
说话人脸生成(Talking Face Generation, TFG)的目标是将目标身份的脸部动画化,以创建逼真的说话视频。个性化TFG是这一任务的一个重要变体,强调生成的视频在静态外观和动态说话风格上与真实人物的高度相似性。然而,传统的个性化TFG方法通常通过为每个身份学习一个单独的神经辐射场(NeRF)来存储静态和动态信息,这种方法不仅效率低下,而且泛化能力有限。
MimicTalk的提出
为了解决上述问题,浙江大学和字节跳动的研究人员提出了MimicTalk,它是一个用于生成个性化和富有表现力的3D说话面部动画的技术。MimicTalk的目标是在几分钟内模仿目标身份的面部动作和说话风格,以创建逼真的说话视频。例如,我们有一段特定的音频和一个目标人物的参考视频,MimicTalk能够利用这些输入生成一个全新的视频,其中目标人物的面部动作和表情与音频同步,并且模仿参考视频中的说话风格。如果参考视频中的人物在说话时有特定的微笑或挑眉习惯,MimicTalk生成的视频也会展现出这些个性化的特征。
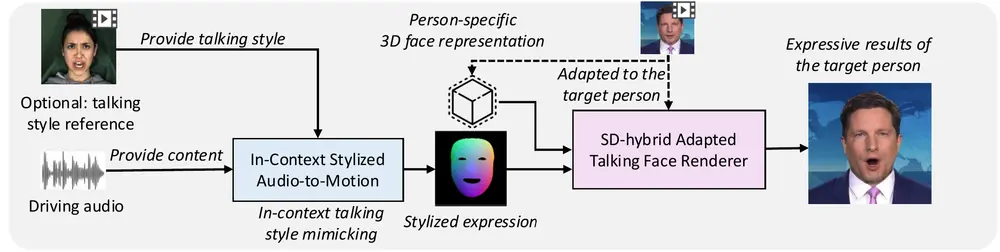
MimicTalk的主要贡献包括:
- 与人物无关的3D TFG模型:我们首先提出一个与人物无关的3D TFG模型作为基础模型。这个基础模型能够捕获通用的面部特征和动态,为后续的个性化适应提供坚实的基础。
- 静态-动态混合适应流水线:为了使基础模型适应特定的身份,我们提出了一种静态-动态混合适应流水线。该流水线帮助模型学习个性化的静态外观和面部动态,从而生成高度逼真的说话视频。
- 上下文风格化的音频到运动模型(ICS-A2M):我们还提出了一种上下文风格化的音频到运动(ICS-A2M)模型。该模型能够在生成说话面部运动的同时,模仿目标人物的说话风格,进一步提高生成视频的表现力和真实性。
主要功能:
- 个性化3D面部动画生成:根据目标人物的静态和动态特征生成逼真的说话视频。
- 说话风格模仿:通过参考视频捕捉并模仿目标人物的说话风格。
- 快速适应新身份:使用预训练的通用模型,通过少量数据快速适应新的目标人物。
主要特点:
- 效率:与以往的人脸特定方法相比,MimicTalk能够更快地适应新身份,只需15分钟即可完成训练。
- 表现力:通过音频驱动的面部动画生成,MimicTalk能够生成具有高度表现力的面部动作。
- 通用性:利用基于NeRF的通用模型,MimicTalk具有良好的泛化能力,能够适应不同的说话条件。
工作原理:
MimicTalk的工作流程包括以下几个步骤:
- 预训练的通用模型:使用一个基于NeRF的预训练通用模型作为基础,该模型能够存储目标人物的静态和动态信息。
- 静态-动态混合适应:通过一个静态-动态混合适应流程,使模型学习目标人物的个性化静态外观和面部动态特征。
- 音频到运动模型:提出一个上下文风格化的音频到运动模型(ICS-A2M),该模型能够在不需要显式风格表示的情况下,模仿参考视频中隐含的说话风格。
实验结果
实验结果表明,MimicTalk在视频质量、效率和表现力方面均超越了先前的基线方法。特别是,对未见身份的适应过程可以在几分钟内快速收敛,显著提高了个性化TFG的实用性和灵活性。
具体应用场景:
MimicTalk可以应用于多种场景,包括:
- 视频会议:生成逼真的虚拟形象,用于远程沟通。
- 虚拟主播:为新闻或娱乐内容创建虚拟主持人。
- 互动式聊天机器人:提供更加自然和逼真的面部表情和动作,提升用户体验。
- 教育和培训:创建虚拟教师或培训角色,用于在线课程和模拟训练。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











