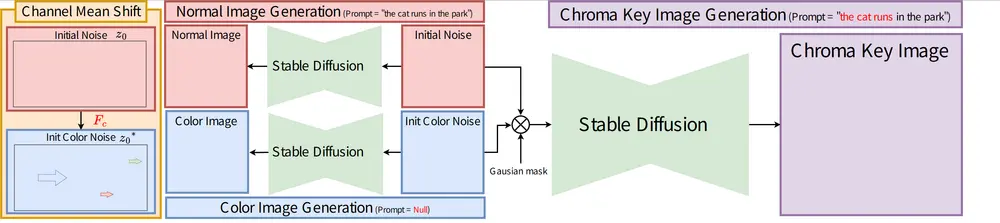
当前扩散模型已能生成高真实感、高文本忠实度的图像,但主流大规模文本到图像模型(如 Stable Diffusion)面临一大局限——难以生成“前景对象置于色键背景”的图像,若要分离前景与背景元素,往往需要额外微调。
为解决这一问题,日本东京法政大学理工学院与莱茵兰-普法尔茨凯泽斯劳滕-兰道工业大学的研究团队,提出了TKG-DM(无训练色键内容生成扩散模型) 。该模型通过创新优化初始随机噪声的颜色属性,首次实现了“无需微调即可精准控制背景生成”,既能产出指定颜色背景的前景图像,又能轻松分离前景与背景,且在后续扩展中展现出跨任务适配能力。
TKG-DM核心能力:三大功能打破技术局限
TKG-DM的设计围绕“无训练、高精度、可扩展”展开,核心功能直接针对现有扩散模型的痛点,具体可概括为三点:
- 精准生成色键背景图像
区别于传统模型“前景背景融合难分离”的问题,TKG-DM能明确生成具有指定颜色(如常用的绿色、蓝色)的色键背景,同时保证前景对象的完整性与真实感,生成后无需复杂处理即可实现前景与背景的精确分离。 - 全程无需微调与额外数据
无需对预训练扩散模型进行二次微调,也不需要额外标注数据集,直接基于现有预训练模型即可运行。这一特性大幅降低了技术使用门槛,避免了微调过程中的计算成本与时间消耗。 - 无缝扩展至多类生成任务
不仅能完成基础的文本到图像生成,还可扩展到条件文本到图像生成(如指定“红色背景下的白色茶杯”)、一致性模型(更快生成高质量图像的模型架构)以及文本到视频生成,适配多场景需求。
TKG-DM技术亮点:四大特点奠定优势
相较于现有背景控制相关技术,TKG-DM的独特性体现在四个关键特点上,这些特点共同支撑其“高效、精准、灵活”的表现:
- 训练自由性:作为首个无需微调就能实现背景颜色控制的扩散模型,TKG-DM跳过了传统技术中“针对特定背景重新训练模型”的步骤,直接复用预训练模型能力,降低了技术落地成本。
- 控制精确性:不仅能控制背景颜色,还可精准调整前景对象的大小、在画面中的位置以及前景数量(如“蓝色背景下并排的两个黄色花瓶”),满足精细化创作需求。
- 运行高效性:在生成高质量图像的同时,因无需微调与额外数据处理,计算成本显著低于需要微调的模型,兼顾效果与效率。
- 任务灵活性:底层设计具备跨任务适配能力,无需大幅修改架构,即可应用于文本到视频、一致性模型等场景,拓展了技术的适用范围。
TKG-DM工作原理:三步实现背景精准控制
TKG-DM通过“操控初始噪声”实现背景控制,整个过程可拆解为三个关键步骤,形成从“噪声优化”到“内容生成”的完整链路:
- 通道均值偏移:锁定背景颜色
初始噪声是扩散模型生成图像的基础,TKG-DM通过“通道均值偏移”技术,调整初始噪声中RGB各通道的均值(如想生成绿色背景,就提升绿色通道均值、降低红蓝色通道均值),从源头控制生成图像的颜色组成,确保背景呈现指定色键颜色。 - 初始噪声选择:分离前景与背景
引入“高斯掩码”工具,将“原始初始噪声”与“经过颜色调整的噪声”进行混合——高斯掩码会划定前景与背景区域,让背景区域使用颜色噪声(保证指定色键),前景区域使用原始噪声(确保前景内容符合文本提示),通过这种区域化噪声控制,实现前景与背景的初步分离。 - 注意力机制:优化内容一致性
借助自注意力与交叉注意力机制进一步优化生成效果:自注意力聚焦前景对象内部,确保前景细节(如物体纹理、形状)的一致性;交叉注意力则将生成内容与输入的文本提示对齐(如文本要求“黑色猫咪”,交叉注意力会确保前景对象是猫咪而非其他动物),最终生成“前景符合文本、背景为指定色键”的图像。
TKG-DM测试验证:定量与定性双优
研究团队通过“定量评估”与“用户研究”双重维度,验证了TKG-DM的性能,结果显示其显著优于现有同类方法:
- 定量评估:关键指标大幅提升
在衡量图像真实性的FID(弗雷歇 inception 距离) 与衡量前景背景分离精度的mask-FID(掩码FID) 两项核心指标上,TKG-DM较现有方法分别提升33.7%和35.9%,证明其在“图像真实感”与“前景背景分离准确性”上均处于领先水平。 - 用户研究:用户偏好度领先
针对“前景真实性”与“文本对齐度”两项用户关注的维度展开调研,结果显示53.9%的用户更偏好TKG-DM生成的图像,进一步验证了其在实际使用场景中的优势。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











