micro_diffusion :一种低成本训练文生图模型的方法索尼 AI和加州大学河滨分校的研究人员推出了一种低成本训练大规模文本到图像(Text-to-Image, T2I)扩散模型的方法micro_diffusion 。该方法通过创新的“延迟掩码”(defe...新技术# micro_diffusion# 文生图模型1年前04320
实时动画生成系统RAIN:能够使用单个 RTX 4090实时生成无限长的视频流中国科技大学的研究人员推出实时动画生成系统RAIN,能够使用单个 RTX 4090实时生成无限长的视频流。该系统的核心目标是解决现有扩散模型在实时动画生成中的局限性,例如延迟高、视觉质量下降以及无法长...新技术# RAIN# 动画生成1年前02580
新型虚拟试穿方法MN-VTON:通过单个生成网络实现高质量的虚拟试穿效果,挑战了当前依赖双网络范式的主流方法虚拟试穿(VTON)作为电子商务领域的一项关键技术,能够帮助消费者真实地预览服装在自己身上的效果。然而,早期的VTON技术受限于单一生成网络,在保留细粒度的服装细节方面存在不足。为了解决这个问题,研究...新技术# MN-VTON# 虚拟试衣1年前03400
多实例生成方法3DIS-FLUX:利用最新的FLUX模型进行渲染,以实现更高质量的图像生成和更强的控制能力浙江大学和哈佛大学的研究人员推出多实例生成(Multi-Instance Generation)方法3DIS-FLUX,用于文本到图像生成。3DIS-FLUX是3DIS框架的扩展,利用最新的FLUX模...新技术# 3DIS-FLUX# 多实例生成1年前02660
多模态大语言模型Omni-RGPT:在统一图像和视频的区域级理解英伟达和延世大学的研究人员推出多模态大语言模型Omni-RGPT,旨在统一图像和视频的区域级理解。Omni-RGPT通过一种新颖的区域表示方法——Token Mark,实现了对图像和视频中特定区域的深...新技术# Omni-RGPT# 多模态大语言模型1年前02590
字节跳动推出视频生成模型训练新方法APT:通过在扩散预训练的基础上对真实数据进行对抗训练,以实现一步视频生成扩散模型在图像和视频生成领域展示了卓越的能力,但其迭代性质导致了生成过程缓慢且计算成本高昂。尽管现有的蒸馏方法尝试通过一步生成来解决这一问题,但往往伴随着显著的生成质量下降。为了解决这些挑战,字节跳动...新技术# APT# Seaweed-APT模型# 字节跳动1年前02680
字节跳动推出新型图像分词器TA-TiTok及掩码生成模型MaskGen字节跳动和浦项科技大学的研究人员提出了一种名为TA-TiTok的新型图像分词器。这是一种基于Transformer架构的文本感知一维分词器,能够高效处理离散或连续的一维标记。基于TA-TiTok的成功...新技术# MaskGen# TA-TiTok# 字节跳动1年前02700
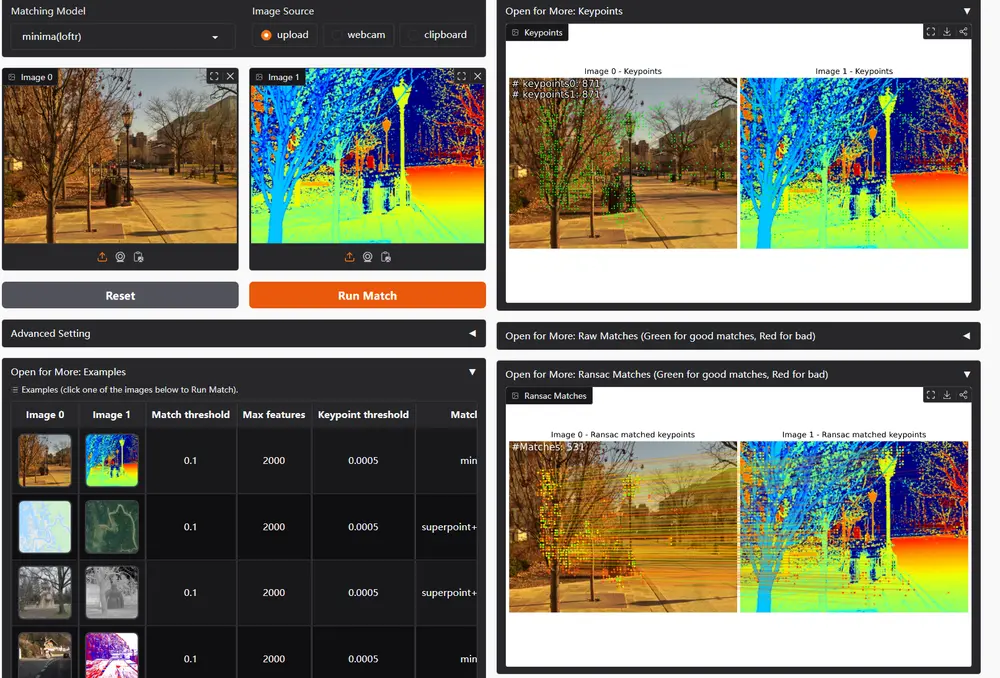
图像匹配框架MINIMA:解决跨视图和跨模态的情况下,多模态感知中的图像匹配问题华中科技大学和武汉大学的研究人员推出一个统一的图像匹配框架MINIMA,即模态不变图像匹配。这项研究旨在解决多模态感知中的图像匹配问题,特别是在跨视图和跨模态的情况下。例如,在自动驾驶中,需要将可见光...新技术# MINIMA# 图像匹配框架1年前05060
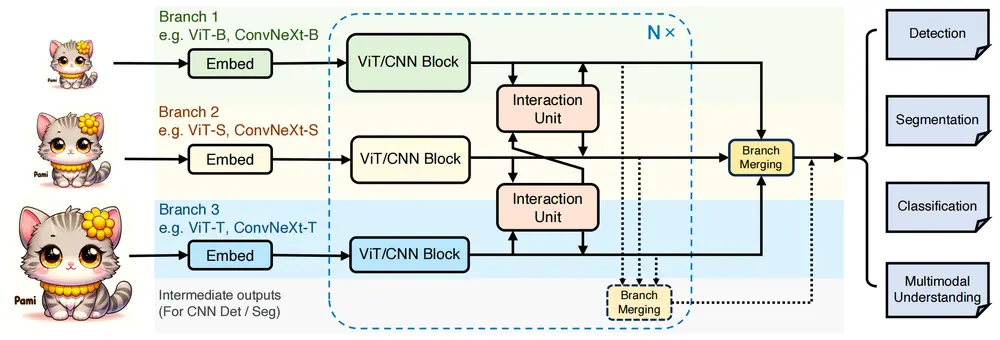
新型网络架构PIIP:提高视觉感知和多模态理解任务中的计算效率和性能上海交通大学、清华大学、上海人工智能实验室、香港中文大学和商汤科技的研究人员推出新型网络架构PIIP,旨在提高视觉感知和多模态理解任务中的计算效率和性能。PIIP通过将不同分辨率的图像与不同参数规模的...新技术# PIIP1年前02250
视频生成框架RepVideo:通过重新思考跨层表示来提高文生视频模型的性能南洋理工大学和上海人工智能实验室的研究人员推出视频生成框架RepVideo,旨在通过重新思考跨层表示来提高文本到视频(Text-to-Video, T2V)扩散模型的性能。该框架通过积累邻近层的特征来...新技术# RepVideo# 视频生成框架1年前02420
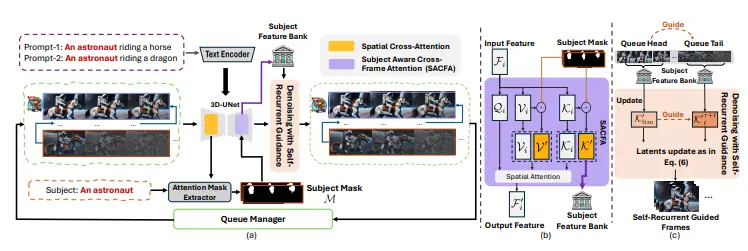
新型视频去噪框架Ouroboros-Diffusion:提高无调优(tuning-free)长视频生成中的结构和内容(主体)一致性罗切斯特大学和智象未来的研究人员推出新型视频去噪框架Ouroboros-Diffusion,旨在提高无调优(tuning-free)长视频生成中的结构和内容(主体)一致性。该框架通过引入新的潜在采样技...新技术# Ouroboros-Diffusion# 视频去噪1年前02350
SynthLight:基于扩散模型,通过模拟环境光照条件对真实人像照片进行重新照明在数字影像处理领域,耶鲁大学和Adobe研究中心联合推出了一项创新技术——SynthLight。这项技术基于扩散模型,通过模拟环境光照条件对真实人像照片进行重新照明,从而达到令人惊叹的视觉效果。该方法...新技术# SynthLight1年前02290