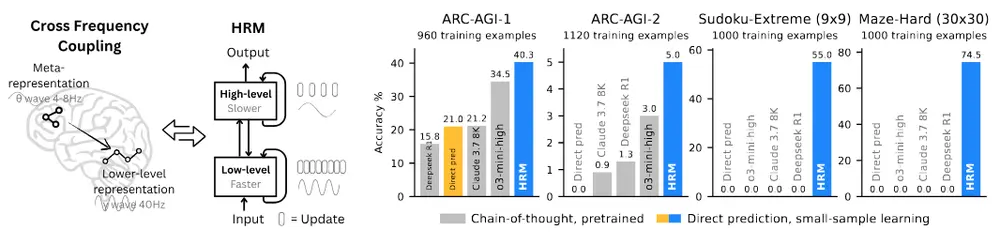
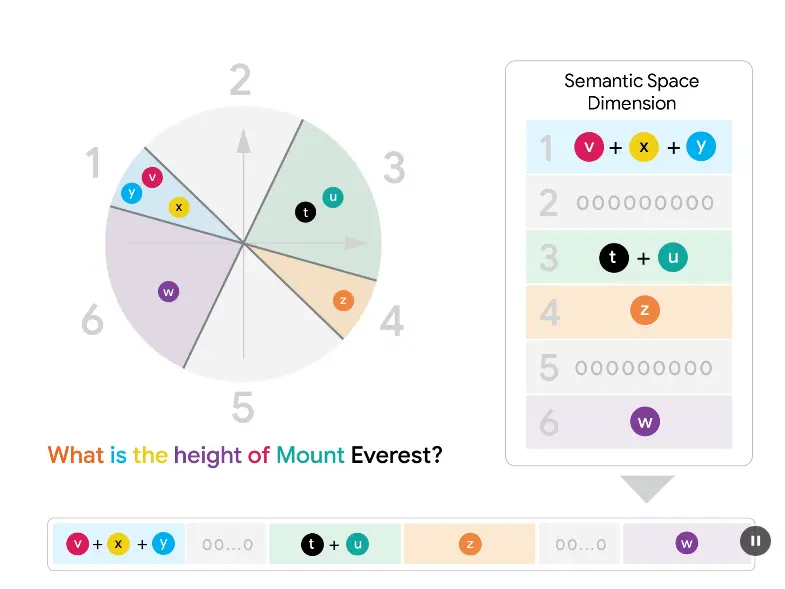
一种更接近人类思维的推理模型架构HRM在AI领域,“推理”始终是衡量智能水平的核心指标。真正的推理,不只是回答问题,而是设计并执行通向目标的复杂行动序列——就像人在解一道数独时,会先观察整体格局,再逐步填入数字;在走迷宫时,会先判断大致方...新技术# HRM# 推理模型架构9个月前02870
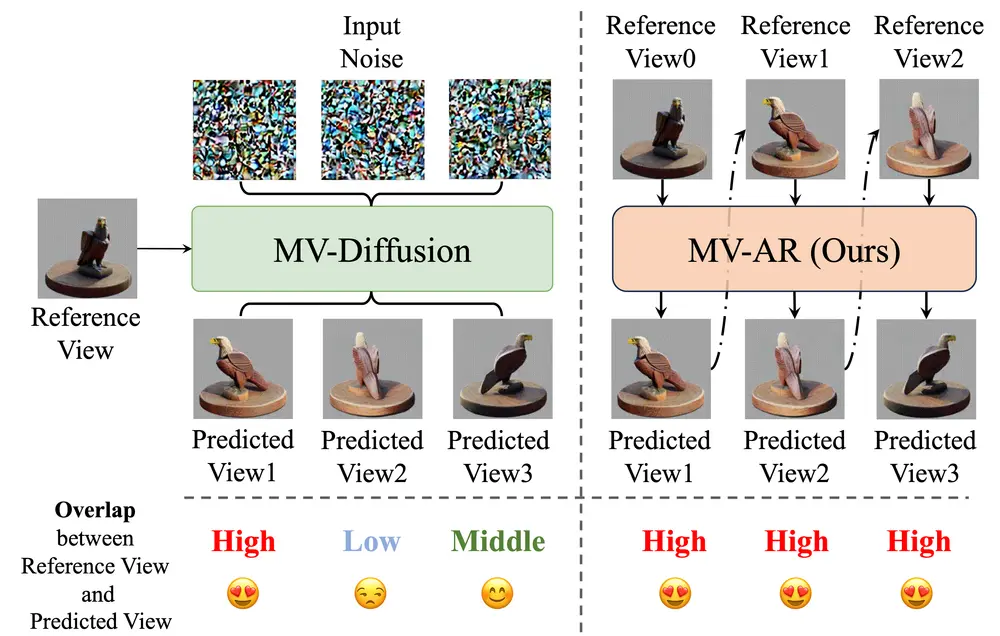
自回归生成多视图图像方法 MVAR:从人类指令(如文本、参考图像和几何形状)生成多视角一致的图像北京大学医学技术研究所、百度视觉、北京大学未来技术学院生物医学工程系、北京大学国家生物医学影像中心和清华大学的研究人员开发了一种自回归生成多视图图像的方法 MVAR 。其目的是确保在生成当前视图的过程...新技术# MVAR# 多视图9个月前01750
CanonSwap:通过规范空间调制实现高保真且一致的视频人脸交换在AI与计算机视觉领域,视频人脸交换(Video Face Swapping)是一项极具挑战性的任务。它不仅要将一个人的身份特征“移植”到另一段视频中,还要保持目标人物的表情、动作和口型等动态信息不变...新技术# CanonSwap# 视频换脸9个月前02130
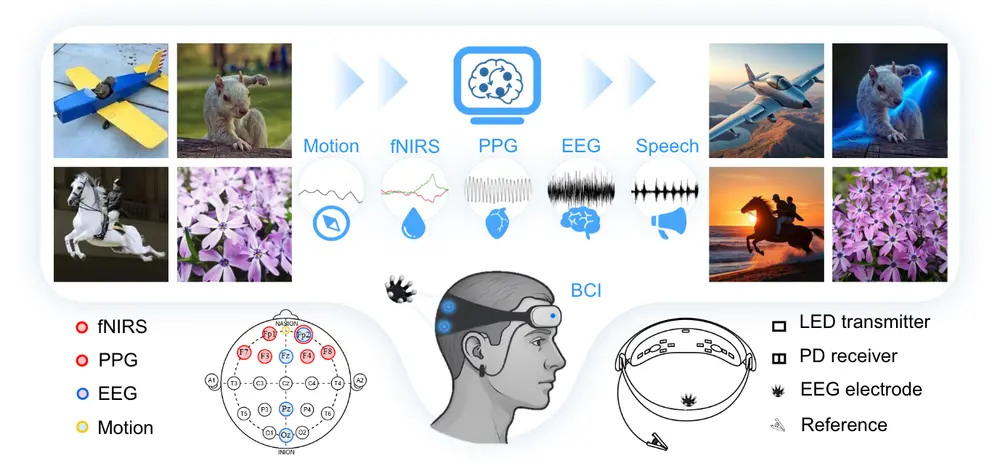
LoongX:基于多模态神经信号驱动的无接触图像编辑新范式由新加坡国立大学、浙江大学、罗切斯特理工学院、南京大学、中国科学技术大学、曼苏里大学人工智能学院、上海人工智能实验室和SII联合提出的新方法 LoongX,首次将多模态脑机接口(BCI)信号引入扩散模...新技术# LoongX# 图像编辑9个月前02970
AI2推出一种全新的语言模型协作训练范式FlexOlmo由 AI2(Allen Institute for AI) 推出的 FlexOlmo,正在重新定义语言模型的训练方式。 它提出了一种名为“数据协作”的新范式,让多个数据拥有者在不共享原始数据的前提下...新技术# Ai2# FlexOlmo9个月前04310
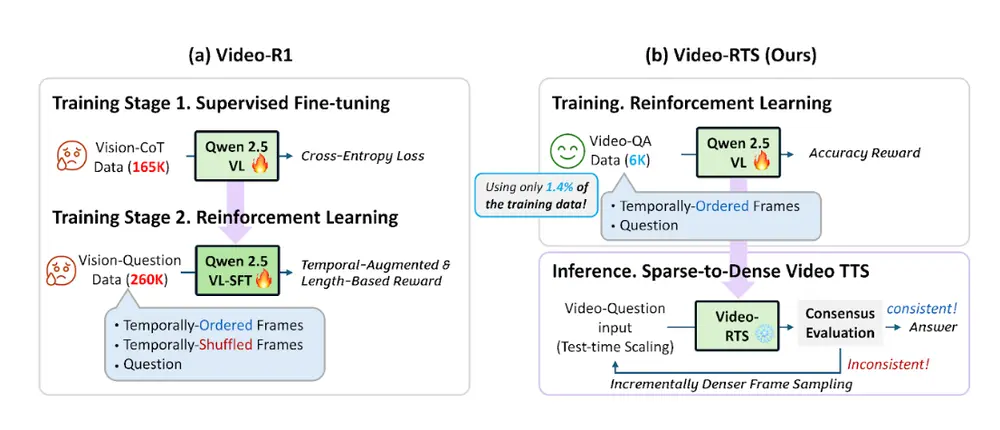
Video-RTS:一种高效视频推理框架,用强化学习+动态推理策略打破数据依赖北卡罗来纳大学教堂山分校的研究人员提出了一种全新的视频推理方法——Video-RTS(Reinforcement Learning with Test-time Scaling),旨在解决当前视频理解...新技术# Video-RTS# 视频推理框架9个月前01680
通用图像超分辨率智能体4KAgent:将任意类型的低分辨率图像(包括自然图像、卫星图像、医学图像、AI生成内容等)提升至4K分辨率德克萨斯农工大学、斯坦福大学、科罗拉多大学博尔德分校、德克萨斯大学奥斯汀分校、加州理工学院、加州大学默塞德分校、Snap公司和Topaz Labs公司的研究人员推出通用图像超分辨率智能体4KAgent...新技术# 4KAgent# 图像超分辨率9个月前02000
X-Planner:基于 MLLM 的图像编辑任务规划系统,让复杂指令也能精准执行在图像编辑领域,用户常常需要执行诸如“将这张照片转换为赛博朋克风格”或“让图中的动物看起来像是在庆祝圣诞节”这样的复杂操作。这些任务不仅要求模型理解抽象指令,还需准确定位并修改图像中的特定区域。 然而...新技术# X-Planner# 图像编辑9个月前03610
MUVERA:让多向量检索像单向量一样快的新一代高效算法在 RAG(Retrieval-Augmented Generation)系统中,信息检索是决定整体性能的关键环节。传统的单向量搜索(如基于 ElasticSearch 或 FAISS 的 MIPS...新技术# MUVERA# 向量检索9个月前04370
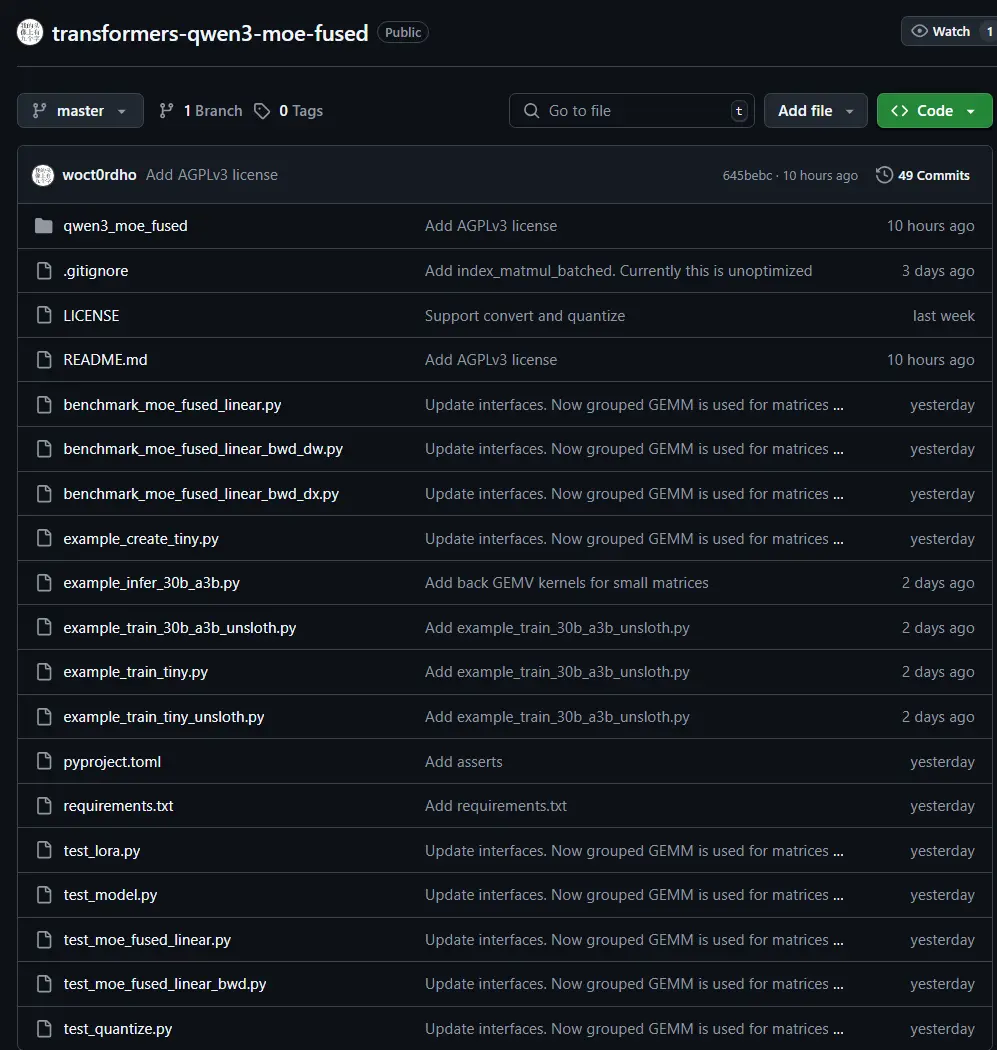
Qwen3 MoE Fused:显著提升 Qwen3 推理速度的融合专家计算方案Qwen3 MoE Fused 是一个面向 Qwen3 MoE 模型 的高性能推理优化项目,由开发者 woct0rdho 发起并实现。该项目通过重构 MoE(Mixture of Experts)中专...新技术# Qwen3 MoE Fused9个月前04240
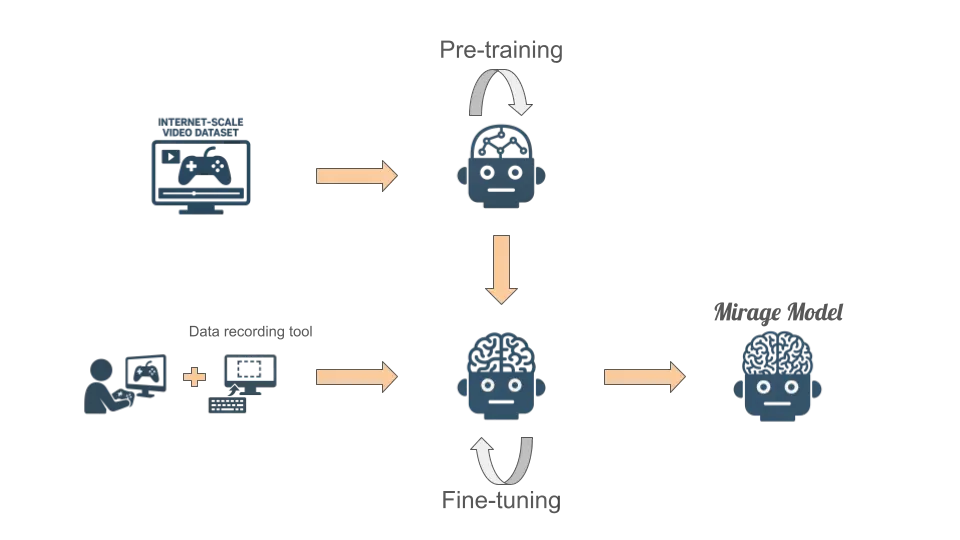
Dynamics Lab 发布全球首个 AI 原生 UGC 游戏引擎 Mirage游戏的未来不再依赖专业设计师逐帧构建,而是由每一位玩家通过想象、生成与体验来共同塑造。 今天,Dynamics Lab 正式推出 Mirage —— 全球首个AI原生、实时生成的用户生成内容(UGC...新技术# Dynamics Lab# Mirage9个月前05590
字节跳动Pico团队推出新型框架EX-4D:从单目视频生成高质量的极端视角 4D 视频字节跳动Pico团队推出新型框架EX-4D,旨在从单目视频生成高质量的极端视角 4D 视频。该框架通过深度防水网格(Depth Watertight Mesh, DW-Mesh)表示法,有效处理边界遮...新技术# EX-4D# 字节跳动9个月前03470