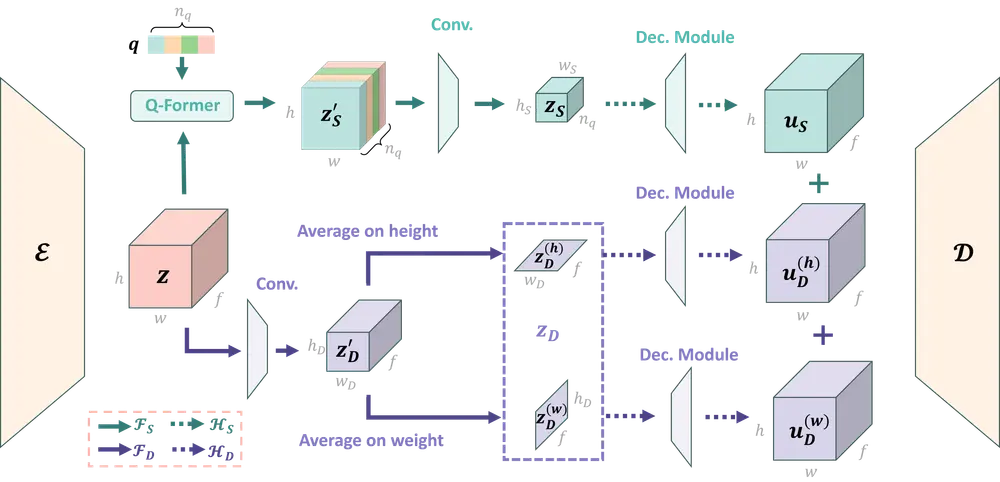
北京大学、微软亚洲研究院和香港中文大学(深圳)的研究人员推出一种新型视频自编码器(Video Autoencoder,简称Video AE),名为VidTwin。VidTwin的核心创新在于将视频分解为两个不同的潜在空间:结构潜在向量(Structure Latent Vectors)和动态潜在向量(Dynamics Latent Vectors)。结构潜在向量负责捕捉视频的整体内容和全局运动,而动态潜在向量则代表细节和快速运动。这种分解方法旨在提高视频生成的质量和效率。
- 项目主页:https://wangyuchi369.github.io/VidTwin
- GitHub:https://github.com/microsoft/VidTok/tree/main/vidtwin
例如,考虑一个视频展示了一个人在拧紧螺丝。VidTwin会将视频中的桌子和螺丝等主要语义内容识别为结构潜在向量,而颜色、纹理和螺丝的快速局部运动(如螺丝的下移和旋转)则由动态潜在向量编码。通过这种方式,VidTwin能够更有效地重建视频,并在下游生成任务中表现出色。
主要功能
VidTwin的主要功能包括:
- 高压缩率的视频编码:通过将视频分解为结构和动态潜在向量,VidTwin实现了大约500倍的压缩率,同时保持高重建质量。
- 下游生成任务的有效性:VidTwin的视频自编码器能够适应生成模型,需要平滑的潜在空间。
- 解释性和可扩展性:VidTwin的设计确保了潜在空间的有意义和可解释的表示,为未来的研究提供了机会。
主要特点
VidTwin的主要特点包括:
- 解耦设计:将视频内容分解为结构和动态两个部分,以更有效地学习和重建视频。
- 高压缩率与高质量重建:在保持高重建质量的同时实现高压缩率。
- 适用于生成模型:VidTwin的潜在表示适合于生成任务,可以与扩散模型等生成框架结合使用。
工作原理
VidTwin的工作原理涉及以下几个步骤:
- 编码过程:使用编码器将输入视频编码为结构和动态潜在向量。
- 潜在向量提取:通过两个子模块分别提取结构和动态潜在向量。
- 解码过程:将提取的潜在向量对齐到相同的维度空间,合并后输入到解码器中,以重建视频。
具体应用场景
VidTwin可以应用于以下场景:
- 视频压缩:在保持视频质量的同时减少视频文件的大小,便于存储和传输。
- 视频生成和编辑:利用VidTwin的潜在空间进行视频内容的生成和编辑,如改变视频的运动或内容。
- 多模态应用:结合文本或其他模态信息生成视频,例如根据文本描述生成视频内容。
- 视觉理解任务:由于VidTwin的结构潜在空间适合于视觉理解,可以用于视频内容分析和理解任务。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











