AnyStory:用于文本到图像生成的统一单主体和多主体个性化框架,生成具有特定主体的高保真个性化图像阿里巴巴通义实验室推出一个用于文本到图像生成的统一单主体和多主体个性化框架AnyStory,旨在生成具有特定主体的高保真个性化图像,无论是单个主体还是多个主体,都能在不牺牲主体保真度的情况下实现个性化...新技术# AnyStory1年前02190
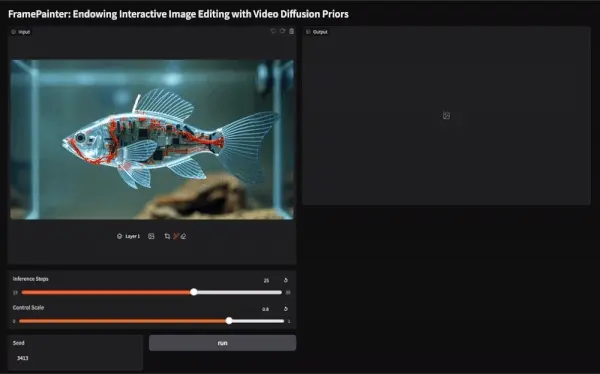
交互式图像编辑工具FramePainter:利用视频扩散先验来增强图像编辑的能力哈尔滨工业大学和华为诺亚方舟实验室的研究人员推出交互式图像编辑工具FramePainter,它利用视频扩散先验(video diffusion priors)来增强图像编辑的能力。FramePaint...新技术# FramePainter# 交互式图像编辑1年前02520
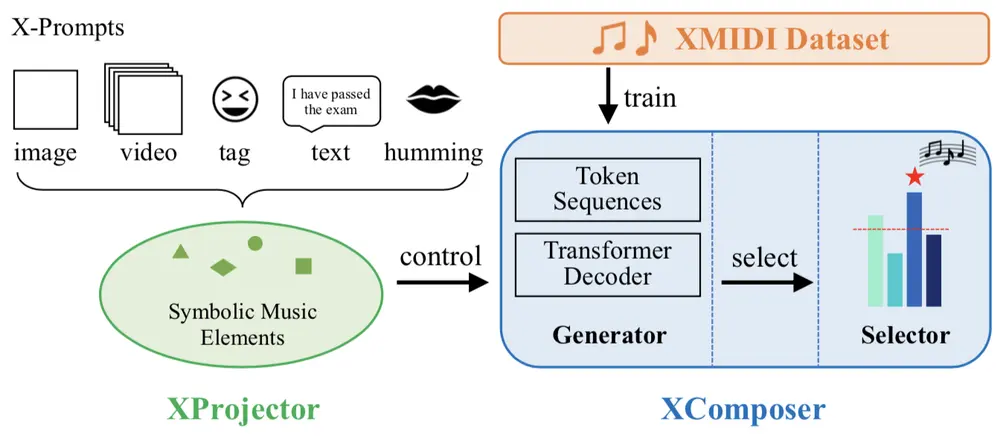
腾讯推出音乐生成框架XMusic:支持多种输入形式(图像、视频、文本、标签和哼唱)生成音乐在 AI 生成内容的领域中,音乐创作一直未能跟上视觉和文本内容的步伐。如今,腾讯推出的 XMusic 框架有望改变这一现状,通过情感可控、高质量的音乐创作,为创意应用带来新的可能性。 项目主页:htt...新技术# XMusic1年前02150
通用视频人脸恢复的统一框架SVFR:用于解决视频中的人脸恢复问题厦门大学多媒体可信感知与高效计算教育部重点实验室和腾讯优图实验室的研究人员推出人脸恢复统一框架SVFR,用于解决视频中的人脸恢复问题。人脸恢复(Face Restoration, FR)是图像和视频处...新技术# SVFR# 人脸恢复1年前02450
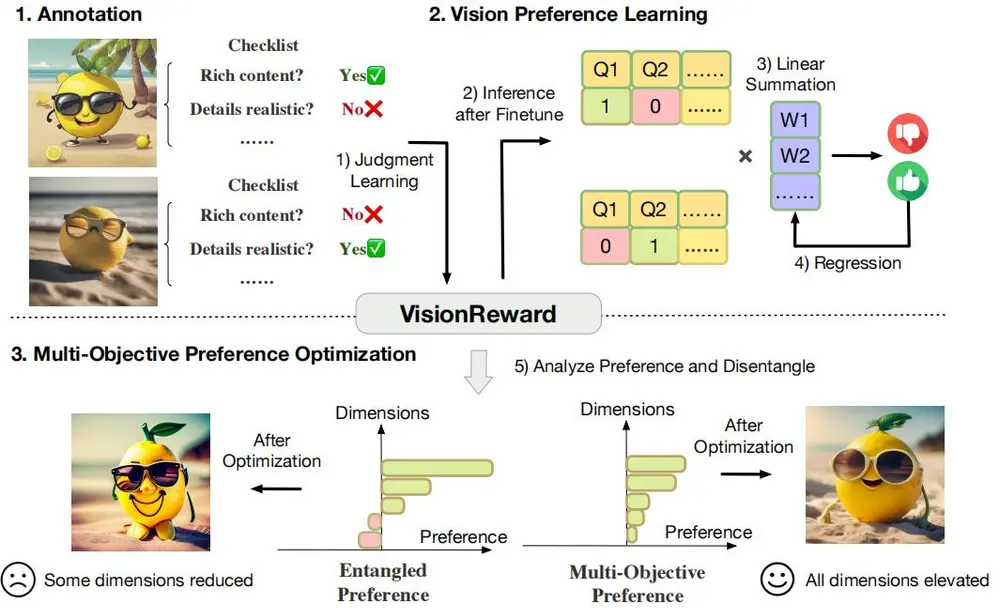
VisionReward:用于图像和视频生成的细粒度多维度人类偏好学习框架清华大学和智谱AI的研究人员推出VisionReward,这是一个用于图像和视频生成的细粒度多维度人类偏好学习框架。VisionReward通过构建一个细粒度且多维度的奖励模型,将人类对图像和视频的偏...新技术# VisionReward1年前03550
Ingredients:将多个特定身份(ID)的照片与视频生成模型结合,实现定制化的视频创作昆仑万维的研究人员推出一个强大的框架 Ingredients,通过将多个特定身份(ID)的照片与视频扩散变换器(Video Diffusion Transformers)结合,实现定制化的视频创作。该...新技术# Ingredients1年前02580
单步扩散模型 DepthMaster:将扩散模型应用于单目深度估计中国科学技术大学和vivo移动通信有限公司的研究人员推出一种单步扩散模型 DepthMaster,,旨在将扩散模型应用于单目深度估计(Monocular Depth Estimation, MDE...新技术# DepthMaster# 单目深度1年前02580
图生视频框架Through-The-Mask:将静态图像转换为基于文本描述的真实视频序列Meta和耶路撒冷希伯来大学的研究人员推出图生视频框架Through-The-Mask,旨在将静态图像转换为基于文本描述的真实视频序列。该框架通过引入基于掩码的运动轨迹作为中间表示,能够准确地动画化多...新技术# Through-The-Mask# 图生视频1年前03010
新型视频生成框架GS-DiT:通过伪4D高斯场实现对视频内容的精确4D控制香港中文大学多媒体实验室、博智感知交互研究中心和Avolution AI的研究人员推出新型视频生成框架GS-DiT,旨在通过伪4D高斯场实现对视频内容的精确4D控制。GS-DiT通过构建伪4D高斯场并...新技术# GS-DiT# 视频生成1年前03650
高保真面部表情编辑框架MagicFace:通过控制面部动作单元的变化来实现对特定人物面部表情的精细编辑芬兰奥卢大学信息技术与电气工程学院机器视觉与信号分析中心和东南大学生物科学与医学工程学院儿童发展与学习科学教育部重点实验室的研究人员推出高保真面部表情编辑框架MagicFace,它通过控制面部动作单元...新技术# MagicFace# 面部表情编辑1年前02350
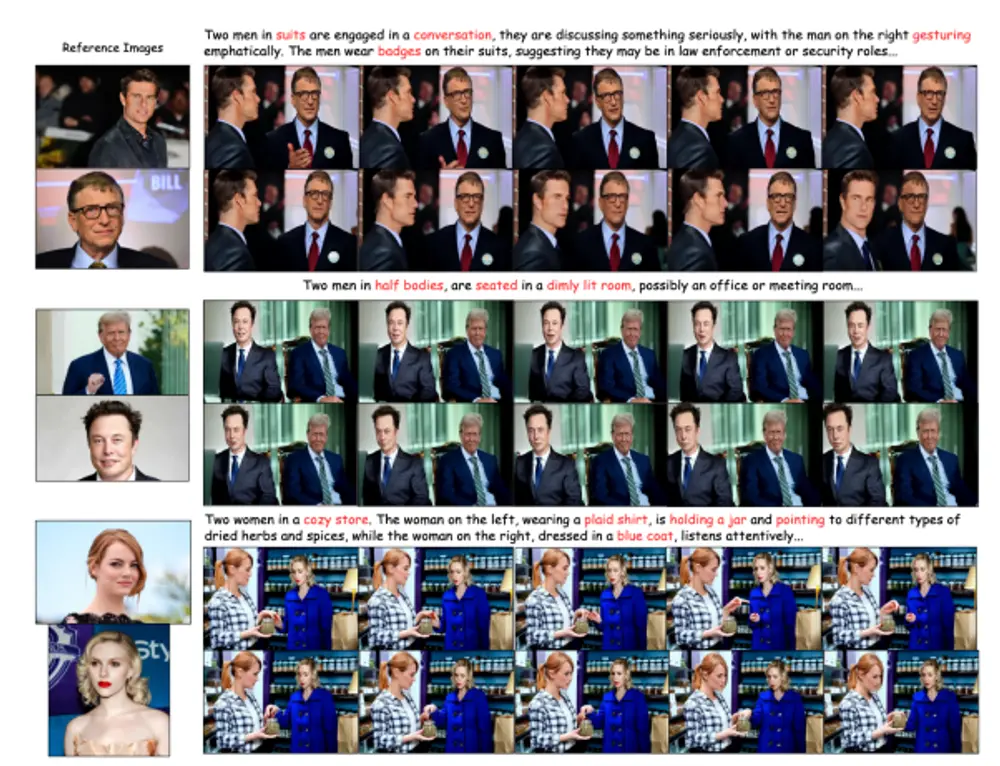
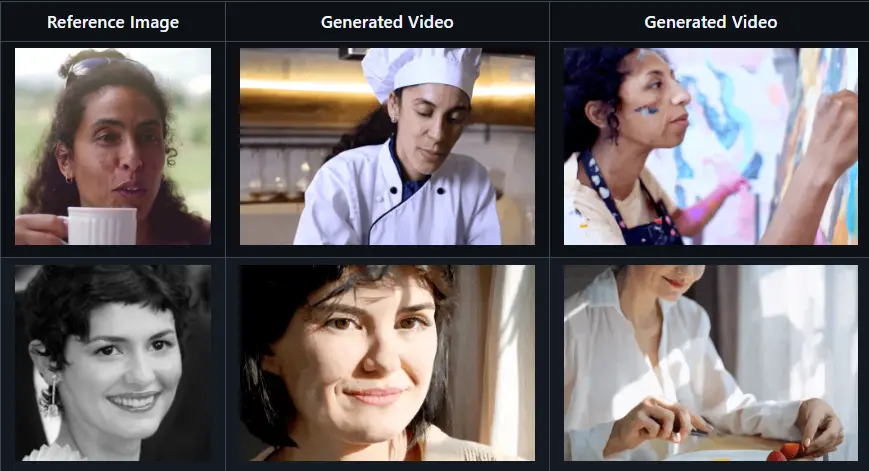
Magic Mirror框架:生成具有身份保持(ID-Preserved)和动态运动的高质量视频香港中文大学、香港科技大学、思谋科技和卡内基梅隆大学的研究人员推出Magic Mirror框架,旨在生成具有身份保持(ID-Preserved)和动态运动的高质量视频。尽管视频扩散模型在文本到视频生成...新技术# Magic Mirror1年前02650
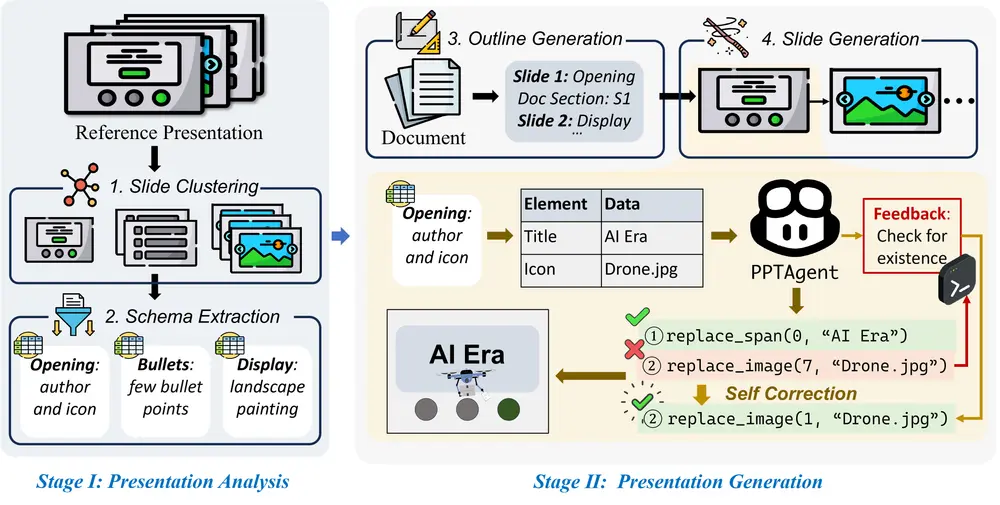
PPTAgent:根据文档自动化地生成高质量的演示文稿中国科学院软件研究所中文信息处理实验室、中国科学院大学和上海捷信科技有限公司的研究人员推出新型框架PPTAgent,旨在自动化地生成高质量的演示文稿。与传统的文本到幻灯片的转换方法不同,PPTAgen...新技术# PPTAgent4个月前02330