大型重建模型Real3D:利用单视图真实世界图像进行3D重建德克萨斯大学奥斯汀分校的研究人员推出Real3D,它是首个能够使用单视图真实世界图像进行训练的大型重建模型(Large Reconstruction Model,简称LRM)。Real3D通过自训练框...新技术# 3D模型# Real3D2年前05970
新型图像生成模型EMMA:能够接受多模态提示,并生成高质量的图像南洋理工大学和腾讯的研究人员推出新型图像生成模型EMMA,它基于最先进的文本到图像(T2I)扩散模型ELLA,能够接受多模态提示(multi-modal prompts),并生成高质量的图像。简单来说...新技术# ELLA# EMMA# 图像生成2年前08840
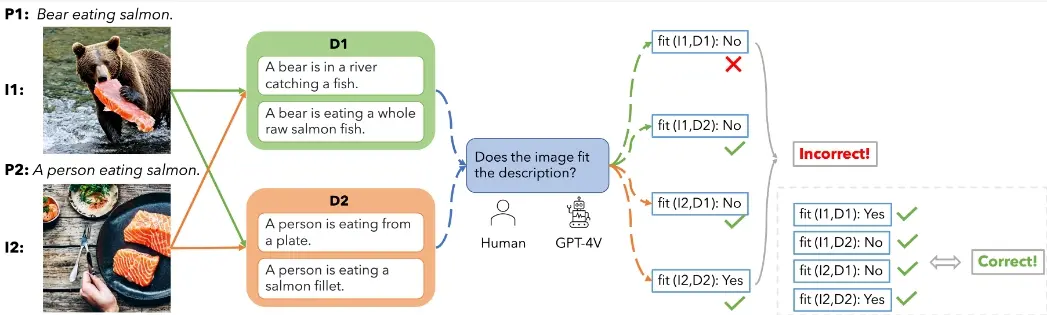
基准测试CommonsensenT2I:用于评估文生图模型(T2I)生成符合现实生活常识的图像的能力宾夕法尼亚大学和加州大学圣塔芭芭拉分校的研究人员推出基准测试CommonsensenT2I,用于评估文生图模型(T2I)生成符合现实生活常识的图像的能力。简单来说,就是研究这些模型是否能够根据文字描述...新技术# CommonsensenT2I# 基准测试# 文生图模型2年前05710
Adobe推出Toffee:用于主题驱动的文本到图像生成的高效数据集构建方法Adobe Research和加州大学圣克鲁斯分校的研究人员推出Toffee系统,它是一个用于主题驱动的文本到图像生成的高效数据集构建方法。简单来说,Toffee能够创建大量的图像和文本对,这些图像能...新技术# Adobe Research# Toffee# 数据集2年前06680
新型图像压缩技术CMC(模态压缩):利用大型多模态模型来实现图像到文本再到图像的转换,从而在保持图像质量的同时,大幅度减小图像的大小上海交通大学和南洋理工大学的研究人员推出一种新型的图像压缩技术“跨模态压缩”(Cross Modality Compression,简称CMC)。这项技术的核心思想是利用大型多模态模型(Large M...新技术# CMC# CMC-Bench# 图像压缩2年前08770
扩散模型中“幻觉”(hallucinations)现象:生成了一些在训练数据中从未出现过的样本卡内基梅隆大学和DatalogyAI的研究人员发布论文探讨扩散模型(diffusion models)中“幻觉”(hallucinations)现象,即模型生成了一些在训练数据中从未出现过的样本。这种...新技术# 幻觉# 扩散模型2年前06300
文生图模型偏好优化方法MaPO(边界感知偏好优化):让计算机在学习生成图像时,能够更好地符合人类的偏好韩国科学技术研究院、Huggingface和高丽大学的研究人员推出一种新的文本到图像扩散模型的偏好优化方法,这种方法被称为“边界感知偏好优化”(Margin-aware Preference Opti...新技术# MaPO# 文生图模型# 边界感知偏好优化2年前08590
OPPO推出多步潜在一致性模型MLCM:用于加速生成图像OPPO推出多步潜在一致性模型MLCM,它用于加速生成图像的潜在扩散模型(LDMs)。简而言之,MLCM能够快速生成高质量的图像,同时保持较低的计算成本。MLCM仅需2-8步采样即可生成高质量、令人愉...新技术# MLCM# OPPO# 多步潜在一致性模型2年前05840
建立在多模态大语言模型基础上的统一文本到图像生成和检索框架TIGeR来自新加坡国立大学 NExT++ 实验室、南洋理工大学、香港理工大学和哈尔滨工业大学(深圳)的研究人员推出一个统一的文本到图像生成和检索框架TIGeR,这个框架建立在多模态大语言模型(MLLMs)的基...新技术# TIGeR# 文生图2年前07470
新型图像生成模型家族LlamaGen:将大语言模型(Llama)应用到视觉图像生成领域香港大学及字节跳动的研究人员推出新型图像生成模型家族LlamaGen,将大语言模型(Llama)中原用于文本生成的“下一个令牌预测”范式应用到了视觉图像生成领域。LlamaGen是对传统自回归模型在图...新技术# LlamaGen# 图像生成# 大语言模型2年前06760
图生图新技术pOps:将图像和文本转换为可以相互理解的格式,更好的生成图像特拉维夫大学和西蒙菲莎大学的研究人员推出图生图新技术pOps(Photo-Inspired Diffusion Operators),它是一种用于生成视觉内容的先进方法。例如,你想要生成一张“在海滩上...新技术# pOps# 图生图2年前06680
新型文本到视频生成框架VideoTetris:专门设计来解决现有方法在处理复杂场景(如多对象或对象数量动态变化的长视频)生成时面临的挑战来自北京大学和快手科技的研究人员推出新型文本到视频生成框架VideoTetris,此框架专门设计来解决现有方法在处理复杂场景(如多对象或对象数量动态变化的长视频)生成时面临的挑战。VideoTetri...新技术# VideoTetris# 北京大学# 快手2年前09840