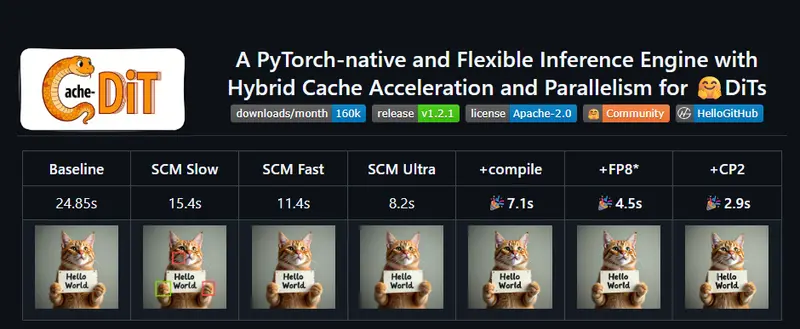
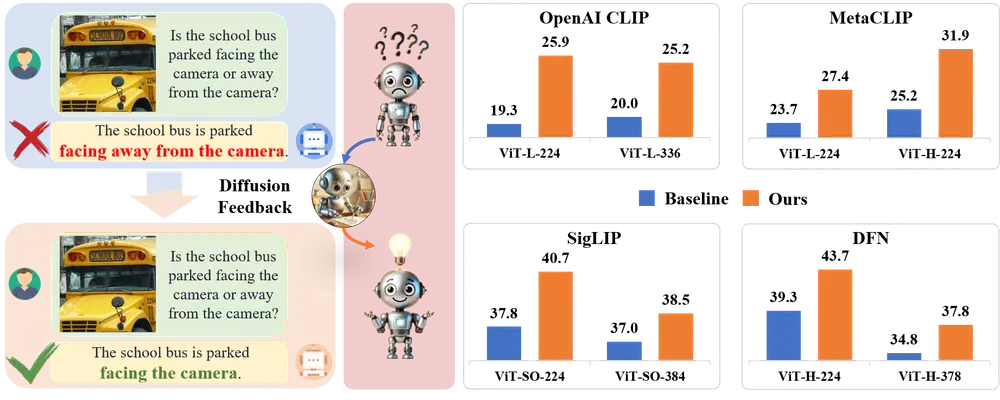
Cache-DiT是一款基于PyTorch原生构建的灵活推理引擎,核心目标是为Diffusers库提供统一的缓存加速与并行化支持,无需重新训练模型,仅需一行代码就能显著提升DiT类扩散模型的推理速度。它支持几乎所有DiT模型(目前已兼容70+个,包括Qwen-Image-Lightning、FLUX、Z-Image等),还集成了混合缓存、多维度并行化等多种优化,同时支持HTTP服务部署,兼顾易用性与高性能,是大型DiT模型落地的高效工具。
为什么选择Cache-DiT?核心优势全覆盖,兼顾性能与灵活
Cache-DiT构建于Diffusers库之上,并非简单的提速工具,而是一套完整的DiT模型推理优化框架,核心优化点覆盖缓存加速、并行化、部署、兼容性四大维度,能解决大型DiT模型推理慢、显存不足、部署复杂等痛点:
- 混合缓存加速:集成DBCache、DBPrune、TaylorSeer等多种缓存策略,无需改动模型结构,直接降低推理计算量,提升出图/生成速度;
- 多维度并行化能力:针对大型DiT模型深度优化,支持多种并行方式,彻底解决显存OOM与推理卡顿问题:
- 上下文并行化(支持Ulysses、Ring、USP等,含FP8通信优化)
- 张量并行化(基于PyTorch原生DTensor/TP API,原生适配)
- 混合2D/3D并行化(USP+TP组合,大幅提升大型DiT模型性能)
- 配套组件并行化(文本编码器TE-P、自动编码器VAE-P、ControlNet CN-P,全方位优化推理链路)
- 易部署、高兼容:内置HTTP服务部署支持,提供简洁REST API,可快速落地文生图、图像编辑等场景;同时原生兼容PyTorch Compile、Offloading、量化等功能,还能集成vLLM-Omni、SGLang Diffusion等工具;
- 多硬件支持:除了NVIDIA GPU,还原生支持Ascend NPU(≥1.2.0版本),适配更多生产环境;
- 极致易用:无需复杂配置,一行代码即可启用核心加速功能,新手也能快速上手,同时支持自定义配置,满足高级优化需求。
最新动态:持续迭代,功能不断完善
Cache-DiT保持高频更新,不断扩展兼容范围与优化性能,近期核心版本更新亮点如下:
- v1.2.1(2026/02):新增批处理P2P的Ring Attention、USP(混合Ring与Ulysses),优化混合2D/3D并行化,降低VAE-P通信开销,进一步提升大型模型推理效率;
- v1.2.0(2026/01,稳定版):新增Z-Image、FLUX.2、LTX-2等模型支持,增加请求级别缓存上下文、HTTP服务,完善Ulysses Anything、TE-P/VAE-P/CN-P并行化,首次支持Ascend NPU。
快速上手:两步安装,一行代码启用加速
Cache-DiT的使用门槛极低,支持PyPI快速安装与源码安装,启用加速仅需一行核心代码,后续调用与原生Diffusers Pipeline完全一致。
步骤1:安装Cache-DiT
两种安装方式可选,新手优先选择PyPI安装,需要最新功能可选择源码安装:
# 方式1:PyPI快速安装(稳定版,推荐)
pip3 install -U cache-dit
# 方式2:源码安装(获取最新功能,适合开发者)
pip3 install git+https://github.com/vipshop/cache-dit.git
步骤2:启用加速,多种配置按需选择
安装完成后,导入工具并加载Diffusers Pipeline,即可通过cache_dit.enable_cache()启用加速,支持多种配置组合,满足不同场景需求。
场景1:最简用法,一行代码启用默认缓存加速
import cache_dit
from diffusers import DiffusionPipeline
# 加载任意DiT扩散模型(以Qwen-Image为例)
pipe = DiffusionPipeline.from_pretrained("Qwen/Qwen-Image")
# 一行代码启用缓存加速,使用默认配置
cache_dit.enable_cache(pipe)
# 像往常一样调用pipeline,推理速度已显著提升
output = pipe("生成一张蓝天白云的风景图")
场景2:启用混合缓存加速 + 1D并行化(Ulysses)
import cache_dit
from diffusers import DiffusionPipeline
from cache_dit import DBCacheConfig, ParallelismConfig
pipe = DiffusionPipeline.from_pretrained("Qwen/Qwen-Image")
# 启用混合缓存+Ulysses上下文并行(ulysses_size=2)
cache_dit.enable_cache(
pipe,
cache_config=DBCacheConfig(), # 启用默认混合缓存配置
parallelism_config=ParallelismConfig(ulysses_size=2) # 配置1D上下文并行
)
output = pipe("生成一张复古风格的海报")
场景3:仅启用分布式推理,不使用缓存加速
import cache_dit
from diffusers import DiffusionPipeline
from cache_dit import ParallelismConfig
pipe = DiffusionPipeline.from_pretrained("Qwen/Qwen-Image")
# 仅启用上下文并行化,不开启缓存加速
cache_dit.enable_cache(
pipe,
parallelism_config=ParallelismConfig(ulysses_size=2)
)
output = pipe("生成一张科幻风格的城市夜景")
场景4:启用混合缓存加速 + 2D并行化(Ulysses+TP)
import cache_dit
from diffusers import DiffusionPipeline
from cache_dit import DBCacheConfig, ParallelismConfig
pipe = DiffusionPipeline.from_pretrained("Qwen/Qwen-Image")
# 启用混合缓存+2D并行(ulysses_size=2 + tp_size=2)
cache_dit.enable_cache(
pipe,
cache_config=DBCacheConfig(),
parallelism_config=ParallelismConfig(ulysses_size=2, tp_size=2) # 2D并行(上下文+张量)
)
output = pipe("生成一张水墨风格的山水画")
场景5:从自定义YAML文件加载配置(高级用法)
import cache_dit
from diffusers import DiffusionPipeline
from cache_dit import load_configs
pipe = DiffusionPipeline.from_pretrained("Qwen/Qwen-Image")
# 从自定义yaml配置文件加载缓存与并行化配置
cache_dit.enable_cache(pipe, **load_configs("config.yaml"))
# 可选:设置注意力后端,进一步优化性能
cache_dit.set_attn_backend(pipe, attention_backend="flash_attention_2")
output = pipe("生成一张卡通风格的小猫图片")
快速链接:获取更多详情与示例
想要探索更多高级功能、落地部署或排查问题,可参考官方提供的核心资源:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...