
当企业级大语言模型(LLM)在回答“iPhone 15 的电池容量是多少?”或“标准 NDA 条款包含哪些内容?”这类问题时,它正在动用为复杂推理设计的昂贵 GPU 计算资源——仅仅为了检索一段静态信息。这种现象每天发生数百万次,造成大量计算周期的浪费,并推高基础设施成本。
DeepSeek 近期发布的 “条件记忆”(Conditional Memory) 研究,直指这一架构性缺陷。其核心成果 Engram 模块,通过将静态模式检索与动态推理解耦,重新定义了模型内部如何处理“已知事实”。
该论文由 DeepSeek 创始人梁文锋合著,不仅提出新架构,更挑战了神经网络中“记忆”本质的传统认知。
问题根源:Transformer 缺乏“原生查找”能力
当前主流 Transformer 架构没有内置的“知识查找”原语。面对如 “Diana, Princess of Wales” 这样的命名实体,模型必须通过多层注意力机制和前馈网络,逐步“拼凑”出其身份——本质上是用动态计算模拟静态检索。
“这就像用计算器来记你的电话号码,而不是直接查通讯录。”
—— DeepSeek 研究团队
结果:本可在 O(1) 时间内完成的哈希表查找,被转化为高成本的神经计算,造成GPU 周期的无声流失。
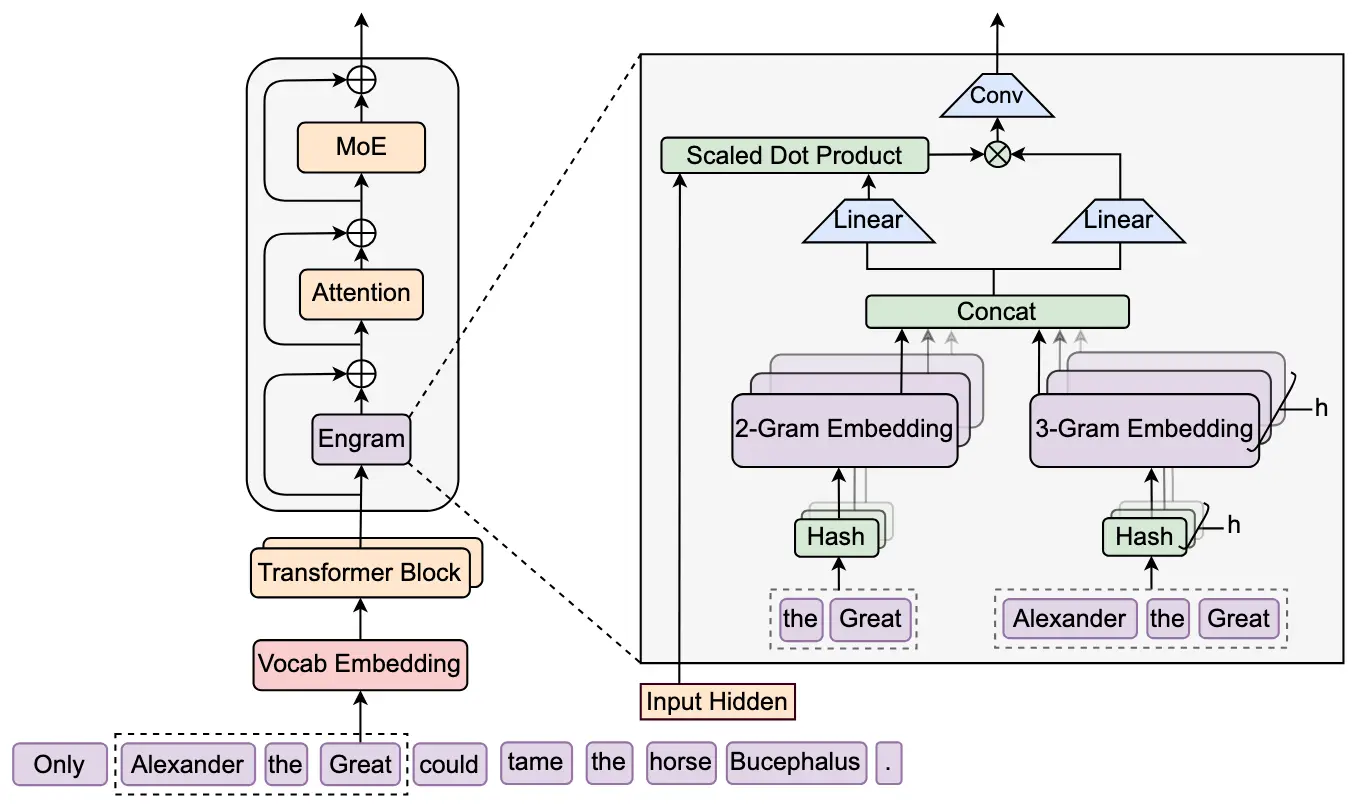
Engram 如何工作:条件记忆 + 门控过滤
Engram 引入一种新型模块,与 MoE(混合专家)协同工作,但聚焦于静态知识:
- 快速检索
接收 2–3 个 token 的短序列(如 “Apple Inc.”),通过哈希函数在超大嵌入表(可达百亿参数)中进行常数时间查找。 - 上下文门控
检索结果需经门控机制过滤:利用模型前期注意力层积累的上下文理解,判断“Apple”是指公司还是水果。若冲突则抑制,匹配则注入后续计算。 - 战略性部署
模块仅部署在特定 Transformer 层,平衡性能增益与延迟开销。
关键发现:75/25 的最优分配
通过系统实验,DeepSeek 发现稀疏模型容量的最佳分配比例为:
- 75% 用于动态推理
- 25% 用于静态记忆
这一比例下,模型表现全面超越纯计算架构(100% MoE):
| 任务类型 | 基线准确率 | Engram 提升后 |
|---|---|---|
| 复杂推理(BBH, ARC, MMLU) | 70% | 74% |
| 知识问答 | 57% | 61% |
意外发现:推理能力的提升幅度甚至超过知识检索本身,表明高效记忆释放了更多计算资源用于真正需要推理的任务。
基础设施革命:GPU 内存旁路
Engram 最具实用价值的创新在于其基础设施感知设计:
- 检索索引与输入绑定:哈希仅依赖 token 序列,具有确定性,支持预取与异步加载。
- GPU-CPU 协同:百亿参数的嵌入表可完全卸载至主机 DRAM,推理时通过 PCIe 异步拉取。
- 通信隐藏:利用早期 Transformer 层的计算作为缓冲,掩盖内存访问延迟。
实测:在将 1000 亿参数嵌入表移出 GPU 后,吞吐量损失低于 3%。
“Engram 的巧妙之处在于:主模型留在 GPU,而‘知识仓库’放在便宜的 CPU 内存中,按需调用。”
—— Chris Latimer,Vectorize CEO(Hindsight 开发者)
对企业 AI 部署的三大启示
- 混合架构优于纯计算
75/25 分配定律表明,未来高效模型必然是“计算+记忆”的混合体。 - 成本重心可能转移
若 Engram 架构规模化可行,企业可减少对昂贵 HBM GPU 的依赖,转而投资大容量系统内存,实现更高性价比。 - 记忆的价值被低估
静态知识模块不仅提升检索准确率,更释放推理潜力——这是传统 RAG 或智能体记忆无法做到的。
与现有方案的本质区别
| 方案 | 目标 | 作用层级 | 是否优化模型内部计算 |
|---|---|---|---|
| RAG | 外部知识增强 | 输入/输出层 | ❌ |
| 智能体记忆(如 Hindsight) | 跨会话上下文保持 | 外部存储 | ❌ |
| Engram 条件记忆 | 优化模型内部静态模式处理 | 模型前向传播中 | ✅ |
未来展望
DeepSeek 的研究揭示:下一代 AI 的突破点不在“更大”,而在“更聪明的架构”。尊重“静态知识”与“动态推理”的根本差异,构建混合系统,可能是突破 GPU 内存瓶颈、降低企业 AI 成本的关键路径。
对于尚未大规模部署 AI 的组织,应密切关注主流模型厂商是否采纳“条件记忆”原则。若 75/25 分配定律具有普适性,下一代基座模型或将实现更低硬件成本下的更强推理能力——这不仅是技术演进,更是企业 AI 经济模型的转折点。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











