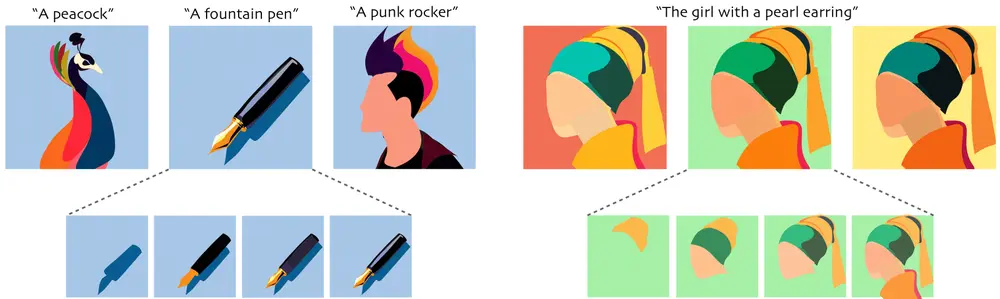
来自美团、浙江大学、Moonshot AI的研究人员推出名为VisionLLaMA的新型视觉变换器(Vision Transformer),它是基于LLaMA(Large Language Model)架构设计的,用于处理图像任务。
想象一下,你有一个能够理解语言的智能助手,现在我们想要创造一个类似的系统,但它不是处理文字,而是处理图像。VisionLLaMA就是这样一个系统,它可以帮助计算机更好地理解和生成图像。

主要功能:
- 图像理解: VisionLLaMA能够理解图像内容,例如识别图像中的对象、场景和活动。
- 图像生成: 它还能够根据给定的文本描述生成高质量的图像。
- 自监督学习: VisionLLaMA可以在没有标签的情况下学习图像的特征,这称为自监督学习。
主要特点:
- 统一架构: VisionLLaMA提供了一个统一的建模框架,可以用于多种视觉任务,如图像分类、分割和目标检测。
- 高效性能: 在许多代表性任务中,VisionLLaMA的性能超过了现有的视觉变换器。
- 快速收敛: VisionLLaMA在训练过程中收敛速度更快,这意味着它可以在更短的时间内达到较好的性能。
工作原理:
- 变换器架构: VisionLLaMA采用了类似于LLaMA的变换器架构,这种架构通过自注意力机制来处理序列数据。在VisionLLaMA中,这种机制被用来处理图像的像素。
- 位置编码: 为了处理图像中的不同位置信息,VisionLLaMA使用了一种称为AS2DRoPE(自适应缩放的2D旋转位置编码)的技术,这允许模型处理任意分辨率的图像。
- 预训练和微调: VisionLLaMA首先在大型数据集上进行预训练,学习图像的通用特征,然后在特定任务上进行微调,以提高任务相关的性能。
具体应用场景:
- 图像分类: VisionLLaMA可以用于识别图像中的物体,例如在ImageNet数据集上进行分类任务。
- 语义分割: 在自动驾驶等领域,VisionLLaMA可以用于理解图像中每个像素属于哪个类别,例如区分道路、车辆和行人。
- 目标检测: VisionLLaMA可以帮助识别图像中的对象并确定它们的位置,这对于视频监控和机器人视觉等应用至关重要。
- 图像生成: 在艺术创作、游戏设计和虚拟现实等领域,VisionLLaMA可以根据文本描述生成逼真的图像。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











