
腾讯AI实验室和ARC实验室共同开发的多模态基础模型SEED-X,这是一个先进的人工智能系统,它结合了视觉和语言理解的能力,可以处理和生成各种类型的数据,包括图像和文本。简单来说,SEED-X就像一个多才多艺的助手,能够理解你给它的图片和文字信息,然后根据这些信息做出回应,比如生成新的图像或者提供有用的建议。

主要功能和特点:
- 多模态理解与生成:SEED-X能够理解不同尺寸和比例的图像,并且能够生成不同细节级别的图像,这使得它能够处理从高级的指令性图像生成到低级别的图像编辑等多种任务。
- 统一的模型架构:SEED-X通过集成两种增强功能——任意尺寸和比例的图像理解以及多粒度的图像生成——成为一个统一且多功能的基础模型。
- 指令调优:SEED-X可以通过不同的指令调优来适应现实世界中的各种应用场景,如交互式设计、个人助理、幻灯片制作和虚拟试穿等。
- 公共基准测试的竞争力:SEED-X在公共基准测试中取得了有竞争力的结果,并在图像生成方面达到了最先进的水平。
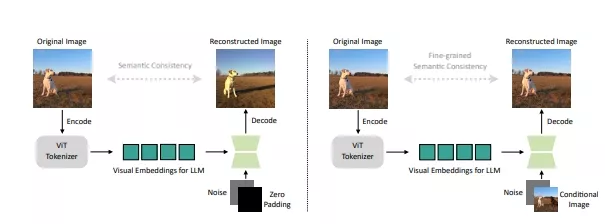
工作原理:
SEED-X的工作原理涉及几个关键步骤:
- 视觉分词与反分词:使用预训练的视觉分词器(如ViT)将图像转换为特征,然后通过一个可学习的模块(如U-Net)将这些特征转换回图像。
- 动态分辨率图像编码:SEED-X能够处理任意大小和宽高比的图像,这是通过将图像分割成多个子图像并为每个子图像添加可扩展的2D位置嵌入来实现的。
- 多模态预训练和指令调优:SEED-X在大量多模态数据上进行预训练,然后在特定任务的数据集上进行调优,以适应不同的指令和应用场景。
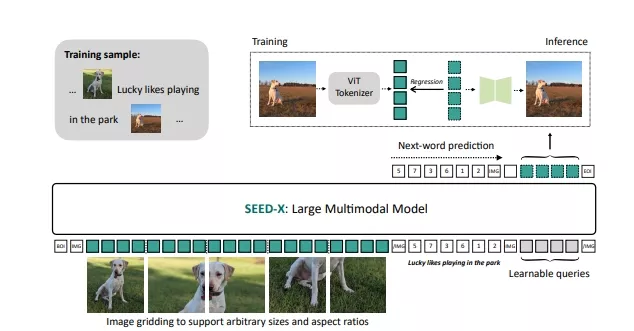
具体应用场景:
- 交互式设计:SEED-X可以根据用户的设计意图生成图像,并提供修改建议和可视化展示。
- 个人助理:SEED-X能够理解各种尺寸的图像,并根据图像内容提供相关建议,如识别冰箱中适合减肥的食物。
- 图像生成与编辑:SEED-X可以根据文本描述生成图像,或者根据指令对现有图像进行编辑,如在图片中添加或删除特定元素。
- 幻灯片制作:SEED-X能够生成幻灯片布局和内容,帮助用户创建演示文稿。
- 虚拟试穿:SEED-X可以帮助用户在虚拟环境中试穿衣服,提供个性化的时尚建议。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











