
波恩大学、拉马尔机器学习与人工智能研究所和哈利法大学的研究人员推出新型视频语言模型Video-Panda,这是一个无需编码器(encoder-free)的方法,用于理解和生成与视频内容相关联的语言描述。这种方法引入了一种新颖的时空对齐模块(STAB),直接处理视频输入,无需预训练编码器,且仅使用4500万参数进行视觉处理——相比传统方法至少减少了6.5倍。例如,我们有一个视频,内容是一个人在厨房里制作巧克力蛋糕。Video-Panda能够理解视频中的动作和事件,并回答关于这个视频的问题,如“视频中的人在做什么?”或者“他们使用的原料有哪些?”。
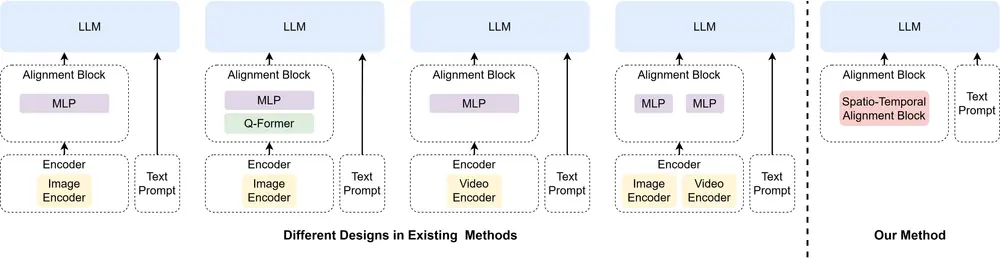
主要功能
- 视频语言理解:Video-Panda能够处理视频输入,并理解视频中的空间和时间信息,以回答有关视频的问题。
- 无需预训练编码器:它不依赖于重量级的图像或视频编码器,这减少了模型参数数量和计算负担。
主要特点
- 参数效率:Video-Panda仅使用45M参数进行视觉处理,比传统方法减少了至少6.5倍。
- 性能竞争:在开放性视频问答任务中,其性能与基于编码器的方法相当或更优。
- 快速处理:处理速度比之前的方法快3-4倍。
核心创新
- 局部时空编码(LSTE):通过3D卷积建模时空关系,并添加3D卷积动态位置编码(DPE)以捕捉局部时空窗口内的位置信息。
- 全局时空关系聚合器(GSTRA):捕捉视频级别的上下文信息。
- 帧内空间关系聚合器(FSRA):捕捉每帧内的空间上下文信息。
- 局部空间下采样(LSD):通过学习注意力机制和独立机制,高效地对空间维度进行下采样,减少计算成本。
- 可学习的加权融合:将视频级上下文标记与帧内空间标记线性结合,生成帧特定的上下文标记,保留全局上下文和空间结构。
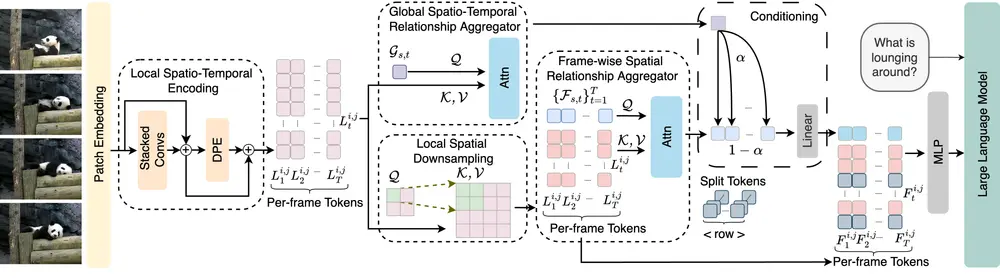
工作原理
Video-Panda的核心是一个名为Spatio-Temporal Alignment Block (STAB)的模块,它直接处理视频输入,而不需要预训练的编码器。STAB结合了以下几个关键组件:
- 局部时空编码(LSTE):在小的时空窗口内编码局部信息。
- 全局时空关系聚合器(GSTRA):捕获整个视频的时空关系。
- 帧级空间关系聚合器(FSRA):捕获每一帧内的空间关系。
- 局部空间下采样(LSD):通过自适应下采样减少每个token的空间维度,降低计算成本。
性能表现
我们的模型在标准基准测试中的开放式视频问答任务上表现优异,与基于编码器的方法(如Video-ChatGPT和Video-LLaVA)相比,在正确性和时间理解等关键方面表现更佳。广泛的消融实验验证了我们架构设计的有效性,同时实现了比之前方法快3-4倍的处理速度。
模型规模与性能对比
在MSVD-QA数据集上,我们的模型在视觉组件参数规模(对数尺度)与性能的对比中表现突出。图中气泡大小表示微调数据量(以千为单位)。使用与我们相同训练数据集(10万样本)的模型以深绿色显示,使用不同数据集的模型以蓝色显示。通过引入STAB模块,我们的方法在视频-语言理解任务中实现了高效且高性能的解决方案,为未来的多模态研究提供了新的方向。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











