Self-Forcing++:一种无需长视频训练即可生成高质量长视频的新方法近年来,扩散模型在图像和短片视频生成方面取得了突破性进展。然而,当扩展到长视频生成(如数十秒甚至数分钟)时,现有方法普遍面临一个核心问题:质量随长度增加而显著下降。 这主要源于两个限制: 计算成本高...新技术# Self Forcing# 字节跳动6个月前03290
英伟达推出LONGLIVE:单卡实现实时交互式长视频生成AI生成视频正从“几秒特效”迈向“分钟级叙事”。 长期以来,生成高质量、长时间连贯的视频是AI内容创作的一大瓶颈。传统扩散模型虽能产出精美画面,却难以支持实时生成;自回归方法虽具备推理加速潜力,又常因...新技术# LONGLIVE# 英伟达6个月前01950
用 Wi-Fi 信号生成房间图像?LatentCSI 结合 AI 实现高分辨率空间重建东京科学研究所的研究团队近日提出一种新方法——LatentCSI,能够利用日常 Wi-Fi 设备采集的无线信号,结合预训练扩散模型,生成高分辨率的室内布局图像。 论文地址:https://arxiv...新技术# LatentCSI6个月前02130
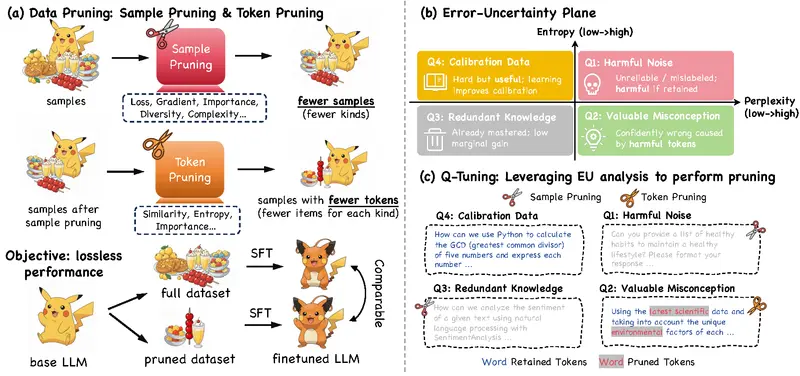
Q-Tuning:用“错误-不确定性”框架统一剪枝,提升微调效率监督微调(SFT)正变得越来越重。 过去,SFT 只是大模型训练流程中的一个轻量级收尾步骤;如今,它已演变为一场计算密集型任务,其数据规模和训练成本常常逼近中期预训练阶段。在有限算力预算下,如何高效利...新技术# Q-Tuning6个月前01510
Rolling Forcing:一种用于长视频生成的新型自回归扩散方法在构建交互式世界模型、神经游戏引擎和沉浸式 XR 应用的道路上,一个核心挑战始终存在:如何实时生成高质量、时间连贯的长视频流? 当前主流的自回归视频生成方法虽能产出单段短片,但在生成多分钟连续视频时...新技术# Rolling Forcing# 长视频生成6个月前01730
SageAttention3 发布:FP4 推理加速与 8 位训练新探索清华大学研究团队近日推出 SageAttention3,一项聚焦于提升 Transformer 注意力机制效率的新研究成果。该工作在推理阶段引入基于 FP4 的微缩放量化技术,并首次系统性探索了 8 ...新技术# SageAttention3# 清华大学6个月前01290
Windows ML 现已可用:让 AI 应用更高效运行在你的电脑上微软宣布,其 Windows ML 平台现已正式进入生产可用状态,面向所有运行 Windows 11 24H2 及以上版本的设备开放。这一进展标志着 Windows 在本地 AI 能力上的关键落地...新技术# Windows ML7个月前01170
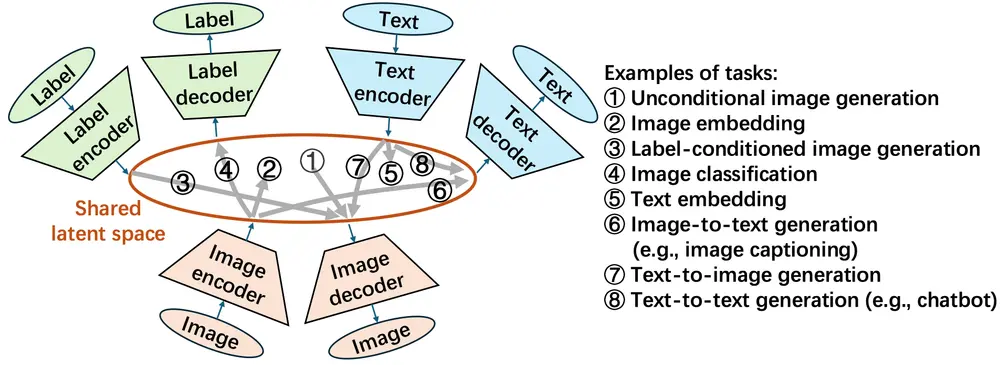
潜在分区网络(LZN):以共享高斯潜在空间,统一生成、表示与分类的机器学习新框架在机器学习领域,生成模型(如 DALL・E 生成图像、ChatGPT 生成文本)、表示学习(如 CLIP 实现图文表示匹配)、分类模型(如 ResNet 进行图像分类)是三大核心方向,且各自都已取得成...新技术# LZN# 潜在分区网络7个月前01230
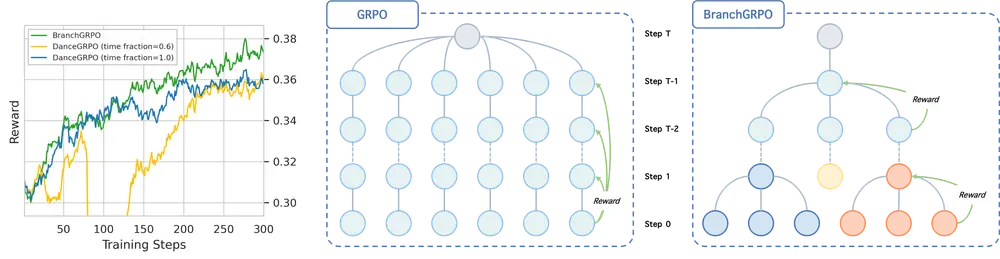
BranchGRPO:树状分支重构,破解GRPO图像视频生成对齐的效率与稳定性难题在图像、视频生成领域,“让模型输出与人类偏好对齐”是关键目标——无论是生成符合审美标准的图像,还是帧间连贯的视频,都需要通过算法优化缩小模型输出与人类期望的差距。群体相对策略优化(GRPO)是近年常用...新技术# BranchGRPO7个月前01020
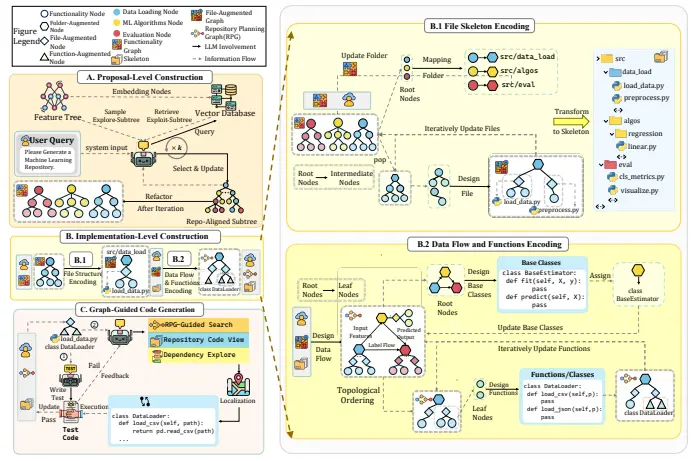
RPG:一种用于统一且可扩展代码库生成的存储库规划图微软、清华大学和加州大学圣地亚哥分校的研究人员推出一个名为 Repository Planning Graph (RPG) 的框架,用于从头开始生成完整的软件仓库。它通过将软件的功能规划和实现规划统一...新技术# RPG# 代码库生成7个月前01430
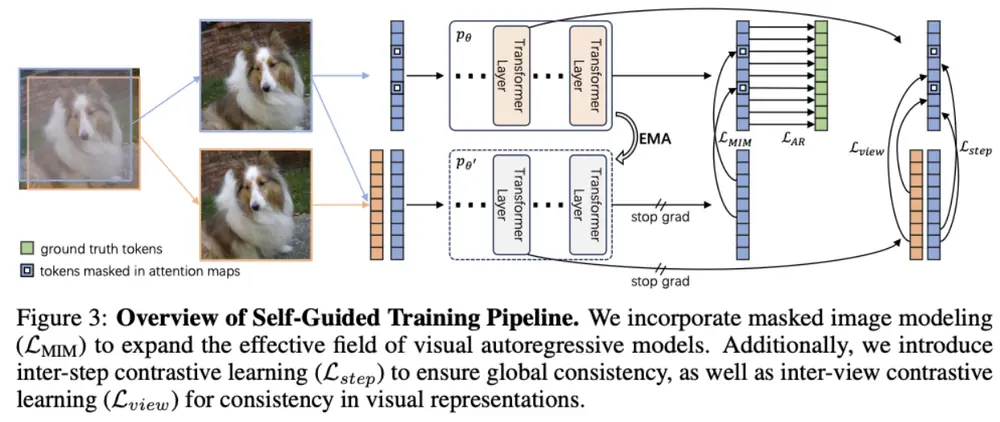
ST-AR:让自回归图像生成学会“先理解,再生成”自回归模型(Autoregressive, AR)因其强大的序列建模能力,最初在自然语言处理中取得成功,随后被引入图像生成领域。这类模型将图像视为“视觉词元”序列,通过逐个预测 token 的方式重建...新技术# ST-AR# 自回归图像生成7个月前02420
局部性从何而来?MIT与丰田研究所揭示扩散模型中的数据驱动机制在图像生成领域,扩散模型已成为主流架构之一。其训练过程基于一个理论上的“最优去噪器”——即在给定噪声水平下,能够最小化重建误差的理想函数。有趣的是,这一最优解虽然数学上可定义,却只能复现训练集中的样本...新技术# 图像扩散模型7个月前0820