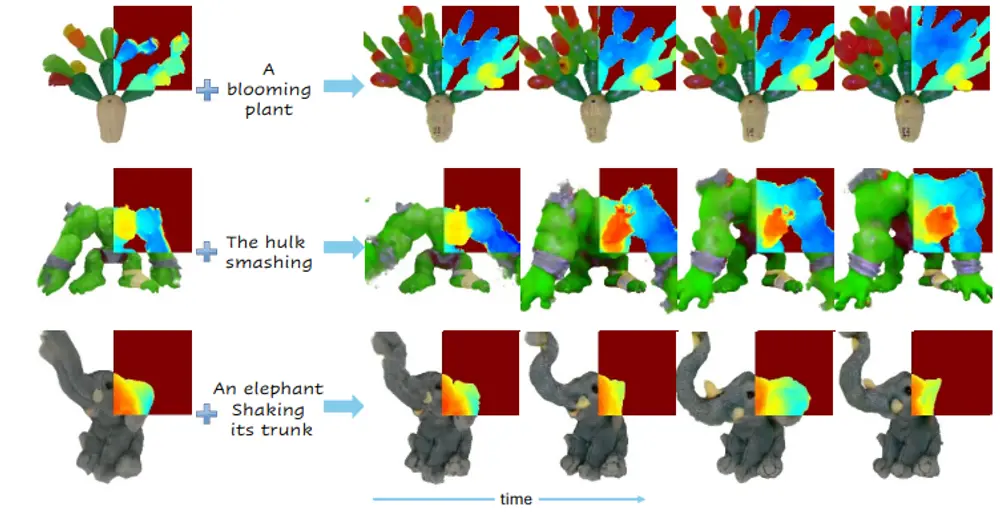
Bringing Objects to Life:将静态的3D对象转换成4D动画(即动态的3D对象),这个过程是通过文本提示来控制的巴伊兰大学和英伟达的研究人员推出一种名为3to4D的方法,它能够将静态的3D对象转换成4D动画(即动态的3D对象),这个过程是通过文本提示来控制的。这种方法允许用户为提供的3D模型添加动态行为,模拟对...新技术# 3to4D1年前02970
图像编辑框架Edicho:能够在野外环境(即非受控环境)中实现一致性的图像编辑在处理真实场景图像时,实现一致的编辑效果是一个长期存在的技术挑战。这主要由于物体姿态、光照条件和摄影环境等不可控因素的影响。为了应对这些挑战,香港科技大学、蚂蚁集团、斯坦福大学和香港中文大学的研究人员...新技术# Edicho# 图像编辑框架1年前02800
新型框架VideoMaker:实现高质量的零样本(zero-shot)定制化视频生成浙江大学计算机科学与技术学院、腾讯PCG ARC实验室、腾讯AI实验室和华为诺亚方舟实验室的研究人员推出新型框架VideoMaker,它能够实现高质量的零样本(zero-shot)定制化视频生成。这个...新技术# VideoMaker1年前03440
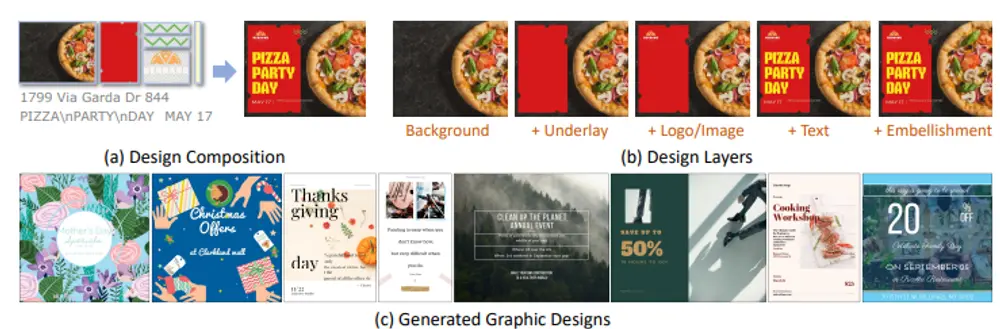
自动图形设计构图方法LaDeCo:从多模态图形元素自动组成一个协调、平衡且视觉上令人愉悦的图形设计随着技术的进步,自动化的图形设计工具正在逐渐改变我们创造视觉内容的方式。然而,现有的生成模型往往局限于特定的子任务,并未能全面地处理设计组合这一复杂过程。为了克服这些限制,西安交通大学与微软研究院联手...新技术# LaDeCo# 自动图形设计1年前02560
Orient Anything:用于从单张图片中估计物体的方向浙江大学、Sea AI实验室和香港大学的研究人员推出一个名为“Orient Anything”的方法,它用于从单张图片中估计物体的方向。这种方法特别关注于理解物体在图像中的空间姿态和排列,这对于计算机...新技术# Orient Anything1年前03460
任务偏好优化TPO:通过视觉任务对齐来提升多模态大语言模型的性能上海人工智能实验室、浙江大学、中国科学技术大学、上海交通大学、中国科学院深圳先进技术研究院和南京大学的研究人员推出一种名为任务偏好优化(Task Preference Optimization, TP...新技术# TPO# 任务偏好优化# 多模态大语言模型1年前03400
1.58-bit FLUX:将FLUX.1-dev量化到1.58位权重的方法字节跳动和浦项科技大学的研究人员推出1.58-bit FLUX,这是第一个成功将最先进的文本到图像生成模型FLUX.1-dev量化到1.58位权重的方法。通过这种方法,我们能够在不损失生成质量的情况下...新技术# 1.58-bit FLUX1年前02900
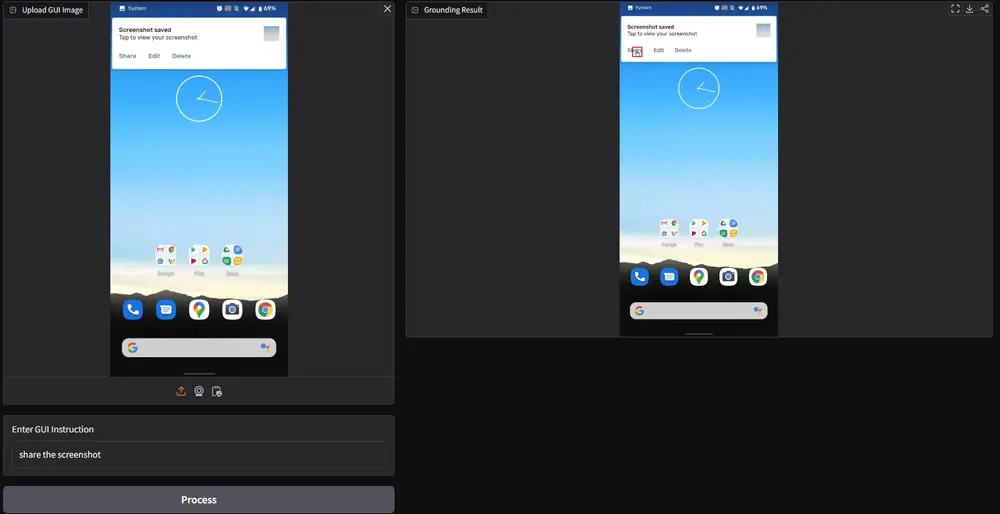
采用纯视觉方法!专注于GUI映射的大型多模态模型Aria-UI在当今数字化快速发展的时代,跨平台的自动化任务变得越来越普遍。对于这些任务而言,数字代理通过直接操作图形用户界面(GUI)来完成工作的重要性日益凸显。然而,将自然语言指令准确映射到具体的GUI元素上一...新技术# Aria-UI1年前02560
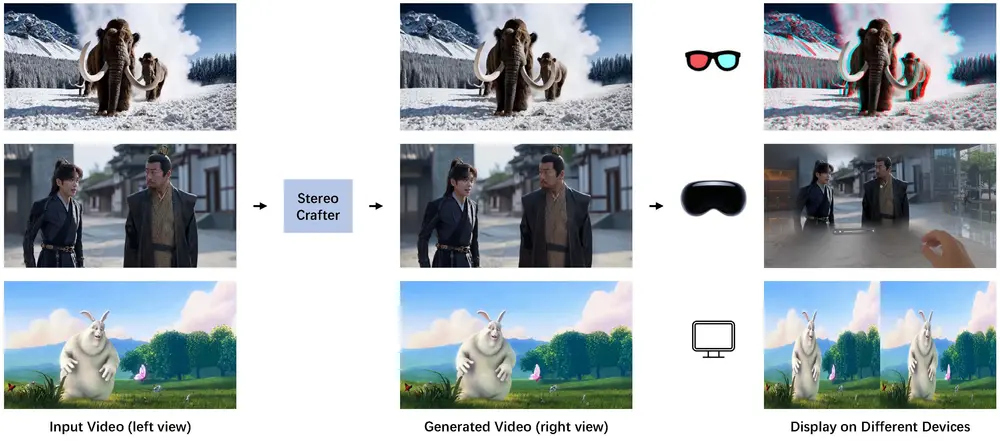
StereoCrafter框架:用于将单目(2D)视频转换为沉浸式立体 3D 视频,以满足人们对沉浸式数字体验的需求腾讯AI实验室和腾讯PCG ARC Lab的研究人员推出StereoCrafter框架,用于将单目视频转换为沉浸式立体 3D 视频,以满足人们对沉浸式数字体验的需求。该框架主要解决了传统 2D-to...新技术# StereoCrafter1年前06750
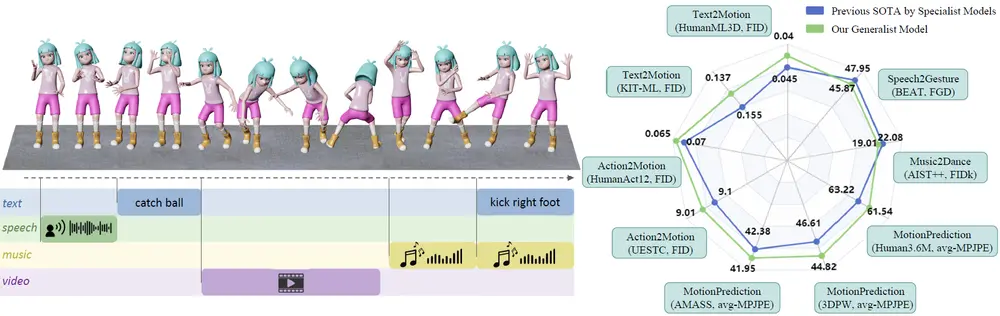
通用的多模态运动生成模型LMM:统一并简化动画和视频制作中的多种运动生成任务,如文本生成运动、音乐生成舞蹈等南洋理工大学和商汤科技的研究团队近期推出了一项革命性的技术——大运动模型(LMM),这是一个通用的多模态运动生成模型。LMM旨在统一并简化动画和视频制作中的多种运动生成任务,如文本生成运动、音乐生成舞...新技术# LMM# 多模态运动生成模型1年前03060
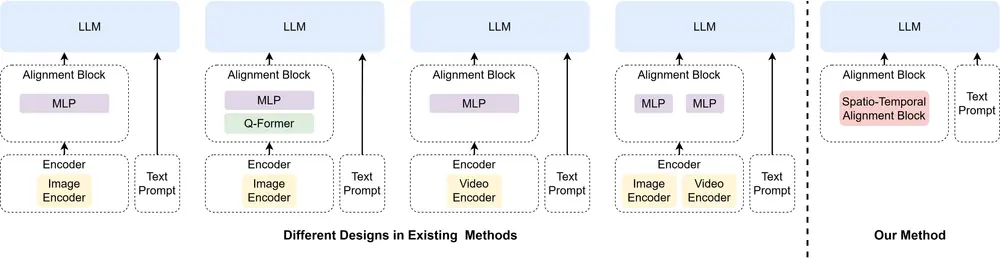
新型视频语言模型Video-Panda:无需编码器的新方法,用于理解和生成与视频内容相关联的语言描述波恩大学、拉马尔机器学习与人工智能研究所和哈利法大学的研究人员推出新型视频语言模型Video-Panda,这是一个无需编码器(encoder-free)的方法,用于理解和生成与视频内容相关联的语言描述...新技术# Video-Panda1年前03050
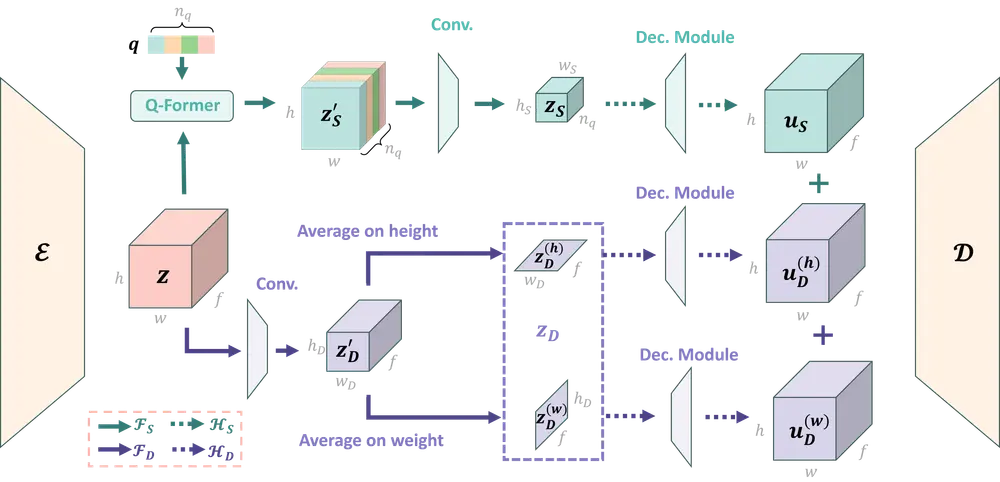
微软亚洲研究院推出新型视频自编码器VidTwin北京大学、微软亚洲研究院和香港中文大学(深圳)的研究人员推出一种新型视频自编码器(Video Autoencoder,简称Video AE),名为VidTwin。VidTwin的核心创新在于将视频分解...新技术# VidTwin# 视频自编码器1年前02970