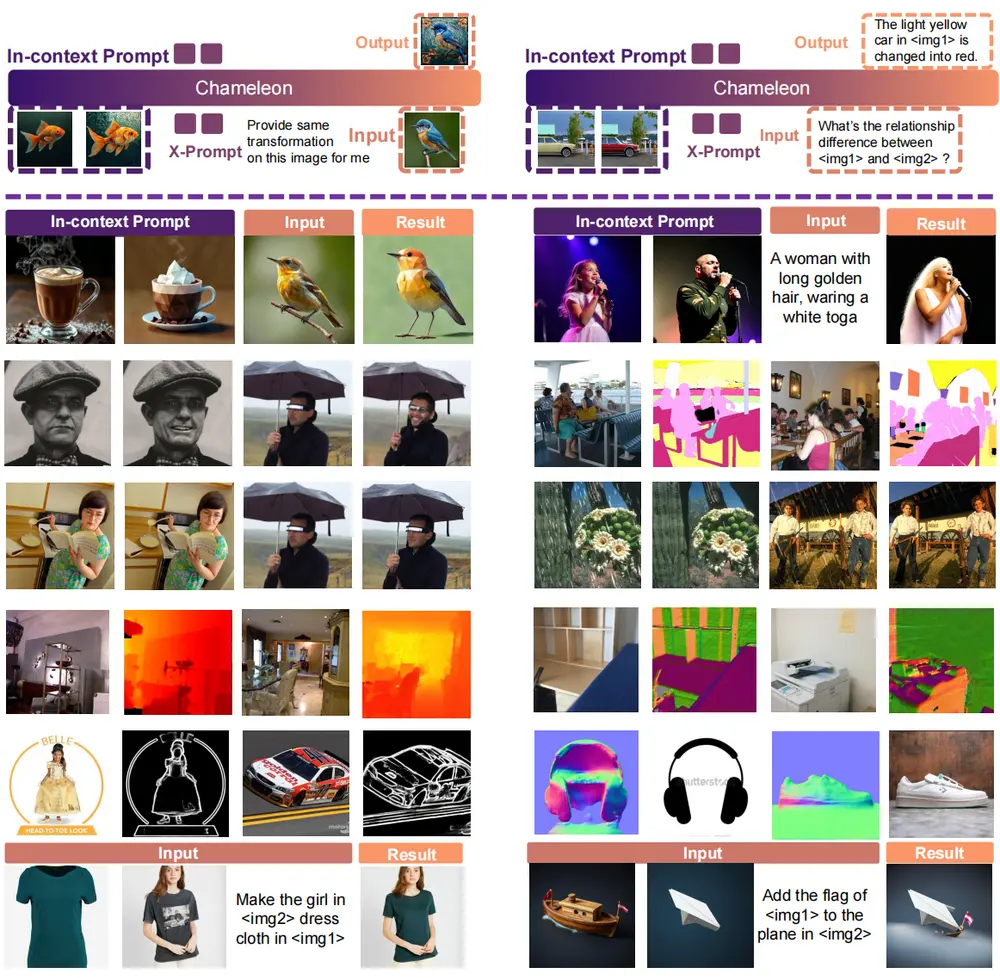
随着大语言模型(LLMs)在自然语言处理领域的广泛应用,基于LLMs的自动回归视觉语言模型(VLMs)在文本到图像生成方面也取得了显著进展。然而,上下文学习——即通过少量示例来指导模型执行特定任务的能力——在一般图像生成任务中的潜力尚未得到充分挖掘。为了解决这一问题,上海交通大学、上海人工智能实验室、清华大学、香港中文大学、InnoHK和摩尔线程的研究团队共同开发了X-Prompt,这是一个专门设计用于上下文学习的自动回归大型视觉语言模型,旨在广泛的任务中提供强大的图像生成能力,实现通用的上下文内图像生成。X-Prompt通过利用少量示例作为上下文,能够在统一的上下文学习框架内,对多种见过和未见过的图像生成任务展现出竞争力的性能。
例如,一个设计师想要将一张图片中的旧式电话转变为现代智能手机。他可以提供一张旧电话的图片和一个文本提示:“将图片中的旧式电话变成最新款的iPhone”。X-Prompt模型将理解这个指令,并生成一张新的图片,其中旧电话被替换为现代智能手机,同时保持背景和其他元素不变。这样的应用展示了X-Prompt在图像编辑任务中的潜力,能够根据文本提示进行精确的图像内容修改。
核心技术创新
1. 统一的上下文学习框架
X-Prompt的核心在于其统一的上下文学习框架,该框架允许模型在一个一致的环境中处理已见和未见的图像生成任务。通过这种方式,X-Prompt不仅能够有效地执行域内任务,还能灵活应对新出现的任务,展现出强大的泛化能力。
2. 高效的上下文特征压缩
为了支持更长的上下文令牌序列并提高对未见任务的泛化能力,X-Prompt引入了一种高效的上下文特征压缩机制。这种机制能够在不损失信息的情况下,将上下文示例中的关键特征提取出来,从而增强模型的理解和预测能力。这使得X-Prompt能够在有限的计算资源下处理复杂的图像生成任务。
3. 统一的文本和图像预测训练任务
X-Prompt采用了统一的文本和图像预测训练任务,使模型能够通过上下文示例增强任务意识。具体来说,模型在同一框架内同时进行文本和图像的预测,这有助于它更好地理解任务要求,并根据给定的上下文生成更加准确和相关的图像。这种训练方式不仅提高了模型的性能,还增强了其对不同任务的适应性。
主要功能
X-Prompt的主要功能包括:
- 文本到图像的生成:根据文本提示生成相应的图像。
- 图像编辑:对现有图像进行编辑,如改变风格、添加或移除对象。
- 密集预测:进行语义分割、深度估计等视觉任务。
- 低级视觉任务:包括图像去雨、去模糊、风格转换等。
主要特点
- 上下文学习:通过几个示例即可学习新任务。
- 多模态处理:同时处理图像和文本,实现更丰富的交互。
- 自回归模型:采用自回归方式,逐步生成图像或文本。
- 通用性:能够在多种不同的图像生成任务中使用。
工作原理
X-Prompt的工作原理基于以下几个关键组件:
- 上下文示例压缩:将上下文示例的信息压缩成固定长度的压缩标记序列,以减少训练时所需的上下文长度。
- 任务增强管道:通过生成描述输入和输出图像之间关系的文本标记来增强训练数据,使模型能够更深入地理解图像之间的关系。
- 检索增强图像编辑(RAIE):通过检索数据库中相关的例子来增强图像编辑任务,提供上下文指导。
实验验证与性能表现
研究人员对X-Prompt进行了广泛的实验评估,涵盖了多种已见和未见的图像生成任务。实验结果表明,X-Prompt在已见任务上表现出色,能够生成高质量的图像,同时在未见任务中也展示了强大的泛化能力。特别是在一些复杂和多样化的任务中,X-Prompt的表现尤为突出,证明了其在上下文学习方面的优势。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











