字节跳动推出新型单目深度估计方法Video Depth Anything:专门用于超长视频(数分钟)的高质量、一致的深度估计字节跳动推出新型单目深度估计方法Video Depth Anything,专门用于超长视频(数分钟)的高质量、一致的深度估计。该方法基于 Depth Anything V2,通过引入高效的空间-时间头...新技术# Video Depth Anything# 字节跳动1年前02640
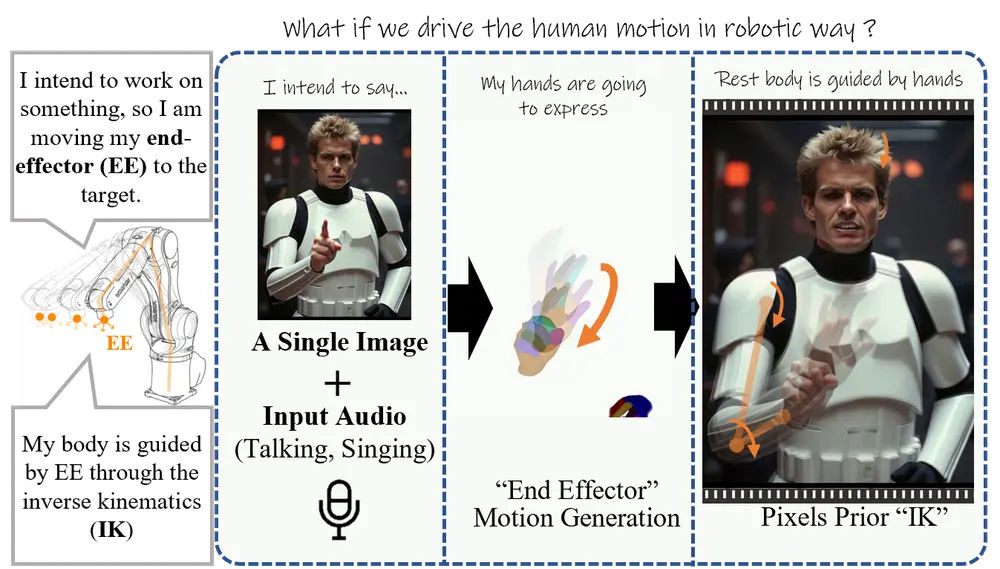
阿里推出新型音频驱动的虚拟角色视频生成方法EMO2:同时生成富有表现力的面部表情和手势动作阿里在去年2月推出新型音频驱动的虚拟角色视频生成方法EMO,近期又发布了 EMO2,它能够同时生成富有表现力的面部表情和手势动作。该方法特别关注于语音伴随手势(co-speech gestures)的...新技术# EMO21年前06150
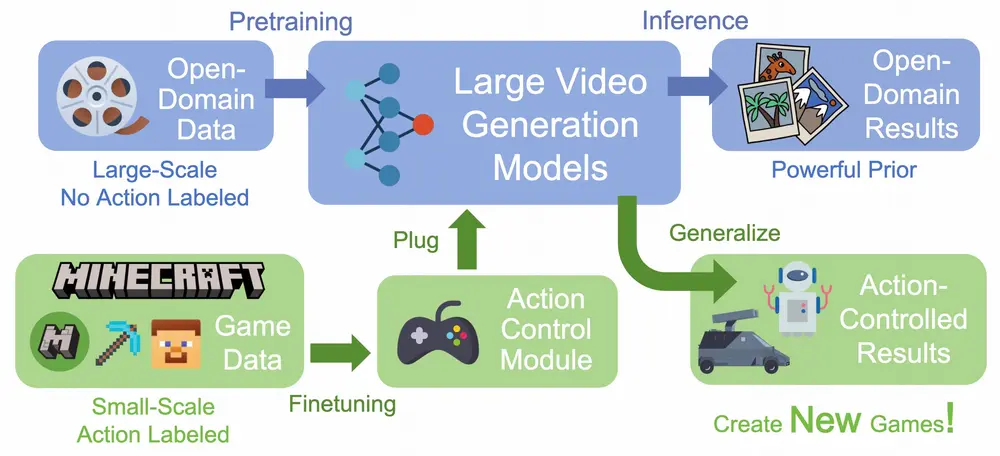
GameFactory框架:通过生成式交互视频来创建全新的游戏香港大学和快手科技的研究人员推出GameFactory框架,旨在通过生成式交互视频来创建全新的游戏。该框架利用预训练的视频扩散模型(video diffusion models),结合少量的第一人称游...新技术# GameFactory# 快手1年前03120
新型多概念个性化方法TokenVerse:通过预训练的DiT架构文生图模型实现从单张或多张图像中提取复杂视觉概念,并支持无缝组合这些概念以生成新的图像谷歌 DeepMind、特拉维夫大学、以色列理工学院和魏茨曼研究所的研究人员推出新型多概念个性化方法TokenVerse,旨在通过预训练的DiT架构文生图模型实现从单张或多张图像中提取复杂视觉概念,并...新技术# TokenVerse1年前02540
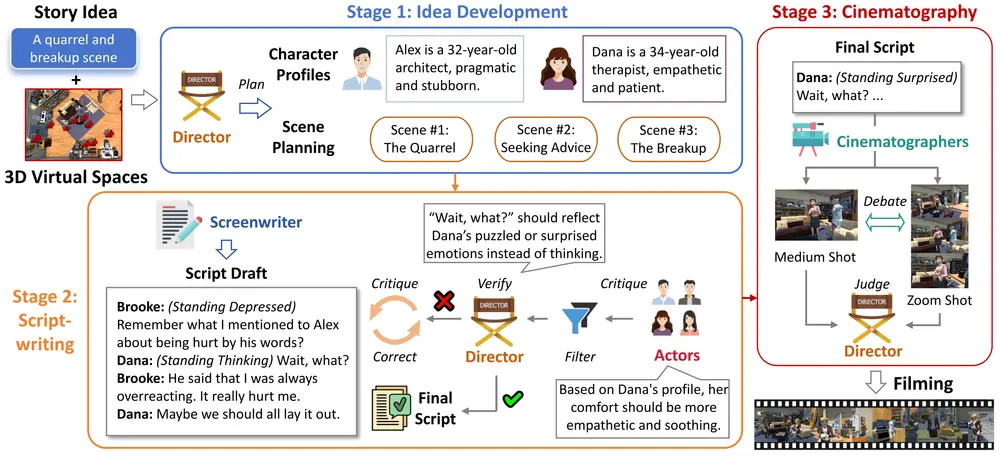
多智能体协作框架 FILMAGENT:通过大语言模型实现虚拟 3D 空间中的端到端电影自动化制作哈尔滨工业大学(深圳)和清华大学的研究人员推出多智能体协作框架 FILMAGENT,旨在通过大语言模型(LLMs)实现虚拟 3D 空间中的端到端电影自动化制作。该框架模拟了电影制作中的各种角色(如导演...新技术# FILMAGENT# 电影1年前02570
字节跳动推出新型身份保持视频生成方法EchoVideo字节跳动推出新型身份保持视频生成方法EchoVideo ,旨在通过多模态特征融合解决传统方法中存在的“复制粘贴”现象和身份相似度低的问题。该方法能够生成高质量、连贯且一致的视频内容,同时保持人物的身份...新技术# EchoVideo# 视频生成1年前02570
1Prompt1Story:解决文生图模型生成中的一致性问题南开大学、巴塞罗那自治大学计算机视觉中心、穆罕默德·本·扎耶德人工智能大学,林雪平大学和软银的研究人员推出1Prompt1Story,旨在解决文本到图像(Text-to-Image,T2I)生成中的一...新技术# 1Prompt1Story1年前02390
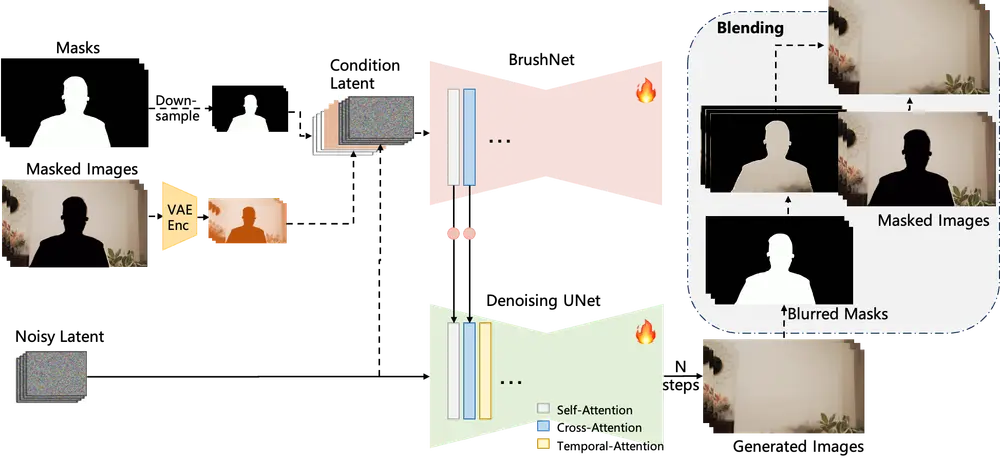
基于扩散模型的视频修复方法DiffuEraser:分解视频修复任务为子问题并给出解决方案阿里巴巴通义实验室的研究人员推出一种基于扩散模型的视频修复方法DiffuEraser,能够生成更详细、更连贯的结构,并通过引入先验信息和优化时间一致性来提升性能。比如,在一段视频中,如果某个物体被意外...新技术# DiffuEraser# 视频修复1年前03060
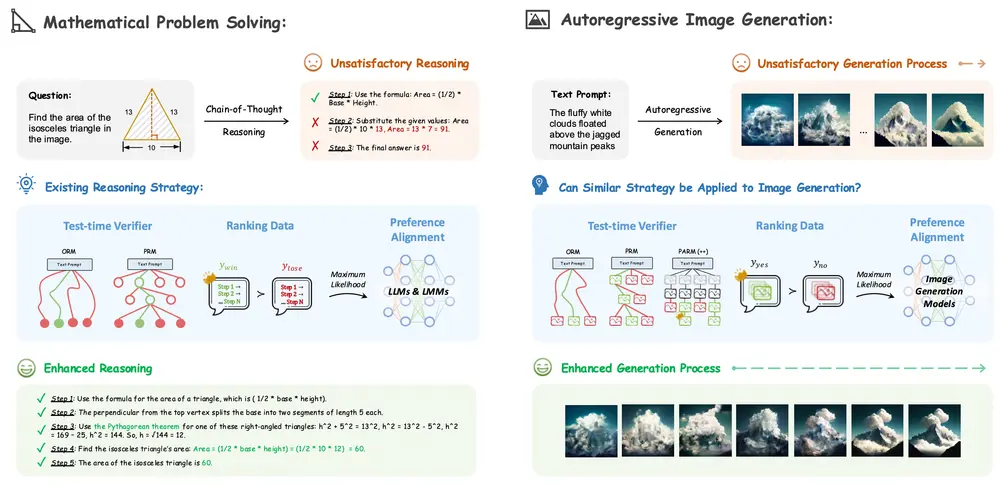
思维链推理策略在自回归图像生成中的应用潜力香港中文大学、北京大学和上海人工智能实验室的研究人员探索思维链(Chain-of-Thought, CoT)推理策略在自回归图像生成中的应用潜力。思维链是一种通过逐步分解复杂问题来解决问题的策略,在语...新技术# 思维链1年前02500
基于扩散模型的新型零样本人像视频动画生成技术X-Dyna南加州大学、字节跳动公司、斯坦福大学、加州大学洛杉矶分校和加州大学圣地亚哥分校的研究团队推出一种新型的零样本(zero-shot)人像视频动画生成技术X-Dyna,基于扩散模型(diffusion-b...新技术# X-Dyna# 人像视频动画1年前02700
Textoon:基于文本描述生成Live2D格式2D卡通角色的创新方法在数字角色创作领域,2D卡通风格因其独特的魅力而深受年轻观众的喜爱。尽管3D角色研究取得了显著进展,但交互式2D卡通角色的发展却显得相对滞后。为了解决这一问题,阿里巴巴通义实验室推出了Textoon...新技术# Live2D# Textoon1年前03680
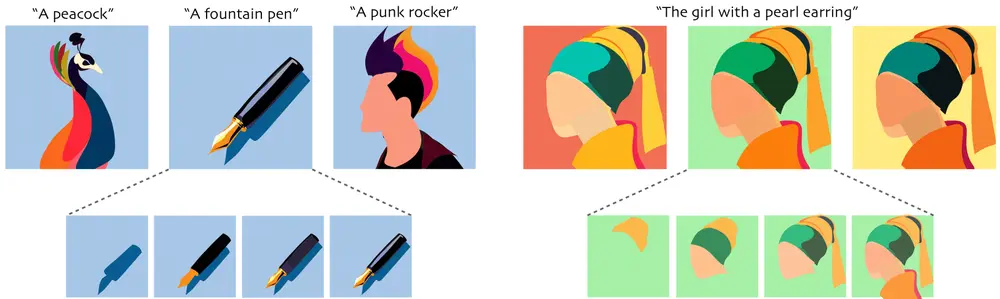
NeuralSVG:用于从文本提示生成矢量图形特拉维夫大学和麻省理工学院的研究人员推出了一种名为 NeuralSVG 的新方法,用于从文本提示生成矢量图形(SVG)。该方法通过隐式神经表示(NeRFs)和分数蒸馏采样(SDS)技术,生成具有层次结...新技术# NeuralSVG1年前02880