新型视频超分辨率(VSR)技术EvTexture:通过挖掘事件数据中的高频细节,从而提高视频的分辨率和质量中国科学技术大学和合肥国家科学中心人工智能研究院的研究人员推出新型视频超分辨率(VSR)技术EvTexture,这项技术的核心在于利用事件驱动的信号来增强视频中的纹理细节,从而提高视频的分辨率和质量...新技术# EvTexture# VSR# 视频超分辨率2年前08360
新型蒸馏技术iCD:提升文本引导的图像编辑任务中的图像生成和编辑能力俄罗斯Yandex Research和高等经济大学的研究人员推出新型蒸馏技术Invertible Consistency Distillation(iCD),它用于提升文本引导的图像编辑任务中的图像生...新技术# iCD# 蒸馏技术2年前05890
新型图像编辑工具StyleFeatureEditor:结合了AI的最新进展,使用户能够以前所未有的细节级别和灵活性来编辑图像俄罗斯高等经济大学、AIRI和德国不来梅建筑大学的研究人员推出新型图像编辑工具StyleFeatureEditor,它是基于一种名为StyleGAN的生成对抗网络(GAN)的。StyleGAN是一种特...新技术# StyleFeatureEditor# 图像编辑2年前05110
合成语言-视觉数据集StableSemantics:专注于自然图像中的语义表示卡内基·梅隆大学的研究人员推出合成语言-视觉数据集StableSemantics,它专注于自然图像中的语义表示。简单来说,这个数据集旨在帮助计算机视觉系统更好地理解图像中的场景和对象的语义含义。它涵盖...新技术# StableSemantics# 合成语言-视觉数据集2年前07550
视频合成模型后续调优方法ExVideo:提升模型生成视频的长度和质量华东师范大学和阿里巴巴的研究人员推出新型视频合成模型扩展方法ExVideo,这种方法旨在通过参数高效的方式对现有的视频合成模型(Stable Video Diffusion)进行后期调整(post-t...新技术# ExVideo# SVD模型2年前07730
基于提示、针对文生图模型的新型剪枝方法APTP:减少文生图模型在计算资源受限的环境中部署时的计算负担,同时保持模型性能马里兰大学和佛罗里达州立大学推出一种针对文生图模型的新型剪枝方法APTP(Adaptive Prompt-Tailored Pruning,自适应提示定制剪枝),这是一种专门为文生图模型设计的、基于提...新技术# APTP# 剪枝方法# 文生图模型2年前06200
不可混合扩散Immiscible Diffusion:加速扩散模型的训练过程加州大学伯克利分校和清华大学的研究人员推出新技术“Immiscible Diffusion(不可混合扩散)”,它旨在加速扩散模型的训练过程。扩散模型是一类在图像生成领域取得显著进展的模型,但它们的训练...新技术# Immiscible Diffusion# 扩散模型2年前09170
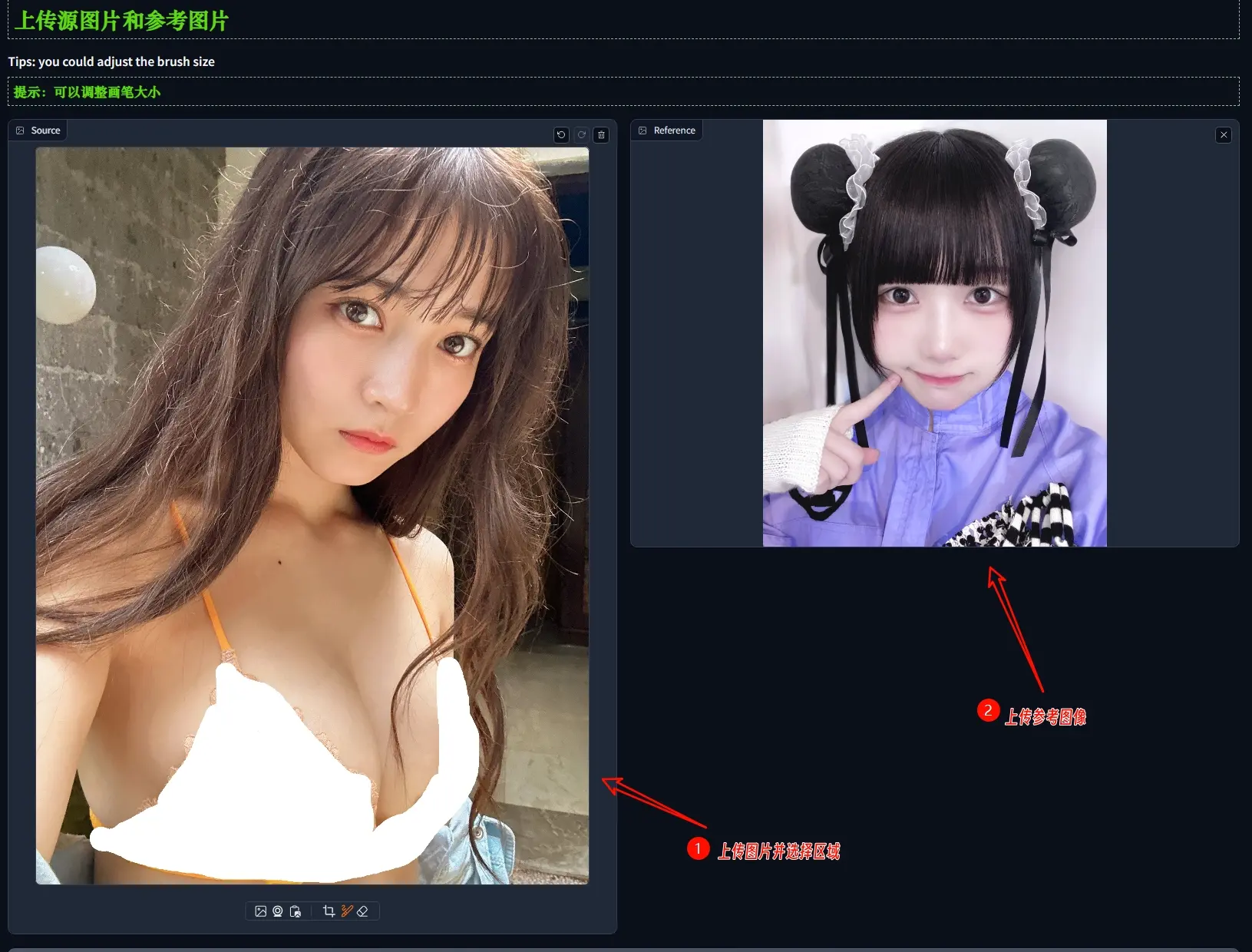
图像编辑技术MimicBrush:允许用户指定源图像中需要编辑的区域,并提供一个参考图像,来展示编辑后期望的效果香港大学、阿里巴巴集团和蚂蚁集团的研究人员推出图像编辑技术MimicBrush,它通过模仿(imitative editing)的方式,让用户能够更加方便地发挥创造力进行图像编辑。简单来说,Mimic...新技术# MimicBrush# 图像编辑2年前06160
通用且即插即用的加速方案AsyncDiff:加速SD模型的运行速度新加坡国立大学推出通用且即插即用的加速方案AsyncDiff,它能够显著加速扩散模型(diffusion models)的运行速度。扩散模型是一种强大的生成模型,能够创造出各种数据,比如图片和视频,但...新技术# AsyncDiff# SD模型2年前07220
一维(1D)标记化技术TiTok:用极少的标记(tokens)来表示和生成高分辨率图像字节跳动和慕尼黑工业大学的研究人员推出新型图像表示方法TiTok,它通过一种新颖的一维(1D)标记化技术,用极少的标记(tokens)来表示和生成高分辨率图像。这种方法与传统的二维(2D)图像标记化方...新技术# TiTok# 一维标记化2年前08370
创新系统SEE-2-SOUND:为静态图片或动态视频生成与之匹配的立体声效果,增强观众的沉浸感和体验多伦多大学、Temerty 人工智能研究与医学教育中心和Sunnybrook 研究所的研究人员推出创新系统SEE-2-SOUND,它能够将视觉内容(如图片或视频)转换成具有空间感的音频输出。简单来说...新技术# SEE-2-SOUND# 立体声2年前05840
新型多模态DiT模型AV-DiT:生成既有视觉画面又有声音的高质量视频来自多伦多大学、德克萨斯大学达拉斯分校和Adobe研究中心的研究人员推出新型多模态扩散变换器AV-DiT(Audio-Visual Diffusion Transformer),它专门设计用于联合生成...新技术# AV-DiT# DiT模型2年前06570