自回归模型(Autoregressive, AR)因其强大的序列建模能力,最初在自然语言处理中取得成功,随后被引入图像生成领域。这类模型将图像视为“视觉词元”序列,通过逐个预测 token 的方式重建图像,在 LlamaGen、ImageGPT 等工作中展现了高质量生成潜力。
然而,直接迁移文本建模范式到视觉任务面临本质挑战:图像不仅是局部像素的堆叠,更是具有全局语义和空间结构的复杂实体。现有自回归图像生成模型普遍存在三类问题:
- 过度依赖局部与条件信息,忽视图像整体语义;
- 生成过程中不同时间步的特征不一致,导致语义漂移;
- 对图像旋转、裁剪等空间变换缺乏鲁棒性。
为解决这些问题,来自上海人工智能实验室、悉尼大学、香港中文大学与香港大学的研究团队提出 ST-AR(Self-guided Training for AutoRegressive models) ——一种全新的训练框架,旨在让模型在“生成前先学会理解”。
核心思想:用自监督提升模型的“视觉理解力”
传统自回归训练仅优化“下一个 token 预测”目标,这种学习信号高度局部化,难以驱动模型建立深层次的语义表征。ST-AR 的核心创新在于:在不改变推理流程的前提下,在训练阶段引入多个自监督学习目标,引导模型主动构建对图像内容的理解能力。
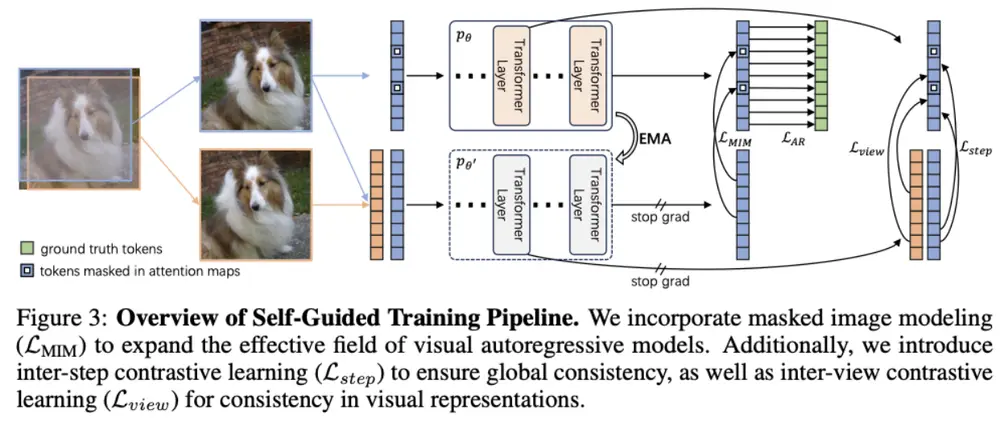
这种方法无需额外预训练模型,也不改变采样策略,即可显著提升模型对全局结构和语义一致性的把握。
三大机制协同作用
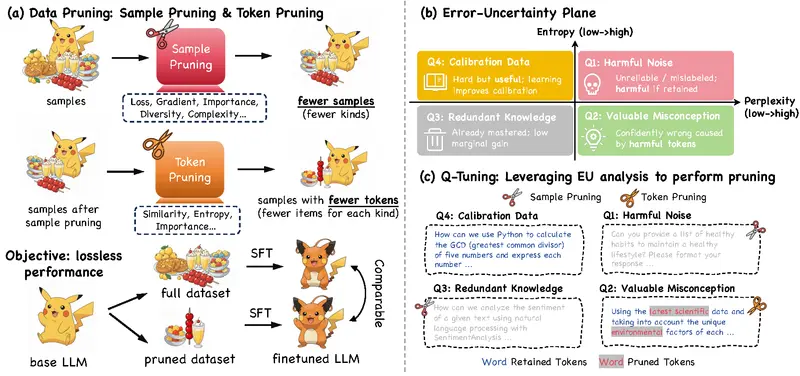
ST-AR 通过三种互补的自监督任务联合优化模型表示能力:
1. 掩码图像建模(Masked Image Modeling, MIM)
在注意力图上随机掩码部分视觉 token,要求模型根据上下文恢复被遮蔽区域的内容。这一机制迫使模型跳出局部滑动窗口式的依赖,扩大有效感受野,增强对长距离语义关系的捕捉能力。
类似于 BERT 的 MLM 任务,但应用于视觉 token 序列。
2. 时间步对比损失(Inter-step Contrastive Loss)
自回归生成是逐步展开的过程,不同时间步的隐藏状态应共同服务于同一语义目标。为此,ST-AR 引入对比学习机制,拉近同一图像在不同生成步骤中的特征表示,抑制中间表征的语义漂移。
解决“边想边改”的问题,确保生成过程语义连贯。
3. 视图对比损失(Inter-view Contrastive Loss)
对输入图像进行多种数据增强(如旋转、缩放、色彩扰动),并要求模型在不同视图下提取出一致的特征表达。该损失增强了模型对几何变换的不变性,提高其空间鲁棒性。
让模型学会“无论怎么看,这都是同一张图”。
这些目标与原有的下一 token 预测损失共同优化,形成多任务学习框架,在训练中同步提升生成能力与理解能力。
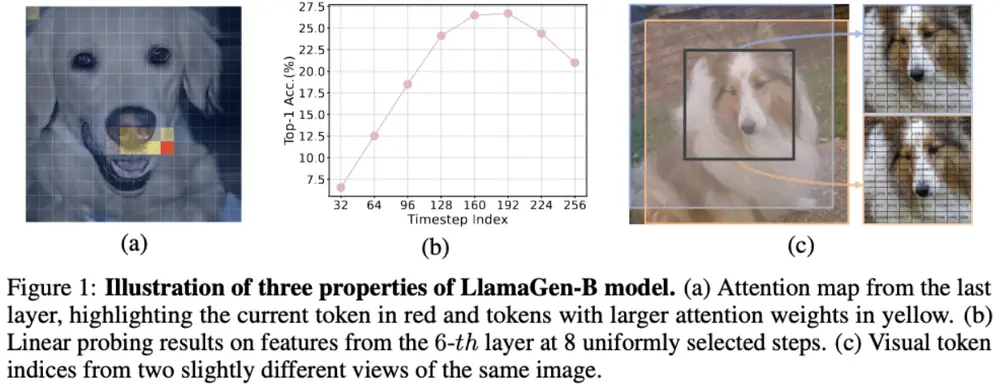
实验验证:理解提升带来生成飞跃
研究团队在 LlamaGen 系列模型上全面验证了 ST-AR 的有效性。
✅ 图像理解能力显著增强
在 ImageNet 上进行线性探测(Linear Probing)评估,结果表明:
- LlamaGen-B 的线性分类准确率从 21.00% 提升至 55.23%
- 特征质量接近专用视觉编码器水平
说明模型学到的表示具备更强的语义判别能力。
✅ 图像生成质量大幅提升
在类条件图像生成任务中,FID 分数(越低越好)显著下降:
- LlamaGen-L:FID 下降约 42 → 最终达 7.x 水平
- LlamaGen-XL:FID 从 19.42 降至 9.81(训练50轮)
- 经完整训练后,其表现甚至优于参数量大四倍的 LlamaGen-3B 模型
这意味着:更小的模型 + 更短的训练周期 = 更优的生成效果。
所有实验均保持相同的采样策略与推理流程,证明性能提升完全源于训练机制改进。
关键特性与优势
| 特性 | 说明 |
|---|---|
| 无需外部预训练模型 | 不依赖 CLIP 或 DINO 等固定权重的视觉编码器,降低部署复杂度 |
| 兼容现有架构与流程 | 推理时仍为标准自回归解码,可无缝集成到多模态系统中 |
| 轻量级改造,高效训练 | 自监督目标仅作用于训练阶段,计算开销可控,易于复现 |
此外,ST-AR 兼容多种自回归结构,已在 Transformer-based 图像生成器上验证有效,具备良好的泛化性。
应用场景展望
得益于其强语义理解能力和生成一致性,ST-AR 可广泛适用于以下方向:
- 高质量图像生成:艺术创作、虚拟环境构建、游戏素材生成等需要高保真输出的场景;
- 多模态建模:结合语言模型实现图文联合生成、视觉问答、图像描述生成等任务;
- 数据增强:生成语义一致但细节多样的新样本,用于小样本或长尾类别学习;
- 下游视觉任务初始化:提供高质量的视觉表示,作为分类、检测等任务的预训练基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...