Meta推出创新方案AdaCache(自适应缓存):不进行额外训练的情况下加速视频生成视频生成是AI研究的一个热点领域,特别是在生成时间上一致、高保真的视频方面。这一领域涉及创建在帧之间保持视觉连贯性并在时间上保留细节的视频序列。近年来,机器学习模型,尤其是扩散变换器(DiTs),已成...新技术# AdaCache# Meta AI# 自适应缓存1年前03890
字节跳动推出人像动画技术X-Portrait 2:创建富有表现力和逼真的角色动画和视频素材人像动画技术提供了一种超低成本且高效的方式,用于创建富有表现力和逼真的角色动画和视频素材。用户只需提供一个静态人像图像和一个驱动表演视频,模型就可以使用这些输入生成视频,通过将驱动表情转移到人像中的主...新技术# X-Portrait 2# 人像动画# 字节跳动1年前03790
基于扩散模型的面部匿名化技术:匿名化后的面部与原始照片无缝融合,使其非常适合各种现实世界应用特伦托大学、奥卢大学和新加坡国立大学的研究人员推出一种基于扩散模型的面部匿名化技术,旨在简化面部匿名化流程,同时保留原始图像中的面部表情、头部姿势、眼神方向和背景元素等关键细节。这种方法有效地掩盖了身...新技术# 面部匿名化技术1年前03240
新型视觉生成模型RAR:在通过自回归建模提高图像生成任务的性能,同时保持与语言模型框架的完全兼容性字节跳动推出一种新型视觉生成模型——随机自回归视觉生成(Randomized AutoRegressive Visual Generation,简称RAR)。该模型旨在通过自回归建模提高图像生成任务的...新技术# RAR模型# 随机自回归视觉生成1年前03230
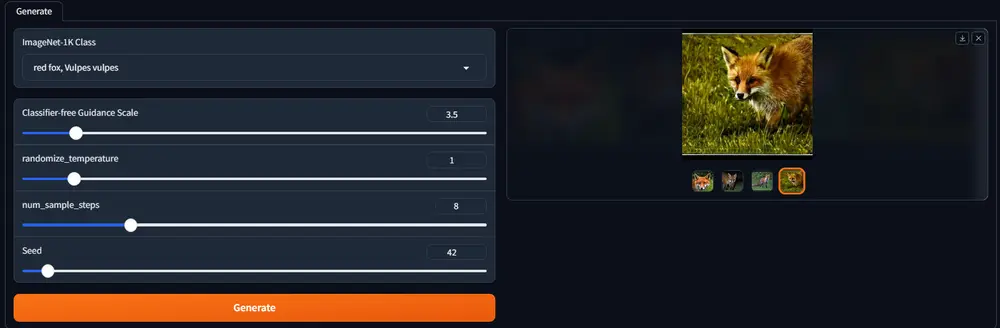
基于常加速度方程的普通微分方程(ODE)框架CAF:用于学习两个分布之间的映射,特别是在图像生成领域高丽大学和韩国科学技术研究院的研究人员推出新型框架Constant Acceleration Flow(CAF),它是一种基于常加速度方程的普通微分方程(ODE)框架,用于学习两个分布之间的映射,特别...新技术# CAF# 图像生成1年前04450
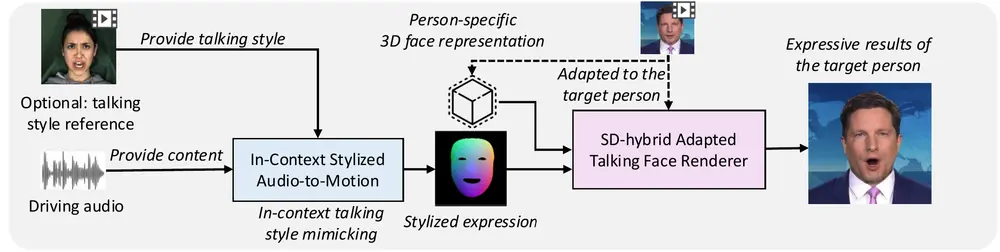
MimicTalk:用于实现特定说话人的高表现力的虚拟人视频合成说话人脸生成(Talking Face Generation, TFG)的目标是将目标身份的脸部动画化,以创建逼真的说话视频。个性化TFG是这一任务的一个重要变体,强调生成的视频在静态外观和动态说话风...新技术# MimicTalk# 虚拟人1年前05000
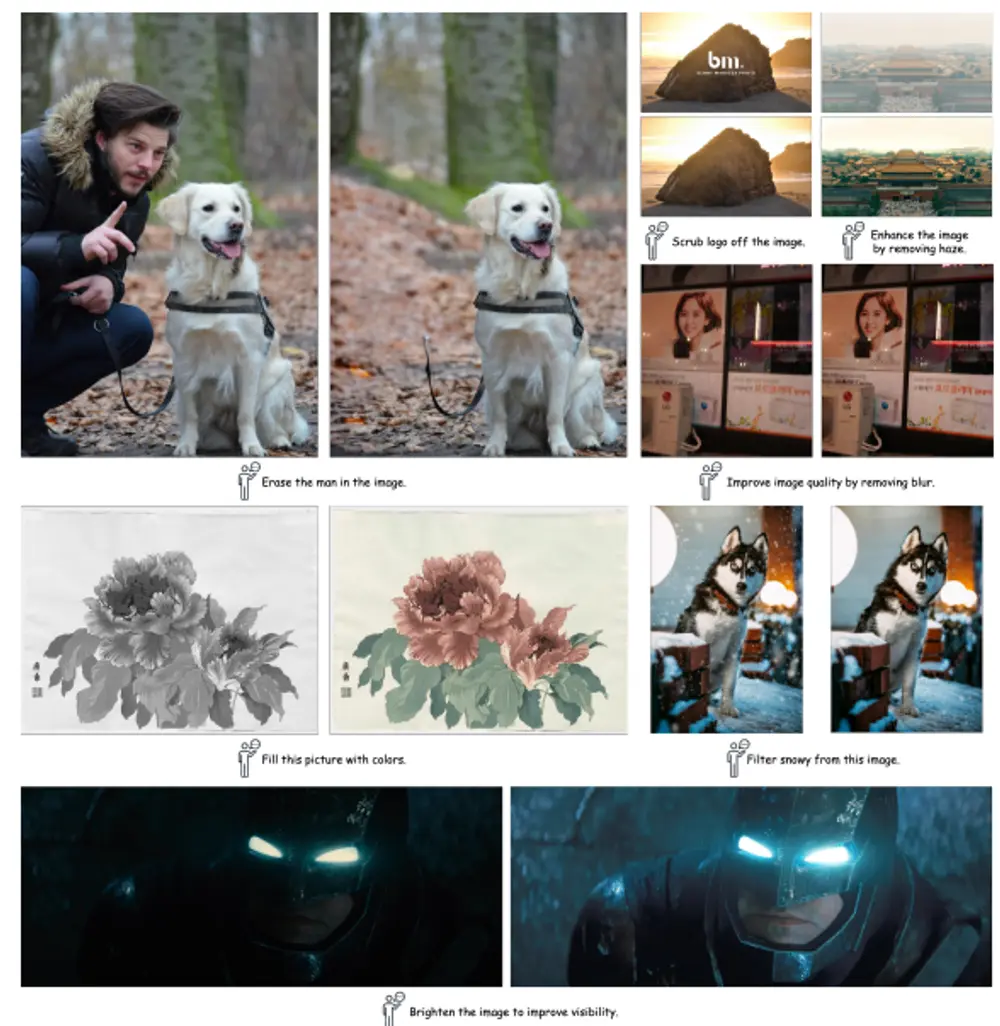
基于扩散模型的图像处理系统PromptFix:能够根据人类的指令执行各种图像处理任务,如上色、提升照片亮度、去除水印、抠图、去雾和去模糊等扩散模型结合语言模型在图像生成任务中展现了卓越的可控性,能够根据人类指令进行图像处理。然而,由于缺乏多样化的指令遵循数据,模型在识别和执行用户定制指令方面仍面临挑战,尤其是在低级任务中。此外,扩散过程...新技术# PromptFix# 图像处理# 扩散模型1年前04050
Decart 和 Etched 联手打造的全球首个实时 AI 世界模型Oasis:完全由AI实时生成游戏场景Oasis 是由 Decart 和 Etched 联手打造的全球首个实时 AI 世界模型。这不仅仅是一个游戏,而是一个完全由 AI 实时生成的互动体验。想象一下,一个无需等待加载、始终以 20fps ...新技术# AI 世界模型# Oasis1年前04320
Unpacking SDXL Turbo: 使用稀疏自编码器来解释和理解文本到图像模型,特别是SDXL Turbo模型的内部工作机制稀疏自编码器(SAEs)已成为逆向工程大语言模型(LLMs)的核心组成部分。SAEs通过将中间表示分解为可解释特征的稀疏和,促进了对模型内部机制的更好理解和控制。然而,类似的分析和方法在文本到图像模型...新技术# SDXL Turbo# 稀疏自编码器1年前03580
新型文本到图像生成技术GrounDiT:利用DiT实现了无需训练的空间定位能力,实现更精细的用户控制韩国科学技术研究院推出新型文本到图像生成技术GrounDiT(GROUNDIT),它通过利用DiT实现了无需训练的空间定位能力,用于在文本到图像生成中实现更精细的用户控制。这项技术特别关注于在图像生成...新技术# GrounDiT# 文生图模型1年前03850
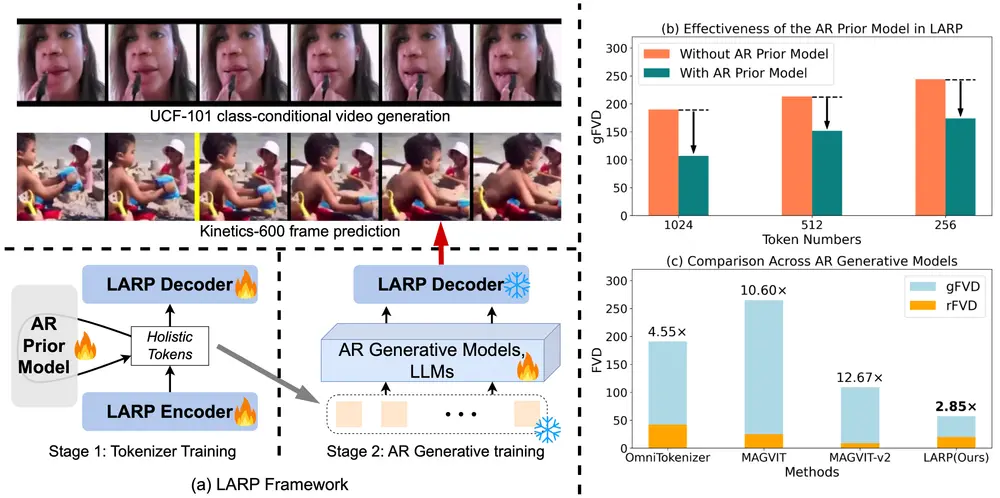
新型视频分词器LARP:专为自回归(AR)生成模型设计,用于提高视频生成任务的性能马里兰大学学院公园分校的研究人员提出了一种名为LARP(Latent Aggregation and Refinement for Perception)的新型视频分词器,它专为自回归(AR)生成模型...新技术# LARP# 视频分词器# 视频生成1年前03980
新型视频生成模型家族MarDini:通过将掩码自回归(MAR)技术与扩散模型(DM)相结合,开创了一种高效的视频生成方法Meta AI与阿卜杜拉国王科技大学的研究人员推出了一种新型视频生成模型家族——MarDini。这一模型家族通过将掩码自回归(MAR)技术与扩散模型(DM)相结合,开创了一种高效的视频生成方法。Mar...新技术# MarDini# 视频生成模型1年前03870