省。例如,在LLaMA-2-7B模型上,XQUANT-CL在3比特量化下实现了10倍的内存节省,而在2比特量化下实现了12.5倍的内存节省。
- 精度保持:XQUANT在低比特量化下保持了接近FP16基线的精度。例如,在LLaMA-2-7B模型上,XQUANT-CL在3比特量化下仅导致0.01的困惑度下降,而在2比特量化下仅导致0.1的困惑度下降。
- 下游任务评估:XQUANT在长文本理解和推理任务上表现出色。例如,在LongBench和GSM8K数据集上,XQUANT在低比特量化下保持了与基线相当的性能。
应用场景
- 长文本生成:在需要处理长文本的场景中,如文档摘要、问答系统等,XQUANT能够显著减少内存占用,提高推理速度。
- 资源受限的设备:在内存受限的设备上,如移动设备或边缘计算设备,XQUANT能够使大型语言模型的推理成为可能。
- 大规模部署:在需要大规模部署语言模型的场景中,XQUANT能够降低硬件成本,提高系统的可扩展性。
- 实时应用:在需要实时响应的应用中,如聊天机器人或语音助手,XQUANT能够提高推理速度,提供更流畅的用户体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











