
由北京大学人工智能研究院、北京通用人工智能研究院与腾讯优图实验室联合提出的新方法 TransMLA,为大模型推理效率的提升提供了一条实用路径。该方法能够将已广泛部署的 GQA(Grouped Query Attention)架构模型,如 LLaMA、Qwen、Mixtral 等,无需重新训练,即可转换为基于 MLA(Multi-Head Latent Attention) 架构的高效版本,同时全面兼容 DeepSeek 系列模型,在长序列推理场景下实现显著加速。
这一进展的意义在于:它绕开了从零训练 MLA 模型所需的巨大资源投入,使已有 GQA 模型也能享受 MLA 带来的推理优势,尤其适用于大规模服务部署场景。
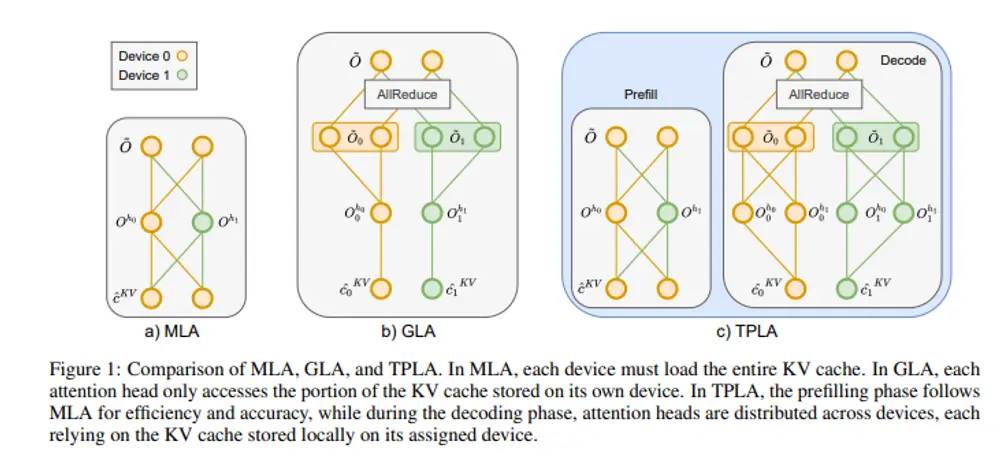
为什么需要 MLA?
在当前大模型的实际应用中,通信开销正逐渐取代计算本身,成为分布式推理的主要瓶颈。传统多头注意力机制在生成过程中需缓存完整的 Key 和 Value(KV)张量,随着序列长度增长,KV 缓存占用内存迅速膨胀,且跨设备传输成本高昂。
MLA 通过引入低秩潜在表示来压缩 KV 缓存,仅保留关键信息,并通过 Absorb 操作防止其在后续层中恢复原始维度,从而有效控制缓存增长。这不仅减少了显存占用,也显著降低了设备间通信量,提升了推理吞吐。
然而,尽管 MLA 在 DeepSeek V2/V3/R1 上验证了有效性,但由于主流厂商已在 GQA 架构上投入大量优化资源,重新训练一套 MLA 模型的成本过高,限制了其广泛应用。
TransMLA:让 GQA 模型“平移”到 MLA
TransMLA 的核心目标是解决这一现实困境:如何在不重新训练的前提下,将成熟的 GQA 预训练模型迁移到 MLA 架构上?
研究人员提出了一种名为 TPLA(Tensor Parallel Latent Attention) 的新型注意力机制,作为 TransMLA 框架的核心组件。TPLA 在保留原始模型参数完整性的同时,重构了注意力计算流程,使其兼容 MLA 的压缩特性,并支持张量并行(Tensor Parallelism, TP)环境下的高效执行。
核心功能
- KV 缓存压缩
- 将每个注意力层的 Key 和 Value 映射为一个共享的低秩潜在向量 $ c_{KV} $,仅缓存该向量。
- 大幅降低 KV 缓存的存储和通信开销,尤其在长序列场景下优势明显。
- 张量并行优化
- 将潜在向量 $ c_{KV} $ 与查询(Query)的输入维度沿头维度切分,分布到多个设备上。
- 各设备独立完成局部注意力计算,最后通过 all-reduce 聚合结果,避免频繁通信。
- 性能保持机制
- 每个注意力头仍能访问完整的潜在表示,确保模型表达能力不受损失。
- 引入正交变换(如 Hadamard 或 PCA)对权重进行重新参数化,减少跨设备干扰,最小化精度下降。
关键特性
| 特性 | 说明 |
|---|---|
| 无缝兼容 | 可直接加载现有 GQA 模型权重,无需微调或重训练 |
| 即插即用 | 支持主流架构(LLaMA、Qwen、Mixtral 等),适配性强 |
| 高效推理 | 在 32K 上下文长度下,相比原生 MLA 实现最高近 2 倍加速 |
| 灵活部署 | 支持不同规模的张量并行配置,适应多样硬件环境 |
技术实现路径
TransMLA 的迁移过程分为以下几个关键步骤:
- 结构映射
将 GQA 中的多组查询结构映射为 MLA 所需的共享 KV 压缩路径,构建潜在向量生成通道。 - 参数重参数化
利用正交矩阵对原始注意力权重进行变换,使压缩后的潜在表示在分布上接近原生 MLA 训练结果,减少迁移误差。 - Absorb 操作集成
在前馈层或归一化层中嵌入 Absorb 模块,持续抑制 KV 缓存膨胀,维持低秩状态。 - 张量并行适配
在 TP 模式下,将潜在向量和查询头分布到不同设备,利用 all-reduce 同步最终输出,平衡计算与通信负载。
整个过程无需反向传播,完全前向兼容,可在推理时动态启用。
实验表现
在多个标准基准上的测试表明,TransMLA 在几乎不损失性能的前提下,实现了显著的推理加速:
- 语言建模能力:在 WikiText-2 上的困惑度(PPL)与原模型差距小于 0.5;
- 综合理解能力:MMLU、ARC 等评测任务中准确率下降不超过 1.2%,属于可接受范围;
- 推理速度提升:
- 在 32K 长文本场景下,DeepSeek-V3 提升 1.79 倍;
- Kimi-K2 提升达 1.93 倍;
- 预填充阶段优化:采用 MLA 形式处理初始 token,避免 RMSNorm 和 Softmax 的跨设备分割,进一步降低延迟。
应用前景
TransMLA 为大模型服务部署提供了新的优化思路。对于已上线的 GQA 模型,无需重新训练即可获得 MLA 的推理效率优势,尤其适用于:
- 长文档处理(法律、金融、科研)
- 对话系统中的上下文扩展
- 边缘设备或资源受限环境下的高效推理
此外,该方法也为未来混合注意力架构的设计提供了可借鉴的技术路径。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











