新型视频编辑技术ReVideo:在视频中对特定区域进行精确的内容和运动控制编辑北京大学深圳研究生院 、ARC实验室,腾讯 PCG和东京大学的研究人员推出新型视频编辑技术ReVideo,ReVideo的核心能力是在视频中对特定区域进行精确的内容和运动控制编辑。这意味着用户可以随心...新技术# ReVideo# 视频编辑2年前08520
新型图像生成模型Diffusion Mamba(DiM):通过结合Mamba序列模型的效率和扩散模型的表现力,来高效生成高分辨率的图像来自香港大学、华为诺亚方舟实验室、清华大学和上海交通大学的研究人员推出新型图像生成模型Diffusion Mamba(简称DiM),它融合了基于状态空间模型(SSM)的高效序列模型——Mamba,与扩...新技术# Diffusion Mamba# DiM# 图像生成2年前01,2380
新型自编码器LiteVAE:用于提高图像生成模型中的效率和性能来自苏黎世联邦理工学院和迪士尼研究工作室的研究人员推出新型自编码器LiteVAE,它被设计用于提高图像生成模型中的效率和性能。自编码器是一类神经网络,它们通过学习数据的压缩表示来重构数据。在图像处理中...新技术# LiteVAE# 自编码器2年前07850
索尼推出音频-视觉生成模型Visual Echoes:根据一张图片生成与之相对应的音频,或者反过来,根据一段音频生成匹配的图片索尼推出新型音频-视觉生成模型Visual Echoes,这个模型能够根据一张图片生成与之相对应的音频,或者反过来,根据一段音频生成匹配的图片。这种技术在多模态生成领域具有很大的潜力,因为它能够将视觉...新技术# Visual Echoes# 音频-视觉生成模型2年前09940
无需训练的个性化定制RectifID:根据用户提供的参考图像定制化地生成新图像,同时保留原始图像中的身份特征来自北京大学、快手、电子科技大学和浙江大学的研究人员推出新型图像生成技术RectifID,它能够根据用户提供的参考图像定制化地生成新图像,同时保留原始图像中的身份特征。简单来说,这项技术可以帮助我们在...新技术# RectifID# 个性化定制2年前04750
基于图像条件的扩散模型Semantica:根据给定的条件图像(即输入图像)的语义信息生成新的图像Google Deepmind推出新型图像生成模型Semantica,Semantica的核心特点是它能够在不需要对特定数据集进行微调(finetuning)的情况下,适应不同的图像数据集。这是通过一...新技术# Google DeepMind# Semantica2年前07190
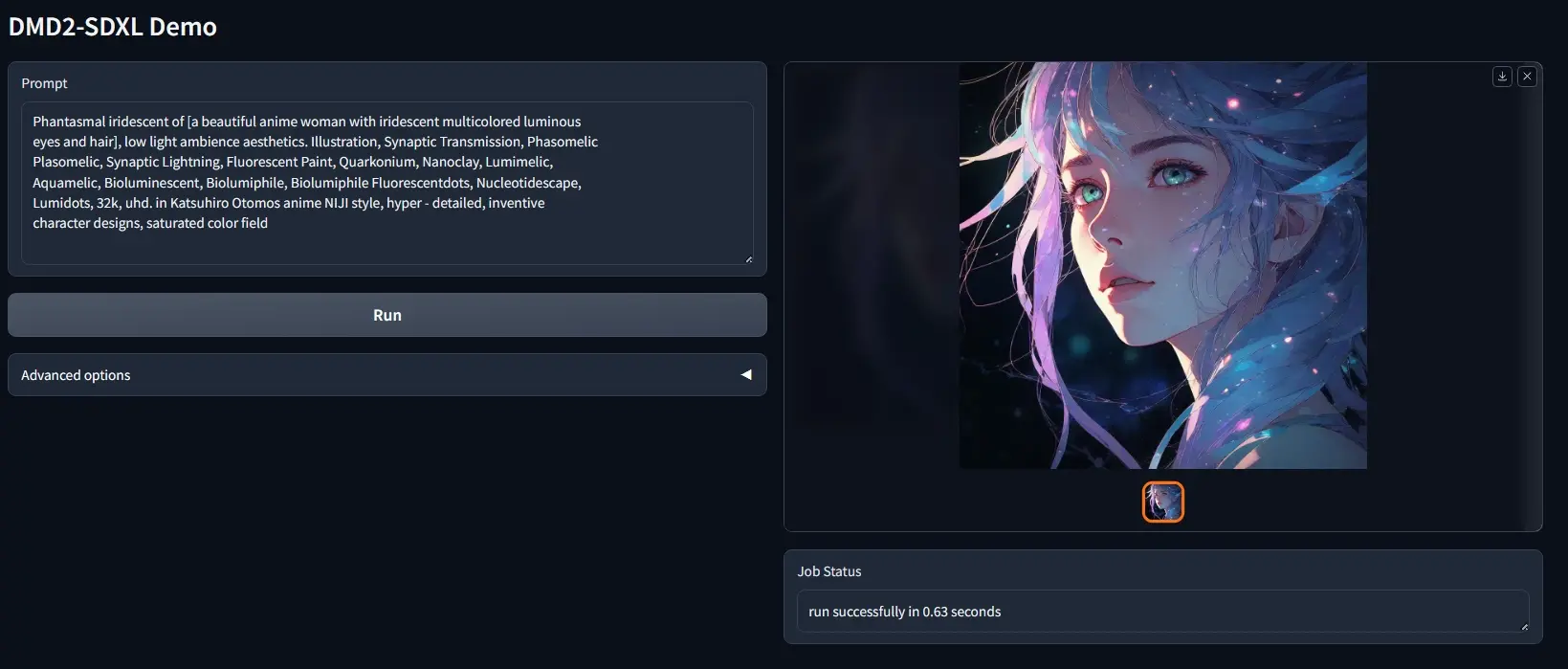
改进图像生成技术DMD2:通过高效的一步生成模型来加速图像生成过程,同时保持或甚至超越原始模型的质量麻省理工学院和 Adobe 研究中心的研究人员推出DMD2(Distribution Matching Distillation的改进版),这是一种改进图像合成技术,特别是针对大语言模型在图像生成...新技术# DMD2# 图像合成2年前09250
文生视频新技术FIFO-Diffusion:无需训练即可从文本生成无限长度的视频首尔国立大学推出文生视频新技术FIFO-Diffusion,它基于预训练的扩散模型,用于文本条件视频生成。简单来说,FIFO-Diffusion能够根据文本描述生成无限长度的视频,而且不需要额外的训练...新技术# FIFO-Diffusion# 文生视频2年前05270
Face-Adapter:专为预训练扩散模型设计的高效且有效的适配器,用于实现高精度和高保真的面部编辑来自浙江大学、腾讯、 VIVO和南洋理工大学的研究人员推出Face-Adapter,这是一个专为预训练扩散模型设计的高效且有效的适配器,用于实现高精度和高保真的面部编辑。经过观察,开发人员发现无论是人...新技术# Face-Adapter# 适配器# 面部编辑2年前05130
新型图像匹配技术OmniGlue:首个以泛化为核心设计原则的可学习图像匹配器德克萨斯大学奥斯汀分校和谷歌的研究人员推出新型图像匹配技术OmniGlue,这是首个以泛化为核心设计原则的可学习图像匹配器。OmniGlue利用来自视觉基础模型的广泛知识来指导特征匹配过程,从而增强了...新技术# OmniGlue# 谷歌2年前06880
商汤研究院推出文本嵌入模型Piccolo2商汤研究院推出文本嵌入模型Piccolo2,它在多个任务上的表现超越了其他模型,并在CMTEB基准测试中创下了新的最高标准。文本嵌入是一种将文本转换成数值向量的技术,这些向量能够捕捉单词、短语或整篇文...新技术# Piccolo2# 商汤研究院# 文本嵌入模型2年前07550
英伟达推出新型文生图模型BlobGEN:基于blob(斑点)的文本到图像扩散模型英伟达推出新型文生图模型BlobGEN,这个模型的核心思想是将场景分解为视觉原语——被称为密集的blob(斑点)表示——这些表示包含了场景的细粒度细节,同时具备模块化、易于理解和构建的特点。例如,一个...新技术# BlobGEN# 文生图模型# 英伟达2年前09730