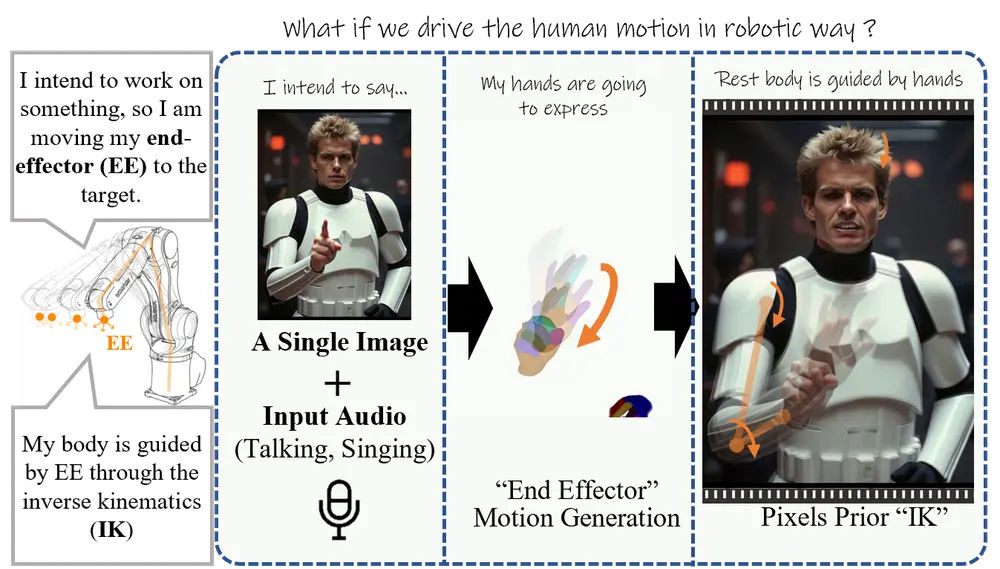
阿里推出新型音频驱动的虚拟角色视频生成方法EMO2:同时生成富有表现力的面部表情和手势动作阿里在去年2月推出新型音频驱动的虚拟角色视频生成方法EMO,近期又发布了 EMO2,它能够同时生成富有表现力的面部表情和手势动作。该方法特别关注于语音伴随手势(co-speech gestures)的...新技术# EMO21年前06400
新型多模态大语言模型INF-LLaVA:专门设计用于处理高分辨率图像,以提高模型对视觉和语言信息的理解能力厦门大学的研究人员推出新型多模态大语言模型INF-LLaVA,它专门设计用于处理高分辨率图像,以提高模型对视觉和语言信息的理解能力。在人工智能领域,处理高分辨率图像一直是一个挑战,因为这些图像包含的细...新技术# INF-LLaVA# 多模态大语言模型2年前06400
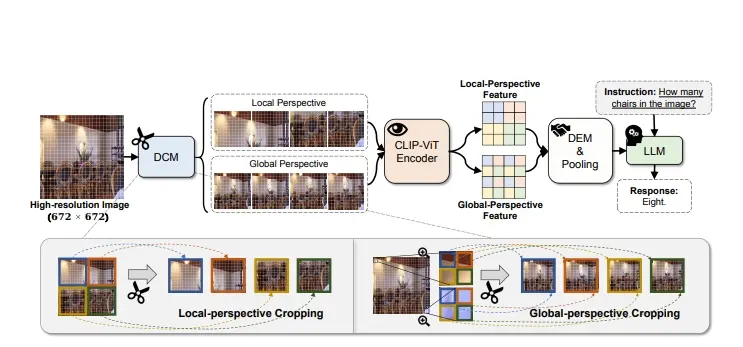
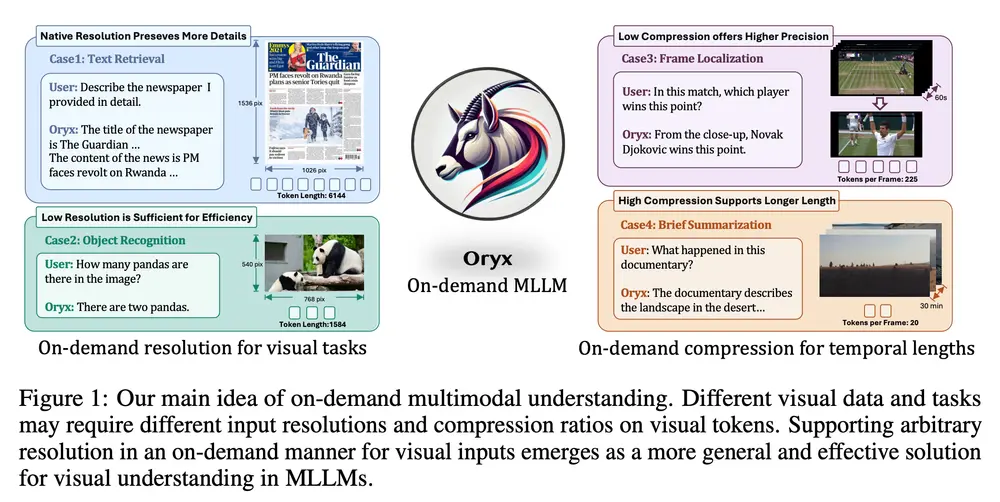
多模态大语言模型Oryx:专门设计用于理解和处理视觉数据,如图像、视频和3D场景清华大学、腾讯和南洋理工大学 S-Lab的研究人员推出多模态大语言模型Oryx,它专门设计用于理解和处理视觉数据,如图像、视频和3D场景。Oryx模型的特点是能够根据需要处理任意空间大小和时间长度的视...新技术# Oryx# 多模态大语言模型2年前06390
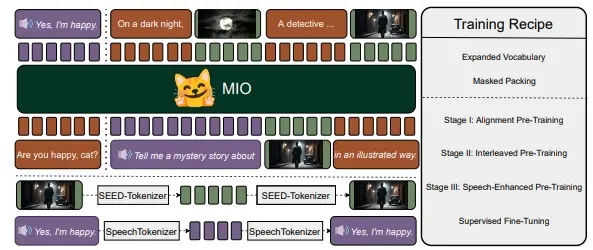
基于多模态token的新型基础模型MIO:能够以端到端、自回归的方式理解和生成语音、文本、图像和视频北京航空航天大学、01.AI、香港理工大学、AIWaves、阿尔伯塔大学、滑铁卢大学、曼彻斯特大学、中国科学院自动化研究所、北京大学和香港科技大学的研究人员推出一个基于多模态token的新型基础模型M...新技术# MIO# 多模态2年前06380
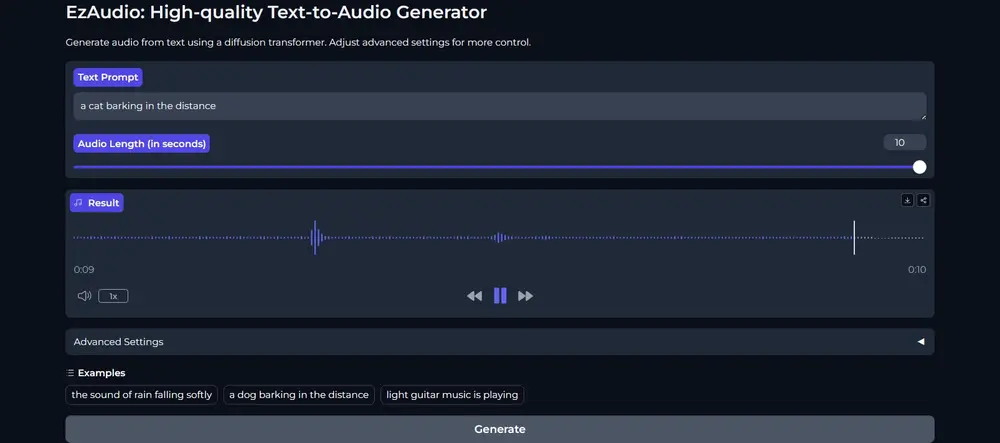
新型高品质文本音频生成器EzAudio:将文本描述转换成相应的音频内容约翰·霍普金斯大学和腾讯人工智能实验室的研究人员推出一种新型的文本到音频(Text-to-Audio,简称T2A)生成技术EzAudio,这项技术的目标是将文本描述转换成相应的音频内容,比如将“一只狗...新技术# EzAudio# 文本音频生成器2年前06370
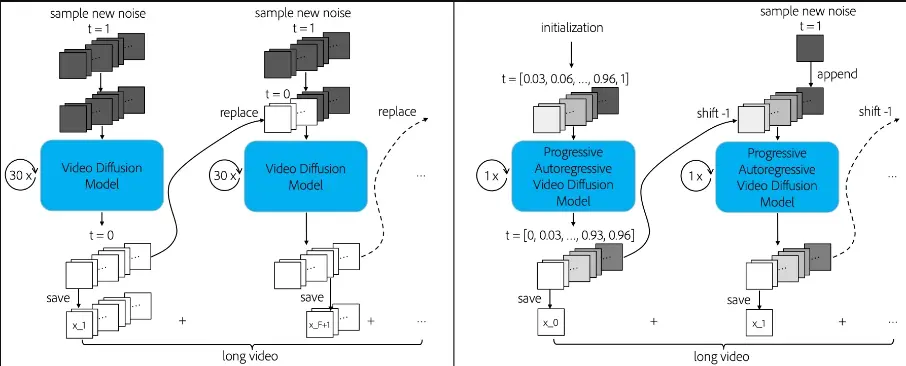
长视频生成新方法PA-VDM:现有的模型可以自然地扩展为自回归视频扩散模型,而无需改变架构石溪大学和Adobe 研究中心的研究人员推出长视频生成新方法PA-VDM,它能够生成高质量的长视频。在解释这个主题时,我们可以把它想象成一个能够将静态图片或简短视频变成长篇电影的魔法盒子。 项目主...新技术# PA-VDM# 长视频生成2年前06340
新型文本到音频生成模型Tango 2:提高音频生成的质量和与文本的匹配度新加坡科技设计大学和密歇根大学的研究人员推出新型文本到音频生成模型Tango 2,它通过直接偏好优化(Direct Preference Optimization, DPO)来提高音频生成的质量和与文...新技术# Tango 2# 文本到音频生成模型2年前06330
文本反转Textual Inversion:通过少量的图像和自然语言描述来创建新的“伪词”来指导图像生成使用文本到图像生成模型(Text-to-Image Models)来个性化地创造图像,这些模型能够根据自然语言描述生成图像,但通常难以精确地表达特定的独特概念。 项目主页 GitHub 来自特拉维夫大...新技术# Textual Inversion# 文本反转# 英伟达2年前06330
无需额外训练的新型过渡视频生成方法TVG:在不同场景或画面之间流畅过渡的视频效果索贝媒体智能实验室、四川大学网络科学与工程学院、数据保护与智能管理教育部重点实验室(四川大学)和中国电子科技大学的研究人员推出一种无需额外训练的新型过渡视频生成方法TVG,它是一种无需训练就能生成平滑...新技术# TVG# 视频生成2年前06300
基于提示、针对文生图模型的新型剪枝方法APTP:减少文生图模型在计算资源受限的环境中部署时的计算负担,同时保持模型性能马里兰大学和佛罗里达州立大学推出一种针对文生图模型的新型剪枝方法APTP(Adaptive Prompt-Tailored Pruning,自适应提示定制剪枝),这是一种专门为文生图模型设计的、基于提...新技术# APTP# 剪枝方法# 文生图模型2年前06300
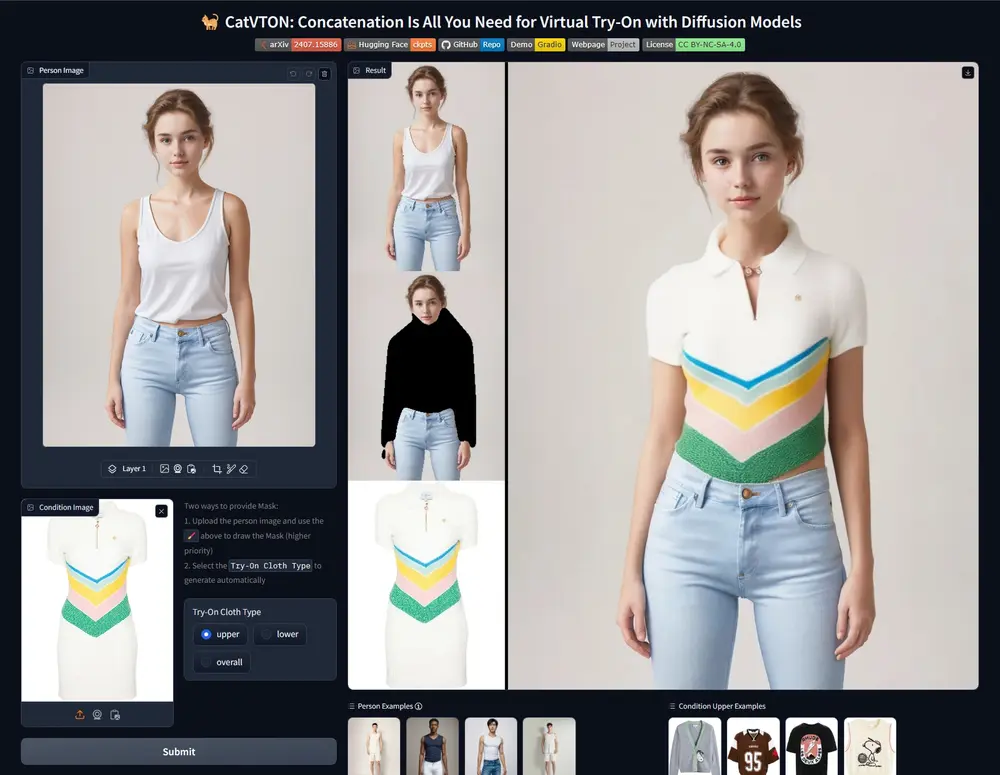
虚拟试穿扩散模型CatVTON:允许用户在不实际穿上衣物的情况下,通过照片来预览衣物穿在身上的效果中山大学、Pixocial Technology、鹏程实验室和中科院深圳先进技术研究院的研究人员推出一种简单高效的虚拟试穿扩散模型CatVTON,它通过将任意类别的商店衣物或已穿戴衣物与目标人物图像在...新技术# CatVTON# 虚拟试穿2年前06290
新型图像编辑框架DesignEdit:实现精确的空间感知图像编辑微软亚洲研究院和北京大学的研究人员推出新型图像编辑框架DesignEdit,它能够实现精确的空间感知图像编辑。开发团队借鉴了设计领域的图层概念,通过灵活应用多种操作来操控图像中的对象。我们的核心思想是...新技术# DesignEdit# 图像编辑2年前06280