英伟达开源ConsiStory:免训练保持角色和物品一致性的文生图方法来自特拉维夫大学和英伟达的研究人员提出了一种创新方法ConsiStory,它允许用户通过自然语言描述生成一系列图像,这些图像不仅能够保持一致的主题,而且能够遵循文本提示。ConsiStory的核心目标...新技术# ConsiStory# 英伟达1年前06280
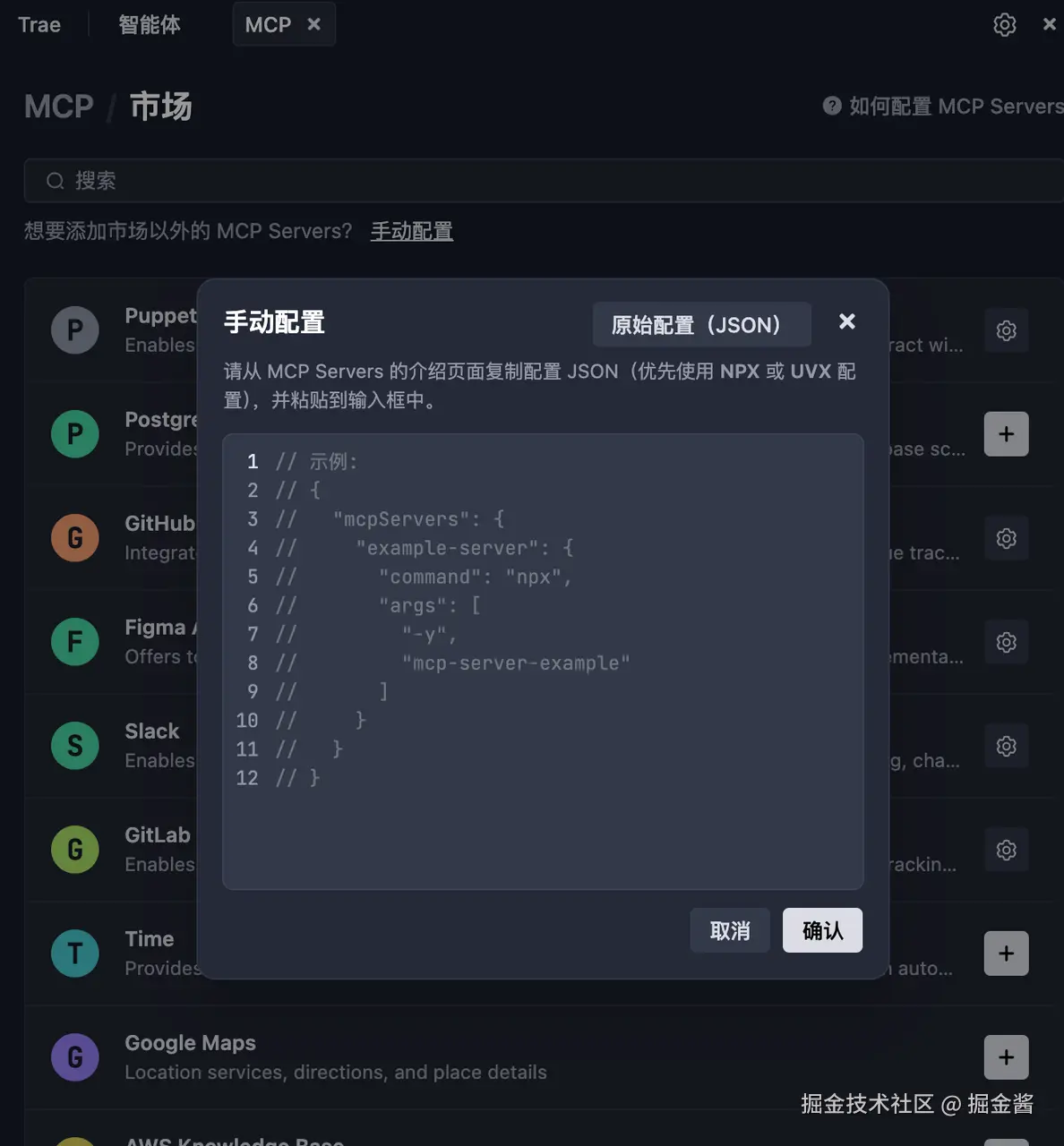
通过 Trae 等 AI IDE 配置 MCP一键发布到掘金的完整指南在开发过程中,我们常常需要将自己制作的小项目(如 HTML/CSS/JS 小游戏、落地页等)快速展示给他人。如果你是掘金用户,并且使用支持 MCP(Model Calling Protocol) 的 ...教程# MCP# Trae# 掘金11个月前06270
用ChatGPT生成个性化微信表情包,简单几步教你玩转创意表达GPT4o的原生图像生成功能,让ChatGPT再次成为网络热点,它允许用户通过简单的文本提示创建高质量图像。从吉卜力风格的壁纸到复杂的图像编辑,这一功能为创意表达带来了无限可能。 目前,ChatGPT...教程# ChatGPT# 微信表情包1年前06270
新型3D重建模型GS-LRM:能够从少数几张2D图像中快速预测出高质量的3D高斯原始体Adobe和康奈尔大学的研究人员推出新型3D重建模型GS-LRM(Gaussian Splatting Large Reconstruction Model),这个模型能够从少数几张2D图像中快速...新技术# 3D重建模型# GS-LRM2年前06270
动态排版Dynamic Typography:将文字通过动画效果生动呈现的技术来自香港科技大学和特拉维夫大学的研究人员推出Dynamic Typography(动态排版),它是一种将文字通过动画效果生动呈现的技术。简单来说,就是让文字动起来,通过变形和运动来表达文字的含义,从而...新技术# Dynamic Typography# 动态排版2年前06270
新型视觉模型训练方法SynCLR:完全从生成模型中学习,不需要任何真实数据来自谷歌和MIT的研究人员提出一种新型视觉模型训练方法SynCLR,它完全从生成模型中学习,而不需要任何真实数据。 GitHub 论文 SynCLR的核心思想是利用大语言模型(LLMs)生成大量的图像...新技术# SynCLR# 大模型# 大语言模型2年前06270
条件对比对齐CCA:提升自回归(AR)视觉生成模型的样本质量无分类器引导(CFG)是提高视觉生成模型样本质量的关键技术。然而,在自回归(AR)多模态生成中,CFG 在语言和视觉内容之间引入了设计不一致性,这与统一不同模态的视觉 AR 设计理念相矛盾。受语言模型...新技术# CCA# 条件对比对齐# 视觉生成模型1年前06260
高度一致且可控制运动的图像动画生成方法Cinemo:将一张静态图片转换成一段视频,并且在转换过程中保持图片原有的细节信息莫纳什大学、上海人工智能实验室和南京邮电大学的研究人员推出Cinemo,它是一种用于图像动画化(也称为图像到视频生成,I2V)的新型方法。简单来说,Cinemo能够将一张静态图片转换成一段视频,并且在...新技术# Cinemo# 图像动画2年前06250
DiPIR:将虚拟对象以逼真的方式插入到真实世界场景的图片或视频中英伟达、多伦多大学和矢量研究所的研究人员推出DiPIR技术,它能够将虚拟对象以逼真的方式插入到真实世界场景的图片或视频中。这项技术的核心在于理解和模拟场景的光照、几何形状和材质,以及图像形成过程,从而...新技术# DiPIR2年前06240
字节跳动推出文生图模型SDXL-Lightning:基于SDXL1.0基础模型提炼SDXL-Lightning是由字节跳动发布的一款速度极快的文生图模型,它采用新型扩散模型蒸馏方法,优化扩散模型,能在短时间内高效生成分辨率为1024像素的高品质图像。 模型地址:https://hu...新技术# SDXL-Lightning# SDXL1.0# 字节跳动2年前06240
运动潜在一致性模型MotionLCM:能够实时控制人体动作的生成来自清华大学和上海人工智能实验室的研究人员推出运动潜在一致性模型MotionLCM,它能够实时控制人体动作的生成。这个框架通过一种称为“潜在一致性模型”(Motion Latent Consisten...新技术# MotionLCM# 运动潜在一致性模型2年前06230
微软发布复现Sora的开源项目:新型多智能体框架Mora来自理海大学和微软研究院的研究团队推出新型多智能体框架Mora,它是为了实现大规模的通用视频生成而设计的。Mora的设计灵感来自于OpenAI在2024年2月推出的Sora模型,Sora是一个能够将文...新技术# Mora# Sora# 微软2年前06230