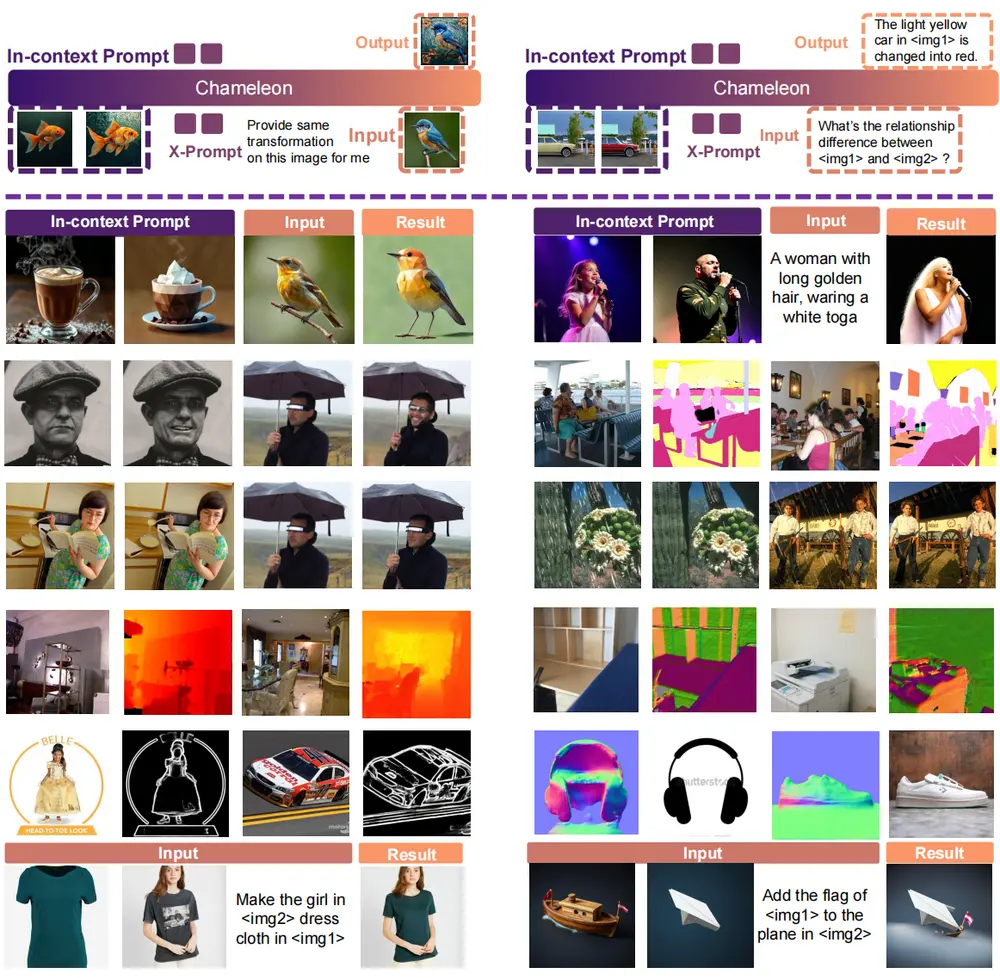
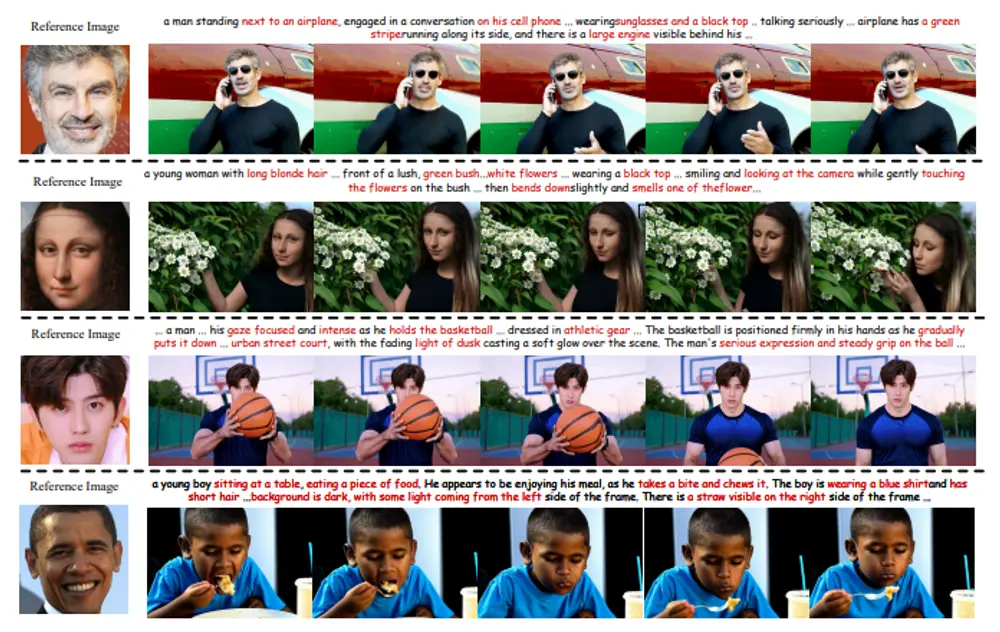
新型自回归视觉语言基础模型X-Prompt:实现通用的上下文内图像生成随着大语言模型(LLMs)在自然语言处理领域的广泛应用,基于LLMs的自动回归视觉语言模型(VLMs)在文本到图像生成方面也取得了显著进展。然而,上下文学习——即通过少量示例来指导模型执行特定任务的能...新技术# X-Prompt1年前02440
轻量级的新型视频对象分割和跟踪模型EfficientTAM随着视频对象分割(VOS)和跟踪任务的日益复杂,现有的强大工具如SAM 2虽然在准确性和功能上表现出色,但其高计算复杂性限制了其在移动设备等资源受限环境中的应用。为了解决这一问题,Meta和南洋理工大...新技术# EfficientTAM# 视频对象分割# 跟踪模型1年前02480
零一万物推出Presto:专为生成长达15秒的高质量视频而设计的新型扩散模型零一万物团队隆重推出Presto——一款专为生成长达15秒的高质量视频而设计的新型扩散模型。Presto旨在克服长时间视频生成中保持场景多样性和一致性的挑战,通过引入分段交叉注意力(Segmented...新技术# Presto# 零一万物1年前02710
新型自编码器WF-VAE:为提高潜在视频扩散模型中视频变分自编码器的性能而设计北大-兔展AIGC联合实验室推出新型自编码器WF-VAE,此编码器与开源视频生成项目Open-Sora Plan相关,它是为了提高潜在视频扩散模型(Latent Video Diffusion Mod...新技术# WF-VAE# 自编码器1年前02840
针对DiT模型的深度修剪方法TinyFusion:通过端到端学习去除冗余层,以减少模型的参数量和提高推理效率新加坡国立大学的研究人员推出一个针对DiT模型的深度修剪方法TinyFusion,旨在通过端到端学习去除冗余层,以减少模型的参数量和提高推理效率。DiT架构在图像生成领域展现出了卓越的能力,但通常伴随...新技术# DiT模型# TinyFusion1年前02780
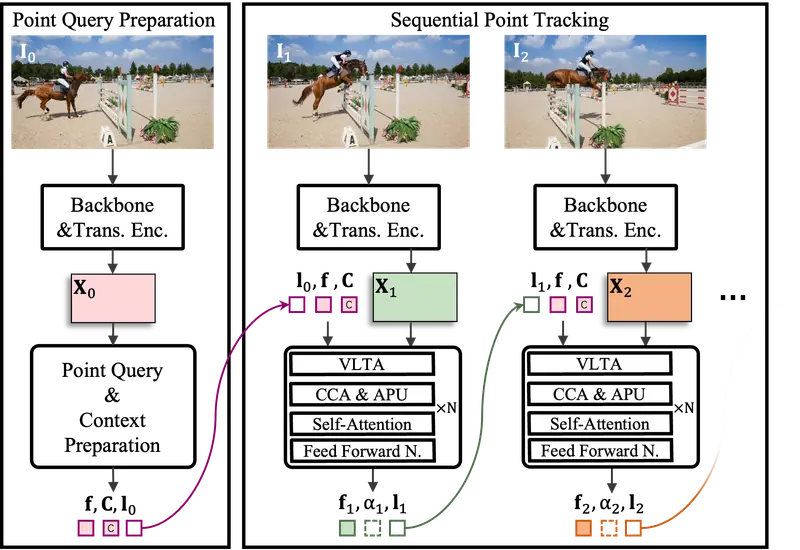
先进跟踪系统TAPTRv3:用于在长视频中跟踪任意点IDEA Research、华南理工大学、清华大学和香港科技大学的研究人员推出先进跟踪系统TAPTRv3,它专门设计用于在长视频中跟踪任意点。TAPTRv3是建立在TAPTRv2基础上的,主要目标是提...新技术# TAPTRv31年前02960
PSHuman:利用多视角扩散模型先验的3D人体建模新框架真实感3D人体建模在虚拟现实、增强现实、电影制作、游戏开发和医疗等领域具有广泛的应用。尽管单目全身重建方法取得了显著进展,但它们通常依赖于前视图和/或预测的后视图,这导致了由于问题的病态性质和复杂的自...新技术# 3D人体建模# PSHuman1年前03140
可控人类图像生成的新框架BootComp:特别适用于包含多个参考服装的情况韩国科学技术研究院和OMNIOUS.AI的研究人员提出了BootComp——一种用于可控人类图像生成的新框架,特别适用于包含多个参考服装的情况。这一创新解决了训练数据获取的主要瓶颈,即为每个人类主体收...新技术# BootComp1年前02970
基于扩散模型的人类视频生成框架AnchorCrafter:用于创建高保真度的主播风格产品推广视频。自动生成锚点风格的产品推广视频在在线商务、广告和消费者互动中展现出巨大的潜力。然而,尽管姿态引导的人类视频生成技术取得了显著进展,这一任务仍然充满挑战。特别是将人-物交互(Human-Object I...新技术# AnchorCrafter# 视频生成1年前03030
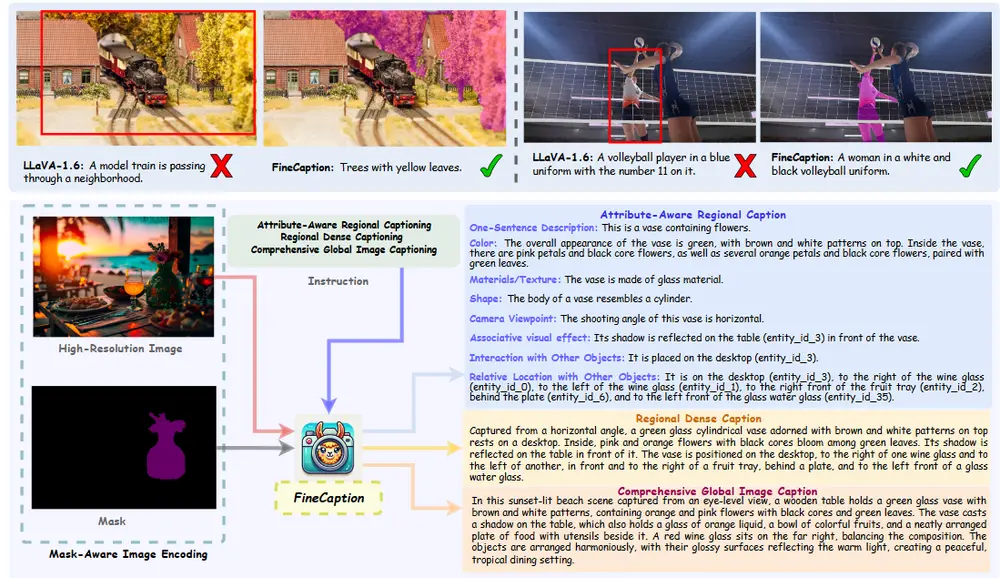
视觉-语言模型FINECAPTION:专注于在任意位置和任意粒度级别上进行组合式图像描述随着大型视觉语言模型(VLMs)的出现,多模态任务的发展取得了显著进展。这些模型在图像和视频字幕、视觉问答以及跨模态检索等应用中展现了强大的推理能力。然而,尽管VLMs具有卓越的表现,它们在细粒度图像...新技术# FINECAPTION# 视觉-语言模型1年前03130
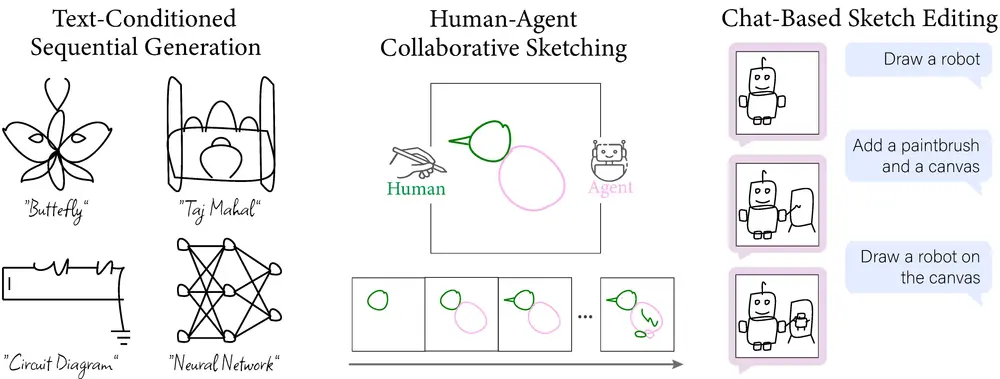
语言驱动的顺序草图生成方法SketchAgent:让用户通过动态、对话式的交互来创建、修改和细化草图MIT和斯坦福大学的研究人员推出一种语言驱动的顺序草图生成方法SketchAgent,能够让用户通过动态、对话式的交互来创建、修改和细化草图。例如,你想要生成一个关于“蝴蝶”的草图。你可以给Sketc...新技术# SketchAgent# 草图1年前03360
ConsisID:无调优可控的身份保持文本到视频生成身份保持的文本到视频(IPT2V)生成旨在创建具有一致人类身份的高保真视频,这是视频生成领域的重要任务之一。然而,生成模型在这一方面仍然面临诸多挑战。北京大学、鹏城实验室、罗切斯特大学和新加坡国立大学...新技术# ConsisID1年前02810