近年来,文本到视频生成技术取得了显著进展,但现有的视频字幕生成方法仍然存在一些问题:
- 细节不足:传统的视频字幕往往缺乏对视频中物体和场景的细粒度描述,导致生成的视频在细节上不够丰富。
- 幻觉现象:由于模型在生成字幕时可能会引入不准确或虚构的内容,导致生成的视频与原始视频不符,影响了视频的真实性和一致性。
- 运动描述不准确:现有方法在描述物体的运动轨迹和动态变化时表现不佳,难以捕捉视频中的复杂运动模式。
这些问题限制了文本到视频生成技术的应用范围,尤其是在需要高保真度和一致性的场景中。
InstanceCap:实例感知结构化字幕框架
为了解决上述问题,南京大学、字节跳动和南开大学的研究人员提出了一种新颖的 实例感知结构化字幕框架,称为 InstanceCap。该框架首次实现了 实例级 和 细粒度 的视频字幕生成,显著提升了字幕与视频之间的一致性和保真度。
- GitHub:https://github.com/NJU-PCALab/InstanceCap
- 数据:https://huggingface.co/datasets/AnonMegumi/InstanceVid
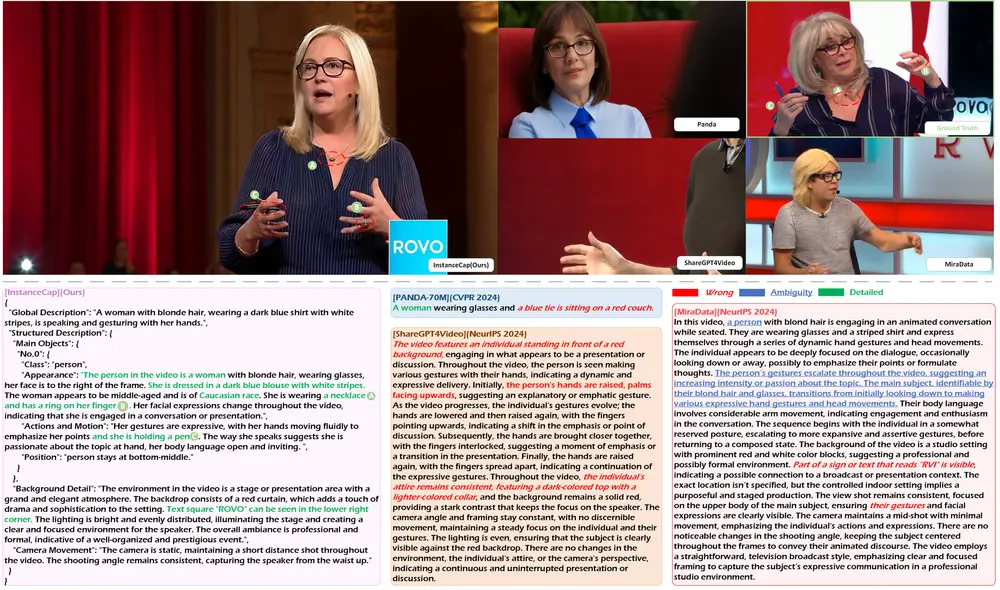
例如,考虑一个视频,其中一位女士穿着蓝条纹衬衫正在发表演讲。传统的字幕可能会简单地描述为“一位女士在说话”,而InstanceCap能够生成更加详细和准确的描述,如“一位穿着蓝条纹衬衫的金发女士,戴着眼镜,正在发表演讲,她的手势富有表现力”。
主要贡献
实例感知字幕生成:
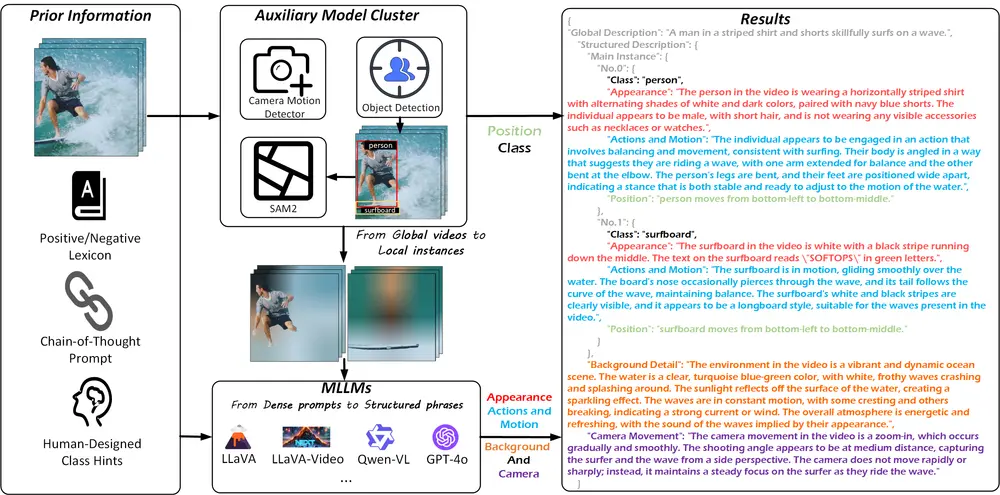
- 实例提取:InstanceCap 通过一个辅助模型集群将原始视频转换为 实例,即视频中的每个物体或场景元素。这些实例不仅包括物体的类别信息,还包括其位置、形状、颜色等属性。
- 结构化短语生成:基于提取的实例,InstanceCap 将密集提示(如物体的属性和运动)精炼为 结构化短语,从而生成简洁而精确的字幕。这种结构化短语能够更好地描述视频中的物体及其动态变化,确保字幕的细粒度和准确性。
增强推理管道:
- 为了进一步提升字幕的质量,研究人员设计了一个 增强推理管道,该管道能够在生成过程中动态调整字幕的结构和内容,减少幻觉现象并提高字幕与视频的一致性。
- 该推理管道还能够处理复杂的运动场景,确保生成的字幕能够准确描述物体的运动轨迹和动态变化。
InstanceVid 数据集:
- 研究人员构建了一个包含 22K 样本 的 InstanceVid 数据集,专门用于训练 InstanceCap 模型。该数据集不仅提供了高质量的视频-字幕配对,还包含了详细的实例标注,使得模型能够在训练过程中学习到更丰富的物体和场景信息。
- InstanceVid 数据集的多样性涵盖了多种场景和物体类型,确保了模型在不同应用场景中的泛化能力。
主要功能和特点
- 实例感知的结构化字幕:InstanceCap能够为视频中的每个实例(如人物、物体)生成详细的描述,包括类别、外观、动作、运动和位置。
- 辅助模型集(AMC):为了从原始视频中分离出实例并获取相应的位置和类别信息,论文设计了一个辅助模型集。
- 改进的Chain-of-Thought(CoT)过程:利用多模态大型语言模型(MLLMs)来精炼密集的提示,生成简洁而精确的描述。
工作原理
InstanceCap的工作原理包括以下几个步骤:
- 视频预处理:使用辅助模型集对视频进行处理,包括对象检测、视频实例分割和相机运动预测。
- 全局描述、背景细节和相机运动:通过CoT方法引导MLLMs生成视频内容的高级概述,同时捕获环境背景和相机运动。
- 实例的结构化描述:将全局视频分解为局部实例,并为每个实例生成详细和准确的描述。
实验结果
实验结果表明,InstanceCap 在多个基准测试中显著优于现有的视频字幕生成模型,具体表现为:
- 高保真度:InstanceCap 生成的字幕与视频内容高度一致,能够准确描述视频中的物体及其动态变化,减少了幻觉现象。
- 细粒度描述:通过实例感知和结构化短语生成,InstanceCap 能够提供更加详细和精确的字幕,捕捉到视频中的微小细节。
- 运动描述准确性:InstanceCap 在描述物体的运动轨迹和动态变化方面表现出色,能够捕捉到复杂的运动模式,提升了生成视频的连贯性和真实感。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...