
文本-图像到视频生成(TI2V) 是一项旨在根据文本描述从静态图像生成动态视频的技术。尽管这一领域已经取得了一定进展,但现有方法在生成与文本提示良好对齐的视频时仍面临显著挑战,尤其是在指定运动细节方面。大多数模型生成的视频往往具有有限且相同的运动模式,导致“条件泄漏”现象——即模型通过简单复制输入图像而获得较低的损失值,而不是真正学习到文本所描述的运动。
MotiF:运动焦点损失提升文本对齐和运动生成
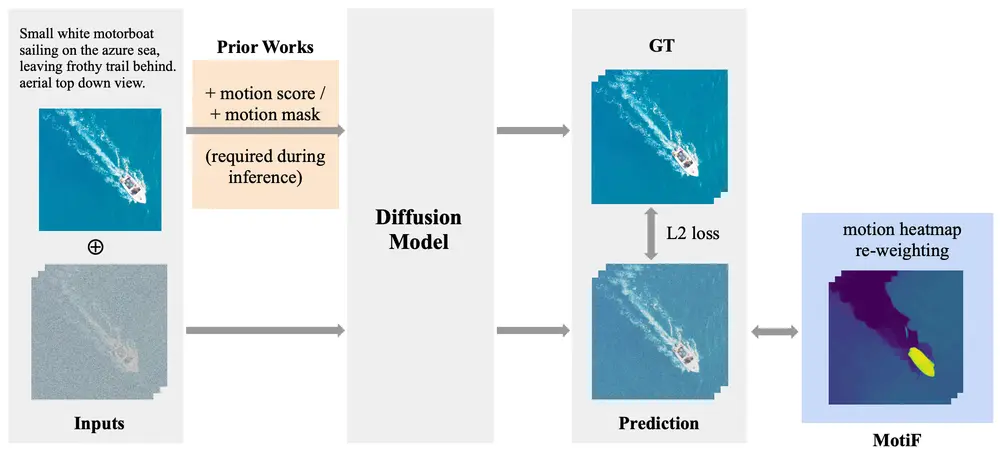
为了解决上述问题,布朗大学和Meta的研究人员提出了 MotiF(Motion Focused Loss),这是一种通过引导模型关注更多运动区域来改善文本对齐和运动生成的方法。MotiF的核心思想是通过运动热图重新加权扩散损失,使得模型在训练过程中更加专注于那些具有显著运动的区域。例如,我们有一张草地上的熊的静态图片和文本提示:“一只熊在草地上跳跃”。使用MotiF的方法,模型将生成一个视频,其中熊根据文本提示进行跳跃动作,而不仅仅是静态图像的重复。

关键技术点
- 光流生成运动热图:在训练过程中,研究人员使用光流算法计算视频帧之间的运动强度,并生成运动热图。这些热图反映了每个像素的运动程度,帮助模型识别出哪些区域应该被赋予更高的权重。
- 运动焦点损失(MotiF):传统的L2损失对所有像素进行平等优化,这可能导致模型忽视了细微的运动变化。MotiF通过引入运动热图,根据运动强度对损失进行加权,使得模型更关注那些具有明显运动的区域。这种加权机制不仅提高了生成视频的运动准确性,还增强了文本描述与视频内容的对齐度。
- 避免条件泄漏:通过聚焦于运动区域,MotiF有效地防止了模型仅通过复制输入图像来降低损失值的现象。相反,模型被迫学习到更多的运动细节,从而生成更具多样性和真实感的视频。
工作原理
MotiF的工作原理包括以下几个步骤:
- 运动热图生成:使用光流算法计算视频中每帧之间的运动强度,生成运动热图。
- 损失函数重加权:根据运动热图的强度,对标准的扩散模型损失函数进行重加权,使得模型在训练时更多地关注运动区域。
- 联合损失优化:模型训练时使用标准的扩散损失和运动焦点损失的联合,通过调整权重λ平衡两者的影响。
TI2V Bench:一个多样化的评估基准
为了更好地评估TI2V模型的表现,研究人员还提出了一套新的基准测试集 TI2V Bench。这个数据集包含320个图像-文本对,涵盖了22个多样化场景,旨在提供一个更为全面和具有挑战性的评估环境。
TI2V Bench的特点
- 多样化场景:TI2V Bench包含了来自不同领域的图像和文本对,如自然景观、城市街景、动物行为等,确保了评估的广泛性和代表性。
- 多样的图像风格:每个场景包括3到5张内容相似但风格不同的图像,允许模型在相同背景下生成多样化的动画效果。
- 丰富的文本提示:每个场景配有3到5个不同的文本提示,描述了各种可能的运动方式或新增的对象,增加了评估的复杂性和挑战性。
- 具有挑战性的场景:数据集中包含了一些复杂的场景,例如初始图像中有多个对象需要精细控制,或者文本提示描述了新对象的出现,这些场景进一步考验了模型的泛化能力和创造力。
人工评估与结果
为了验证MotiF的有效性,研究人员在TI2V Bench上进行了人工评估,比较了MotiF与其他九个开源TI2V模型的表现。评估结果显示,MotiF在多个方面取得了显著改进,平均偏好率达到了72%。具体而言:
- 增强的文本对齐:MotiF生成的视频能够更好地反映文本描述的内容,尤其是在涉及复杂运动的情况下。
- 准确的对象运动:MotiF能够生成更加逼真和连贯的对象运动,避免了其他模型常见的运动不自然或重复的问题。
- 多样性与创造性:MotiF在处理多样化场景和文本提示时表现出更强的创造性和灵活性,生成的视频更具视觉吸引力和艺术价值。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











