视觉变换器VisionLLaMA:基于LLaMA架构设计,用于处理图像任务来自美团、浙江大学、Moonshot AI的研究人员推出名为VisionLLaMA的新型视觉变换器(Vision Transformer),它是基于LLaMA(Large Language Model...新技术# VisionLLaMA# 视觉变换器2年前06230
基于Transformer架构的新型视频生成模型Snap Video来自Snap、特伦托大学、加州大学默塞德分校、布鲁诺·凯斯勒基金会的研究人员推出新型视频生成模型Snap Video,此模型基于Transformer架构,目标是将文本描述转换成高质量的视频内容。 项...新技术# Snap Video# Transformer# 视频生成模型2年前06220
FABRIC:改进SD模型的新技术来自瑞士苏黎世联邦理工学院的研究人员提出了一种改进生成模型的技术FABRIC,它可以通过在扩散模型中融入迭代的人类反馈来个性化图像生成。它是一种无需训练的技术,适用于各种流行的SD模型,利用最常用的架...新技术# FABRIC# Stable Diffusion2年前06220
新型图像到视频扩散模型TRIP:专注于将静态图像转换为动态视频来自中国科学技术大学和HiDream.ai的研究人员推出新型图像到视频扩散模型TRIP(Temporal Residual Learning with Image noise Prior),它专注于将...新技术# TRIP# 图生视频2年前06210
新型AI模型PT-DiT:针对文本到任意任务(如文本到图像、文本到视频等)的高效能扩散变换器中山大学 & 360人工智能研究院的研究人员推出一种新的人工智能模型PT-DiT,它是一种针对文本到任意任务(如文本到图像、文本到视频等)的高效能扩散变换器。这个模型特别关注于提高计算效率,减...新技术# PT-DiT# Qihoo-T2X2年前06200
具有光照感知能力的扩散模型Relightful Harmonization来自Adobe和纽约大学的研究人员推出具有光照感知能力的扩散模型Relightful Harmonization,这是一种先进的图像处理方法,专门用于在更换人像照片背景时,保持前景人物与新背景之间的光...新技术# Relightful Harmonization# 光影2年前06200
新型图像编辑框架SEELE:图像主体重新定位来自复旦大学的研究人员推出了一种新型图像编辑框架SEELE(SEgment-gEnerate-and-bLEnd),它专注于在图像中重新定位指定的对象(即“主体”),同时保持图像的整体质量。 项目主页...新技术# SEELE# 图像编辑2年前06200
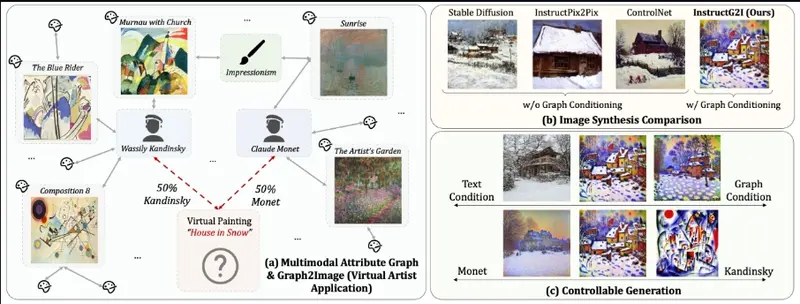
图上下文感知扩散模型InstructG2I:根据多模态属性图(MMAGs)生成图像多模态属性图(MMAGs)作为一种强大的数据结构,能够以图的形式表示实体之间的关系,节点中包含图像和文本信息。尽管 MMAGs 在图像生成中具有多功能性,但它们受到的关注相对较少。这是因为 MMAGs...新技术# InstructG2I# 多模态属性图2年前06190
新型图像生成模型VAR:基于Transformer的自回归模型来自北京大学和字节跳动的研究人员推出新型图像生成模型VAR(Visual Autoregressive Modeling,“视觉自回归建模”),VAR模型是一种基于Transformer的自回归(au...新技术# VAR模型2年前06190
DistriFusion:加速高分辨率扩散模型的并行推理算法来自麻省理工学院、普林斯顿大学、Lepton AI 和 英伟达的研究人员推出DistriFusion,这是一种用于加速高分辨率扩散模型(diffusion models)的并行推理算法。 项目主页 G...新技术# DistriFusion# 高分辨率扩散模型2年前06190
3D场景编辑方法ReplaceAnything3D(RAM3D):通过文本提示在3D场景中替换特定的物体来自Meta、伦敦大学的研究人员推出一种基于文本引导的3D场景编辑方法ReplaceAnything3D(RAM3D),它允许用户通过文本提示在3D场景中替换特定的物体。这种方法结合了预训练的文本引导...新技术# 3D场景编辑# RAM3D# ReplaceAnything3D2年前06190
矩形扩散Rectified Diffusion:提高扩散模型的生成速度香港中文大学、北京大学和普林斯顿大学的研究人员推出Rectified Diffusion,它用于加速生成扩散模型(diffusion models),这些模型在视觉生成领域取得了显著的进展,比如生成高...百科# Rectified Diffusion# 矩形扩散2年前06180