来自瑞士苏黎世联邦理工学院的研究人员提出了一种改进生成模型的技术FABRIC,它可以通过在扩散模型中融入迭代的人类反馈来个性化图像生成。它是一种无需训练的技术,适用于各种流行的SD模型,利用最常用的架构中的自注意层,将扩散过程与一组反馈图像进行条件化。

具体来说,它使用了一种叫做自注意力机制的组件,这个组件能够帮助模型关注到一些特定的参考图像。这些参考图像分为好的(正面的)和不好的(负面的)例子,由人来挑选。通过这种方法,模型在生成图像时能够更好地理解人的喜好,从而生成更符合人期望的图像。
项目主页:https://sd-fabric.github.io
GitHub地址:https://github.com/sd-fabric/fabric
特点:
- 迭代反馈集成:FABRIC允许用户通过多轮生成过程提供正面和负面反馈,从而逐步改进生成的图像。
- 无需额外训练:与需要额外训练的方法不同,FABRIC可以直接应用于现有的扩散模型。
- 自注意力层利用:FABRIC利用扩散模型中的自注意力层来注入参考图像的信息,从而影响生成过程。
- 性能评估:论文提出了一种全面的评价方法,包括使用PickScore(一种基于人类偏好的评分系统)和CLIP相似性度量来量化生成模型的性能。
实现方法:
- 参考图像条件化:FABRIC通过将参考图像的部分噪声化(与当前去噪步骤相匹配),并将其关键特征注入到自注意力层中,来影响生成过程。
- 迭代反馈循环:在每一轮生成中,用户可以选择喜欢和不喜欢的图像,这些图像随后被用作下一轮生成的正面和负面反馈。
- 反馈权重调整:通过调整注意力分数,FABRIC可以在生成过程中强调粗略特征或细节,从而平衡探索和利用。
FABRIC通过结合人类反馈和先进的扩散模型,提供了一种有效的方式来提升图像生成的个性化和质量,同时保持了生成过程的灵活性和用户友好性。
如何使用FABRIC?
目前官方已经释出了DEMO,如果网络环境许可,大家可以进入Hugging Face或Google Colab进行试用,建议大家使用Hugging Face上的Demo。
Hugging Face地址:https://huggingface.co/spaces/dvruette/fabric
Google Colab地址:https://colab.research.google.com/drive/1rWZ4jQHMvjc-l7xYAssa_OUOaAx3XDQT?usp=sharing
官方Demo
使用非常简单,进入该Demo后,填写提示词与反向提示词,其他参数也可进行设置,进行第一次图片生成
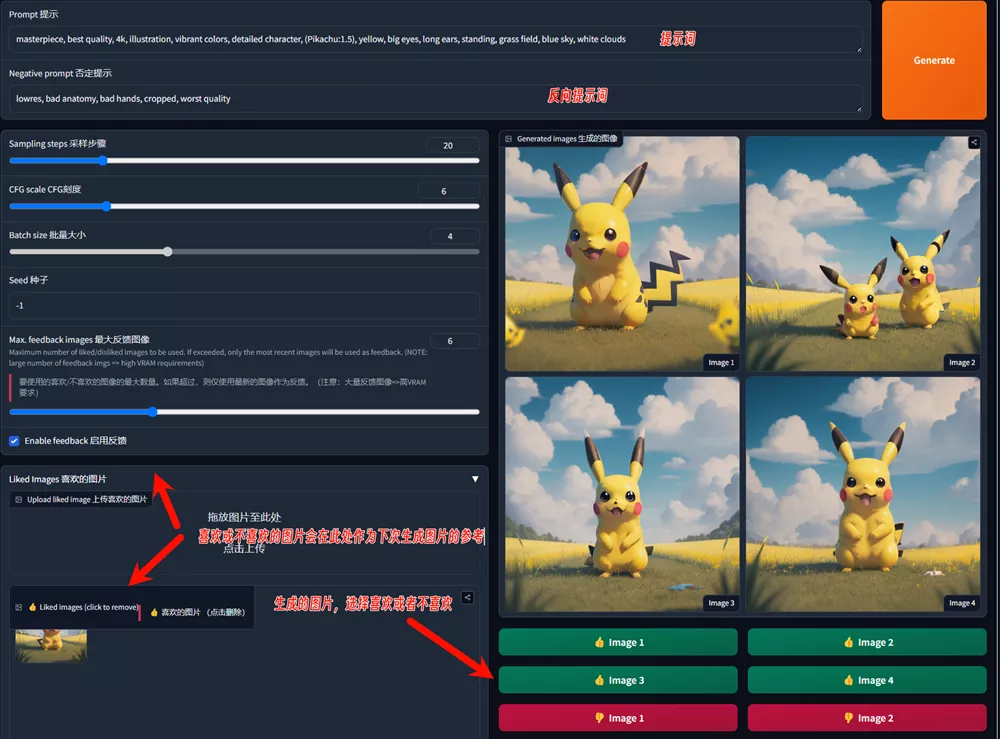
生成图片后,选择自己喜欢或者不喜欢的图片,再次进行图片生成,FABRIC就会根据你之前的喜欢来进行图片生成。你可以不断的添加喜欢与不喜欢的图片,直到生成的你满意的图片。
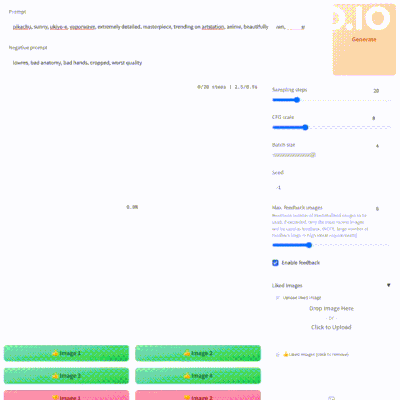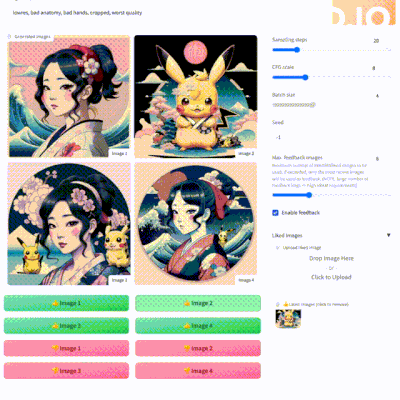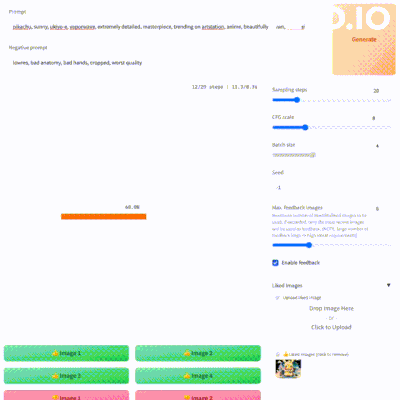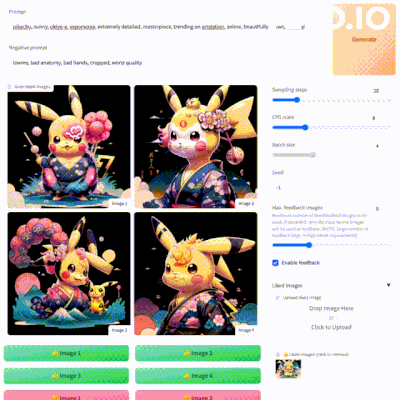
本地安装
官方还提供了SD WebUI和ComfyUI插件,让大家可以在SD WebUI和ComfyUI里运行FABRIC。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...