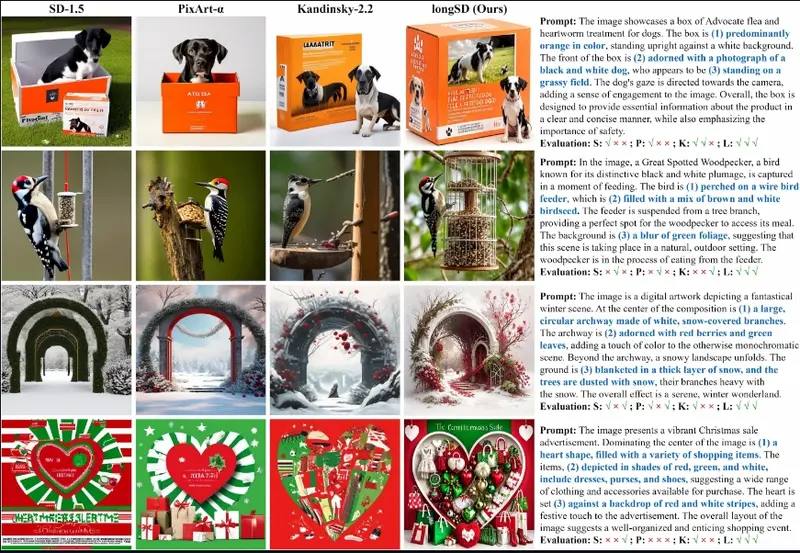
LongAlign:改进文生图模型的长文本对齐文生图模型的快速发展使它们能够从给定的文本生成前所未有的结果。然而,随着文本输入变长,现有的编码方法如 CLIP 面临限制,并且将生成的图像与长文本对齐变得具有挑战性。为了解决这些问题,香港大学、新加...新技术# LongAlign# 文生图模型# 长文本对齐1年前08160
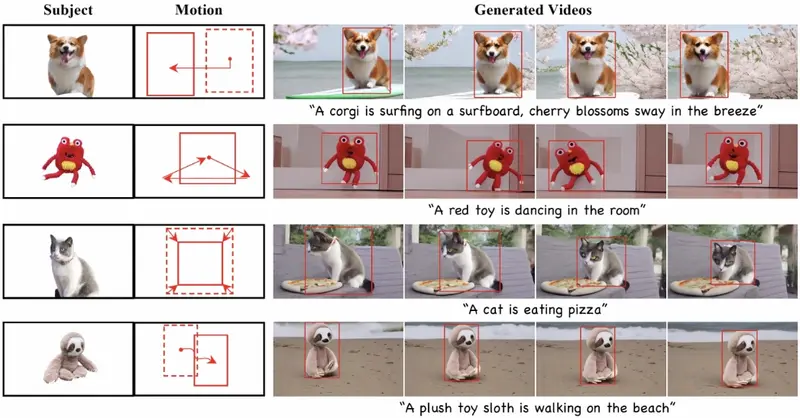
零样本视频定制框架DreamVideo-2:根据单一图像和一系列界定框序列生成具有特定主题和运动轨迹的视频复旦大学、阿里巴巴、南洋理工大学和密歇根州立大学的研究人员推出一个零样本视频定制框架DreamVideo-2,能够根据单一图像和一系列界定框(bounding box)序列生成具有特定主题和运动轨迹的...新技术# DreamVideo-2# 视频定制1年前06700
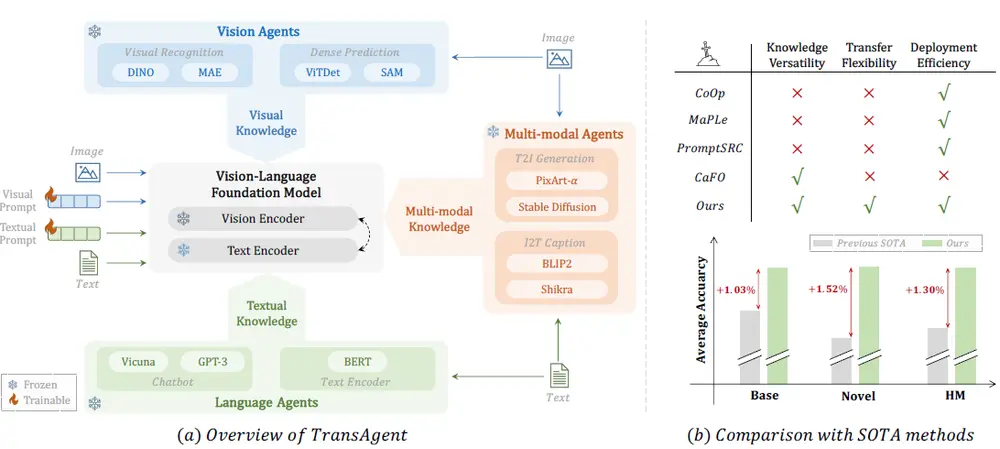
TransAgent 框架:提升视觉-语言基础模型(比如CLIP)在新领域中的泛化能力中国科学院深圳先进技术研究院、中国科学院大学、上海人工智能实验室和上海交通大学的研究人员推出一个通用且简洁的 TransAgent 框架,它的目标是提升视觉-语言基础模型(比如CLIP)在新领域中的泛...新技术# CLIP模型# TransAgent 框架1年前04900
条件对比对齐CCA:提升自回归(AR)视觉生成模型的样本质量无分类器引导(CFG)是提高视觉生成模型样本质量的关键技术。然而,在自回归(AR)多模态生成中,CFG 在语言和视觉内容之间引入了设计不一致性,这与统一不同模态的视觉 AR 设计理念相矛盾。受语言模型...新技术# CCA# 条件对比对齐# 视觉生成模型1年前06090
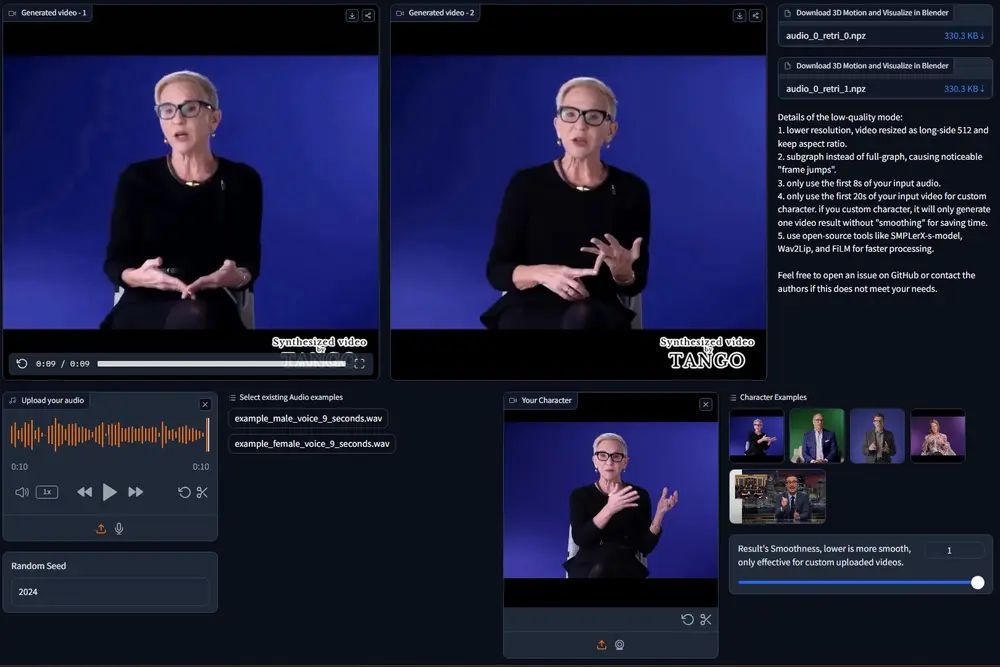
用于生成同步语音体态手势视频的框架 TANGO:把新的语音和已有的视频动作结合起来,生成高保真的、与语音同步的身体手势视频东京大学和CyberAgent 人工智能实验室的研究人员推出了一个用于生成同步语音体态手势视频的框架 TANGO,它可以从一个几分钟长的参考视频(里面有一个说话者的身体动作)和目标语音音频出发,生...新技术# TANGO# 同步语音体态手势1年前04090
Fluid: 基于连续令牌和随机顺序生成的文生图模型在视觉领域,自回归模型的扩展并没有像在大语言模型中那样取得显著的成功。为了探索这一问题,Google DeepMind 和麻省理工学院的研究人员进行了一项研究,重点探讨了两个关键因素:模型是使用离散还...新技术# Fluid:# 文生图模型1年前04660
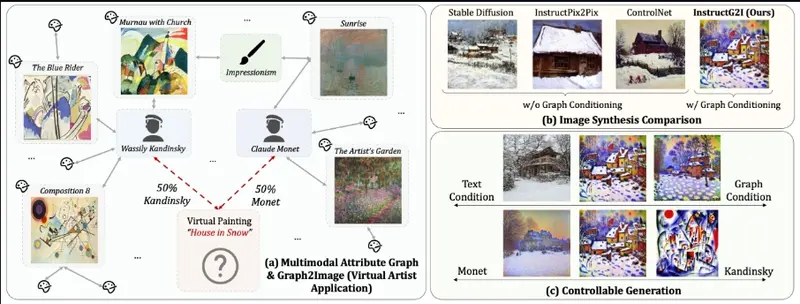
图上下文感知扩散模型InstructG2I:根据多模态属性图(MMAGs)生成图像多模态属性图(MMAGs)作为一种强大的数据结构,能够以图的形式表示实体之间的关系,节点中包含图像和文本信息。尽管 MMAGs 在图像生成中具有多功能性,但它们受到的关注相对较少。这是因为 MMAGs...新技术# InstructG2I# 多模态属性图1年前06140
图像编辑新方法DICE:用于改进离散扩散模型在可控编辑任务中的性能罗格斯大学、麻省理工学院-IBM Watson AI 实验室、谷歌 DeepMind、NEC 美国实验室、纽约大学、 沃尔玛全球科技公司、澳大利亚国立大学和 麻省理工学院阿灵顿分校的研究人员推出图像编...新技术# DICE# 图像编辑1年前06050
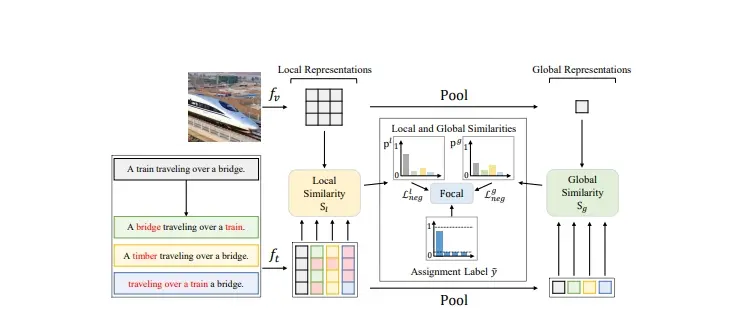
FSC-CLIP:提升预训练视觉和语言模型(VLMs)在理解图像和文字组合任务上的能力,同时保持在多模态任务上的性能韩国科学技术院、世宗大学和汉阳大学的研究人员推出FSC-CLIP,提升预训练视觉和语言模型(VLMs)在理解图像和文字组合任务上的能力,同时保持在多模态任务上的性能。简单来说,就是让计算机能够更好地理...新技术# FSC-CLIP# 多模态1年前05190
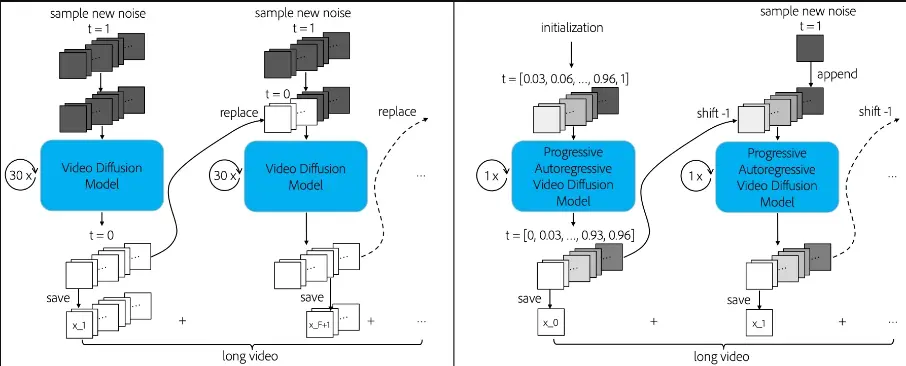
长视频生成新方法PA-VDM:现有的模型可以自然地扩展为自回归视频扩散模型,而无需改变架构石溪大学和Adobe 研究中心的研究人员推出长视频生成新方法PA-VDM,它能够生成高质量的长视频。在解释这个主题时,我们可以把它想象成一个能够将静态图片或简短视频变成长篇电影的魔法盒子。 项目主...新技术# PA-VDM# 长视频生成1年前06200
基于Transformer架构的新型图像生成模型DART:根据文本描述生成高质量的图像苹果和香港中文大学的研究人员推出新型图像生成模型DART,这个模型的目标是让计算机能够根据文本描述生成高质量的图像。DART是一个基于Transformer架构的模型,它在非马尔可夫框架内统一了自回归...新技术# DART# Transformer架构# 图像生成模型1年前06990
BroadWay:提升文生视频模型的质量,而且不需要额外的训练上海交通大学、中国科学技术大学、香港中文大学和上海人工智能实验室的研究人员推出为BroadWay,它能够提升文生视频模型的质量,而且不需要额外的训练。这就像是给视频生成模型安装了一个“涡轮增压器”,让...新技术# BroadWay# 文生视频模型1年前07810